
How to make sure that any developer can quickly throw in a solution to his problem and guaranteed to deliver it to production? Deploying the application is easy. Making it a full-fledged product so that a dozen teams use it on a hundred instances is more difficult. And if we are talking about a master system for several terabytes, then the level of anxiety rises, hands sweat, and the base is bursting at the seams (maybe).
I want to share a way to deploy without downtime and without denial of service. Jenkins pipeline, zero intermediaries, 500 instances in a production environment in 60 minutes. All this is in open source. For details I invite you under cat.
My name is Roman Proskin, I create and support high-load systems based on Tarantool at Mail.ru Group. I'll tell you how our team built a Tarantool application deployment, which updates the code in a production environment without downtime or denial of service. I will describe the problems that we encountered in the process, and what solutions we chose in the end. I hope our experience will be useful in building your deployment.
Deploying an application is easy. Tarantool has a cartridge-cli utility ( github). With it, the clustered application will be deployed somewhere in Docker in a couple of minutes. It is much more difficult to turn a solution out of the knee into a full-fledged product. It should easily handle hundreds of instances. At the same time, you need to be in demand in dozens of teams of different levels of training.
The idea behind our deployment is very simple:
- You take two iron servers.
- On each you launch one instance.
- Combine them into one set of replicas.
- You update one by one.
But when it comes to a master system with several terabytes of data, the level of anxiety rises, hands sweat, and the base is bursting at the seams (maybe).
Setting the initial conditions
The system has a strict SLA: it is necessary to ensure 99% availability, taking into account the planned work. This means that there are a total of 87 hours per year when we can afford not to respond to inquiries. It seems that 87 hours is a lot, but ...
The project is designed for a data volume of about 1.8 TB. Only restart will take 40 minutes! The update itself, if the changes are rolled manually, will add more from above. We make three updates per week: a total of 40 * 3 * 52/60 = 104 hours - SLA is violated . And these are only planned work without taking into account accidents that will certainly occur.
The application was developed for a high user load, which means it had to meet the stability requirements. In order not to lose data in the event of a node failure, we decided to geographically divide our cluster into two data centers. So we decided on a deployment mechanism that would not violate the SLA. Let the instances be updated not immediately, but in batches across data centers.
The load can be transferred to the second data center, then the cluster will be available for recording during the entire update. This is a classic shoulder deployment and one of the standard disaster recovery practices .
The ability to update across data centers is one of the key elements of a zero-downtime deployment. I will tell you more about the process at the end of the article, but for now I will dwell on the features of our inhuman deployment and the difficulties that we encountered.
Problems
We transfer traffic across the road
There are several data centers and requests can go to any of them. A trip to a nearby data center for data will increase the response time by 1-100 ms. To avoid cross traffic, we gave our data centers active and standby tags . The balancer (nginx) is configured so that traffic always flows to the active data center. If Tarantool crashes or becomes unavailable in the active data center, it automatically switches to the reserve.
Every user request is important, so you need a way to ensure that connections are maintained. To do this, we wrote a separate ansible playbook that switches traffic between data centers. Switching is implemented using a directive
backup
in the description
upstream
for the server. The upstreams are selected by the limit, which will become active. The rest is prescribed
backup
: nginx will let traffic on them only if all active ones are unavailable. When changing the configuration, open connections are not closed, and new requests will go to routers that are not subject to restart.
What can be done if the infrastructure does not have an external load balancer? Write your own mini-balancer in Java that will monitor the availability of Tarantool instances. But this separate subsystem will also require its own deployment. Another option is to build a switching mechanism inside the routers. One thing remains unchanged: HTTP traffic must be controlled.
We sorted it out with nginx, but the problems did not end there. Switching must be done for masters in replica sets as well. As I mentioned, the data must be kept close to the routers to avoid unnecessary network trips. Moreover, when the current master (that is, a storage instance with write access) crashes, the failover mechanism does not work immediately. While the cluster makes a general decision about the unavailability of the instance, all requests to the affected piece of data will be erroneous. To solve this problem, we also needed to compile a playbook, where we used GraphQL queries to the cluster API.
Mechanisms for changing wizards and switching user traffic are the last key elements of a no-downtime deployment. A controlled load balancer avoids loss of connections and errors in the processing of user requests, and changing masters - errors with data access. Together with the update on the shoulders of these three pillars, a fault-tolerant deployment is obtained, which we further automated.
Fighting legacy
The customer already had a ready-made rollout mechanism: roles that deployed and configured instances step by step. Then we came with the magic ansible-cartridge ( github) that will solve all problems. We did not take into account only that the ansible-cartridge itself is a monolith - one large role, the different stages of which are separated by labels and separate tasks. To fully use it, it was necessary to change the process of delivering the artifact, revise the directory structure on the target machines, change the orchestrator, and much more. I spent a month refining the deployment using ansible-cartridge. The monolithic role just didn't fit into the finished playbooks. It didn't work out in this form, and I was stopped by a just question from a colleague: "Do we need it?"
We did not give up - we separated the cluster configuration from a single piece, namely:
- combining storage instances into replica sets;
- bootstrap vshard (cluster data sharding mechanism);
- setting up failover (automatic switching of masters in case of a fall).
These are the final stages of deployment, when all instances are up and running. Unfortunately, all the other steps had to be left as they are.
Choosing an orchestrator
Code on servers is useless if it can't be run. We need a utility to start and stop Tarantool instances. The ansible-cartridge contains tasks for creating systemctl service files and working with rpm packages. But the specificity of our task was the presence of a closed circuit at the customer and the absence of sudo privileges. This means that we could not use systemctl.
Soon we found an orchestrator that does not require permanent root privileges - supervisord... I had to first install it on all servers, and also solve local problems with access to the socket file. A new ansible role has appeared to work with supervisord: it includes tasks for creating configuration files, updating the config, starting and stopping instances. That was enough to get it into production.
For the sake of experiment, we added the ability to run an application using supervisord in ansible-cartridge. This method turned out to be less flexible and is still awaiting completion in a separate branch.
Reducing loading times
Whichever orchestrator we use, we cannot wait an hour for the instance to launch. The threshold is 20 minutes. If the instance is unavailable longer than this threshold, then an automatic crash will be triggered and recorded in the accounting system. Frequent accidents affect the key performance of teams and can undermine plans for the development of the system. I do not want to lose the premium at all because of the banally necessary deployment. By all means, you need to keep within 20 minutes.
Fact: The download time directly depends on the amount of data. The more you need to raise from the logs to RAM, the longer the instance starts after the update. You also need to take into account that storage instances on the same machine will compete for resources: Tarantool uses all processor cores to build indexes.
Based on our observations, the size
memtx_memory
per instance should not exceed 40 GB. This value is optimal for instance recovery to take less than 20 minutes. The number of instances on one server is calculated separately and is closely related to the project infrastructure.
We connect monitoring
Any system needs to be monitored, and Tarantool is no exception. Our monitoring did not appear immediately. A whole block was spent on obtaining the necessary access, approval and setting up the environment.
In the process of developing the application and writing playbooks, we slightly modified the metrics module ( github ). Now you can divide the metrics by the name of the instance from which they flew - made global labels. As a result of integration with monitoring systems, a whole role has emerged for cluster applications. The new type of quantile metrics also emerged from the generalization of the requirements for our system.
Now we see the current number of requests to the system, the size of the memory used, the replication lag and many other key metrics. Additionally, they are configured with notifications in chats. The most critical problems fall into the general system of car accidents and have a clear SLA for elimination.
A little about the tools. A detailed description of where, what and how to get it is collected in etcd , from where the telegraf agent receives its instructions. JSON-formatted metrics are stored in InfluxDB . We used Grafana as a visualizer , for which we even wrote a template dashboard . And finally, alerts are configured through kapacitor .
Of course, this is far from the only option for implementing monitoring. You can use Prometheus , and metrics just knows how to give values in the required format. For alerts, zabbix can also come in handy , for example.
My colleague told me more about setting up monitoring for Tarantool in the article “ Monitoring Tarantool: Logs, Metrics and Their Processing ”.
Setting up logging
You cannot limit yourself to monitoring. To get a complete picture of what is happening with the system, all diagnostics should be collected, and this also includes logs. Moreover, the higher the logging level, the more debugging information and the larger the log files.
Disk space is not infinite. Our application could generate up to 1TB of logs per day at peak load. In such a situation, you can add disks, but sooner or later either free space or the project budget will run out. But you don't want to lose debugging information without a trace either! What to do?
One of the stages of deployment, we added the logrotate setting : keep a couple of 100MB files raw and compress a couple more. In normal operation, this is enough to find a local problem within 24 hours. Logs are stored in a strictly defined directory in JSON format. All servers run the filebeat daemon , which collects application logs and sends them for long-term storage to ElasticSearch . This approach saves you from disk overflow errors and allows you to analyze system performance in case of long-term problems. This approach also fits well into the deployment.
We scale the solution
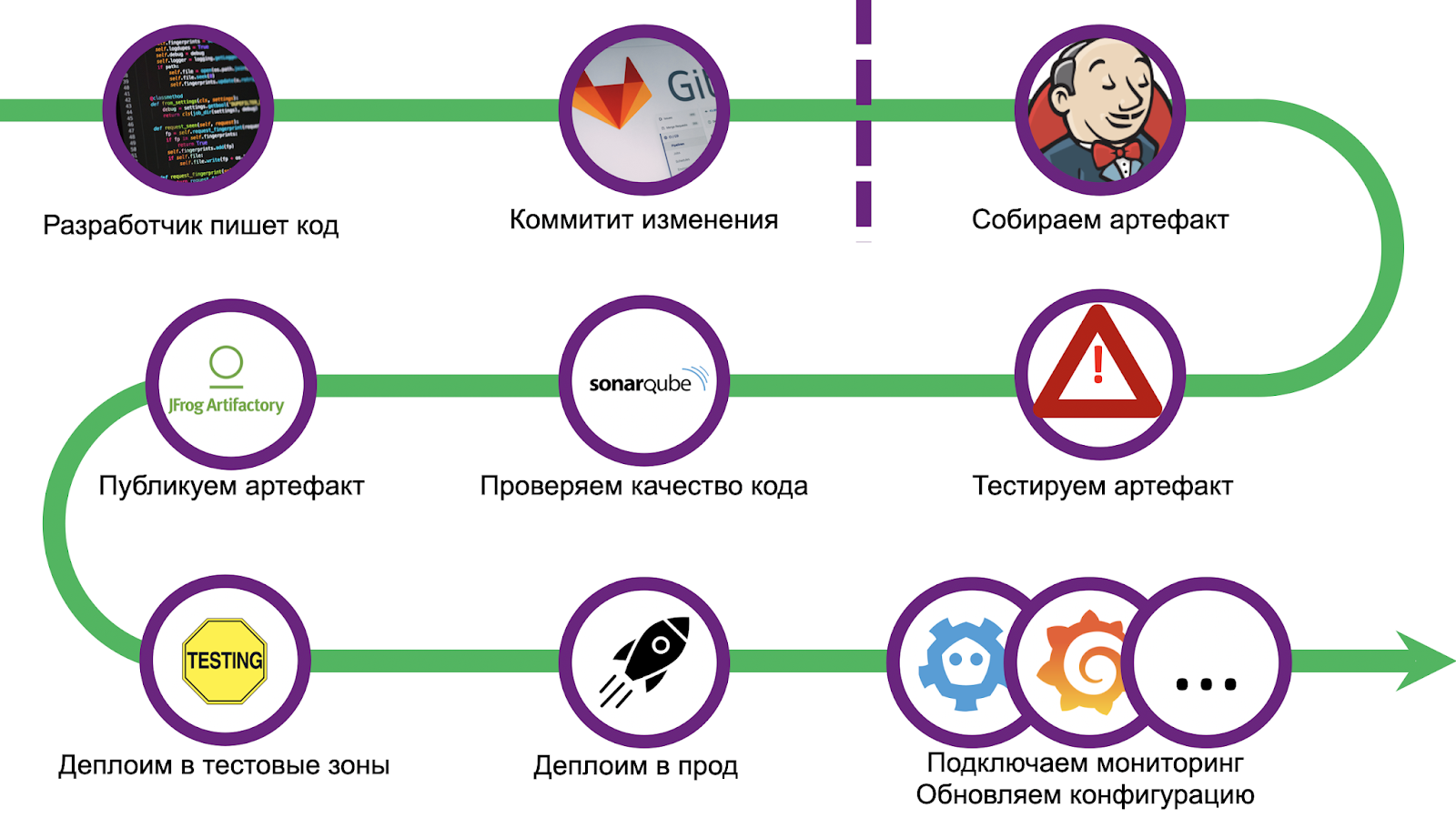
The path was long and thorny, we got a decent amount of cones. In order not to repeat mistakes, we standardized the deployment and used the CI / CD bundle - Gitlab + Jenkins. Scaling also caused a number of problems, debugging the solution took more than one month. But we have coped, and now we are ready to share our experience with you. Let's walk through the steps.
How to make sure that any developer can quickly throw in a solution to his problem and guaranteed to deliver it to production? Take away Jenkinsfile from him! It is necessary to outline bold boundaries, going beyond which means the impossibility of deployment, and direct the developer along this path.
We made a full-fledged sample application, which was rolled out in the same way and which is an exhaustive starting point. But we went even further with the customer: we wrote a utility for automatically creating a template that sets up a git repository and Jenkins tasks. The developer will need less than an hour for everything about everything, and the project will be in production.
The pipeline starts with a standard code check and environment setup. Additionally, we put inventory for subsequent deployment in several functional test zones and prod. Then comes the unit test phase.
The standard Tarantool test framework luatest ( github). You can write both unit and integration tests in it, there are auxiliary modules for running and configuring Tarantool Cartridge . You can also enable coverage in recent versions . We start it with a simple command:
.rocks/bin/luatest --coverage
At the end of the tests, the collected statistics are sent to SonarQube - software for evaluating the quality and safety of the code. Inside, we have already configured the Quality Gate. Any code in the application, regardless of the language (Lua, Python, SQL, etc.), is validated. However, there is no built-in handler for Lua, so to represent coverage in generic format, we have plugins that are installed before the tests begin.
tarantoolctl rocks install luacov 0.13.0-1 # coverage
tarantoolctl rocks install luacov-reporters 0.1.0-1 #
A simple console version can be viewed like this:
.rocks/bin/luacov -r summary . && cat ./luacov.report.out
The report for SonarQube is generated by the command:
.rocks/bin/luacov -r sonar
After coverage comes the linter stage. We are using luacheck ( github ), which is also one of the Tarantool plugins.
tarantoolctl rocks install luacheck 0.26.0-1
Linter results are also sent to SonarQube:
.rocks/bin/luacheck --config .luacheckrc --formatter sonar *.lua
Code coverage statistics and linters are counted together. To pass the Quality Gate, all conditions must be met:
- code coverage by tests must be at least 80%;
- changes should not introduce new odors;
- the total number of critical problems is 0;
- the total number of non-critical stocks is less than 5.
After passing the Quality Gate, you need to bake the artifact. Since we decided that all applications will use Tarantool Cartridge, we use cartridge-cli ( github ) for building . This is a small utility for running (in fact, developing) clustered Tarantool applications locally. She also knows how to create Docker images and archives with application code, both locally and in Docker (for example, if you need to build an artifact for a different architecture). The assembly
tar.gz
is performed by the command:
cartridge pack tgz --name <nme> --version <vrsion>
The resulting archive is then uploaded to any repository, for example, to Artifactory or Mail.ru Cloud Storage .
Deploy without downtime
And the final step of the pipeline is the deployment itself. Depending on the state of the edits, rolling is performed into different test zones. One zone is allocated for any sneeze: each push to the repository launches the entire pipeline. There are also several functional areas where you can test interaction with external systems, for this you need to create a merge request in the master branch of the repository. But in production, rolling is launched only after the changes are accepted and the merge button is pressed.
Let me remind you the key elements of our deployment without downtime:
- update for data centers;
- switching masters in replica sets;
- setting up the balancer for an active data center.
When upgrading, you need to monitor the compatibility of versions and data schema. The update will stop if an error occurs at any of the steps.
The update can be schematically represented as follows:
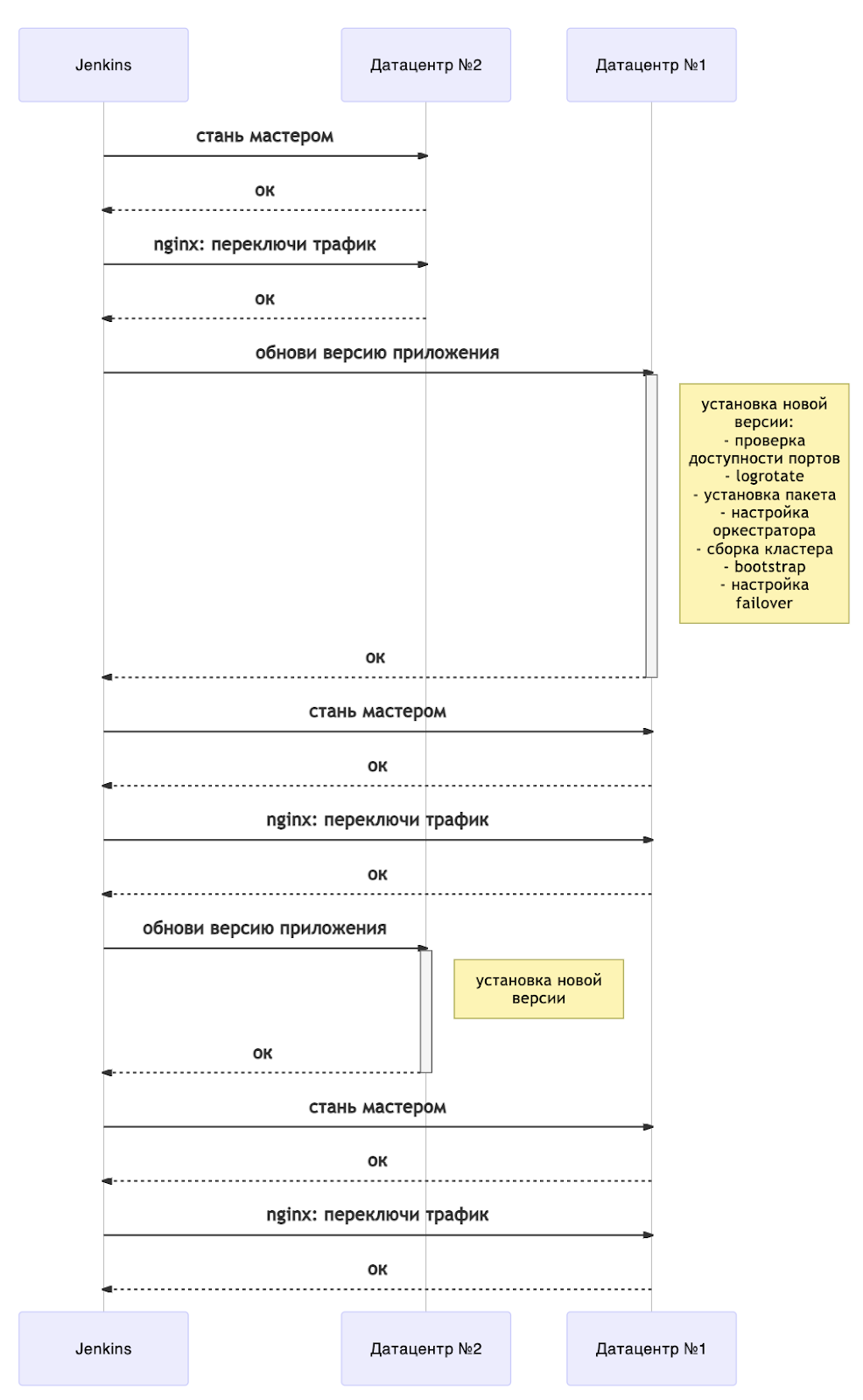
Now any update is accompanied by a server restart. To understand when you can continue deploying, we have a separate playbook of waiting for the state of instances. Tarantool Cartridge has a state machine, and we are waiting for the RolesConfigured state , which means that the instance is fully configured (and for us, it is ready to accept requests). If the application is deployed for the first time, then you need to wait for the Unconfigured state .
Overall, the diagram shows an overview of a deployment without downtime. It easily scales to more data centers. Depending on your needs, you can update all the backup "arms" immediately after changing the masters (that is, together with the data center # 1) or one by one.
Of course, we could not help but bring our developments to open source. So far, they are available in my ansible-cartridge fork ( opomuc / ansible-cartridge ), but there are plans to move this to the master branch of the main repository.
An example can be found here ( example ). For it to work correctly, the server must be configured
supervisord
for the user
tarantool
. The configuration commands can be found here . The archive with the application must also contain a binar
tarantool
.
The sequence of commands to start the shoulder deployment:
# ( )
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.0.0-0.tar.gz' \
--extra-vars 'app_version=1.0.0' \
--tags supervisor
# 1.2.0
# dc2
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc2
# — dc1
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc1
# dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
# — dc2
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc2
# , dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
The parameter
base_dir
indicates the path to the "home" directory of the project. After rolling out, subdirectories will be created:
<base_dir>/run
- for control sockets and pid files;<base_dir>/data
- for .snap and .xlog files, as well as Tarantool Cartridge configuration;<base_dir>/conf
- for application settings and specific instances;<base_dir>/releases
- for versioning and source code;<base_dir>/instances
- for links to the current version for each instance of the application.
The parameter
cartridge_package_path
speaks for itself, but there is a peculiarity:
- if the path starts with
http://
orhttps://
, then the artifact will be preloaded from the network (for example, from the artifactory raised next to it). - in other cases, the file is searched locally
The parameter
app_version
will be used for versioning in the folder
<base_dir>/releases
. The default is
latest
.
The tag
supervisor
means that it will be used as an orchestrator
supervisord
.
There are many options for starting a deployment, but the most reliable is the good old one
Makefile
. The conditional command
make deploy
can be included in any CI \ CD and everything will work exactly the same.
Outcome
That's all! We now have a ready-made pipeline on Jenkins, we got rid of middlemen, and the speed of delivery of changes has become insane. The number of users is growing, in the production environment there are already 500 instances deployed exclusively using our solution. We have room to grow.
And although the deployment process itself is far from ideal, it provides a solid foundation for the further development of DevOps processes. You can safely take our implementation in order to quickly deliver the system to production and not be afraid to make frequent edits.
And it will also be a lesson for us that you cannot bring a monolith and hope for its widespread use: you need a decomposition of playbooks, the allocation of roles for each stage of the installation, a flexible way of presenting inventory. Someday our developments will be included in master, and everything will be even better!
Links
- A step-by-step guide for ansible-cartridge:
- You can read about Tarantool Cartridge here .
- About deploying to Kubernetes:
- Tarantool monitoring: logs, metrics and their processing .
- For help, contact the Telegram chat .