
Hello. Let me tell you about my experience in evaluating software products. I have been doing this without interruption for 15 years now, and I would like to share my experience and the evolution of my views on assessment. I am sure it will be useful. Let's start with goal setting. Why measure at all? Who needs it?
The answer is actually very simple - people want certainty, in particular the answer to the question "when will it be ready?" When can I go on vacation, when sales start, when to do a related task. On the other hand - you never know what people want, why because of other people's desires to waste their time on this activity?
But, ultimately, we all would like to receive a salary, and the salary does not appear out of thin air, the company takes it from the proceeds, in a separate case - from investments. And in order for this very revenue to be, we need to achieve a business goal. And people who formulate business goals are very fond of all sorts of financial formulas - ROI, LTV and other EBITDA. And these formulas constantly feature deadlines. Without them, the crocodile is not caught, the coconut does not grow.
There is also a second reason, slightly less important: if the estimates for features are clear, then this affects their priority, simpler tasks tend to receive higher priority. Since in the conventional agile approach, the backlog is regularly shaken up, the input information about the task ratings helps to make the reprioritization process more efficient.
As a consequence: most likely, you still have to evaluate. Humble yourself .
Now let's talk about how to do this, so as not to curse everything and everyone in the process. How do people who do not know how to evaluate IT stuff usually rate? Like this:
- We evaluate all work in person days.
- Add 10% just in case.
- Divide by the number of developers.
- We add the resulting number of days to the current date and get the final date.
- That's all.
Because of this, the Vietnamese flashbacks from the title picture are still flashing before my eyes: too many of my nerves died in this war. And it will die for you if you start to evaluate this way. The problem is that this is exactly the kind of assessment that is expected from you:
“You don’t play out with your storypoints, show your hand.”
What challenges to face during the assessment
Let's start with an ideal situation:
- We have an atomic (simple, indivisible) task.
- It has no dependencies on other tasks, there is no need to coordinate anything.
- There is a 100% dedicated person for the task who knows how to do it.
Even in this case, the question arises "Who will make the assessment?" At this moment, the unforgiving control machine starts. First, the manager thinks: if the developer is going to do this, what will prevent him from specifying the huge labor costs to fool around? -> Therefore, the manager evaluates the task himself. -> However, the manager does not understand the topic deeply enough and does not see (or does not want to see) the pitfalls. -> The estimate turns out to be irreparably underestimated. -> The team does not meet the deadline. -> Death and decay.

The situation described above is a classic corporate culture problem of mistrust of its employees. However, most developers have an intrinsic motivation to solve interesting problems, for them it is much more attractive than playing the fool at the computer, so there is no reason for widespread distrust. In general, a company should be built on the basis of the presumption of trust in its employees, and not twist normal business processes to look like black sheep.
A culture of distrust is very common in conjunction with a corporate culture of fear: even if a developer is evaluating a task, what happens in his head during the evaluation? He answers the question: "How does my company react to the discrepancy between the planned and actual dates?" If the developer is scolded for the failed deadlines, he will overestimate them. If the developer's further assessments are cut off for the tasks made ahead of time, he will not hand over the tasks in advance.
The newest example of a culture of fear is the release of Cyberpunk 2077. The game was released in disgusting quality on previous generation consoles. The CEO of the company said in a statement that "as it turns out, many of the issues that you encountered in the game were not found during testing." Which, of course, is a total lie. The problems were visible to the naked eye, the testers physically could not miss this. This is a typical situation in a culture of fear: problems are hushed up. So the information along the way to the top floor of management went from “game not playable on base consoles” to “let's release”.
If this is not your case, then you can evaluate further. If you are unlucky with the culture in the company, do not read further, because you need to issue assessments not for accuracy, but to minimize kicks from the authorities, and this is a completely different task.
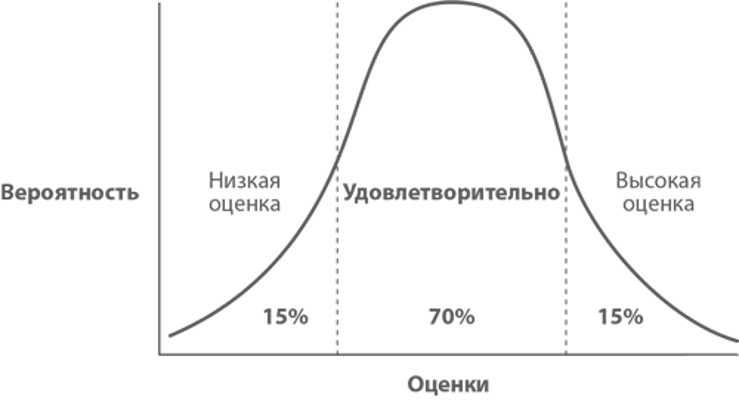
And so you gave an estimate, for example - 1 week. This is just your guess, nothing more. Evaluation determines the planned completion date of a task, but cannot determine when it will actually complete. Where exactly the actual time of completion of the task will be is described by a normal distribution. For now, let's just remember this as an axiom, at the end there will be a plot twist.
Everything is further complicated by the fact that some tasks are not fundamentally divided into parts, and it also happens that they cannot be parallelized. There are also interdependent tasks, you need to dive into the context of tasks. Plus, when developing, the team needs to communicate in order to synchronize their activities.
We also don't know how to see the future. As a result, tasks constantly arise that we did not foresee, and could not foresee. What could it be?
- Customer wishes or Product Owner.
- Sudden problems for which you need to modify something.
- Unexpected legal.
- And tons of stuff.
The most unpredictable is the problem of different speed of developers.
For real developers of the same level and with the same salary, productivity may differ by an order of magnitude:
- Someone will cut and debug the code for a week, and someone will screw the open library in half a day.
- Someone will smoke Stack overflow, and someone has already solved such problems and will immediately begin to benefit.
As a result, our Gaussian turns into something like this (the estimate looks the same when the task is not sufficiently sized):

In general, everything is complicated, we are not digging trenches here. How can you make a good grade in such conditions?
Good grade criteria:
- High speed of assessment - the assessment itself does not carry any business value, so it is logical to do it as quickly as possible so as not to be distracted from the development.
- Evaluation is the responsibility of the entire team, and there is a good “you rate, you do it” principle that protects the team from ceiling marks.
- Do not forget about all the components of the output of a feature in production - analytics, development, unit tests, autotests, integration tests, devops. All this must be evaluated.
As you can see, I haven't written anything about accuracy. During the 15 years that I have been making estimates, I have not learned how to make them accurately, so let's be more modest and try to estimate at least approximately. The whole assessment process looks like this:
- Putting tasks into the product backlog.
- We evaluate the highest priority stories in the backlog using any method (there are many methods, I will tell about them below).
- We start to work (for example, on Scrum - by sprints).
- After several sprints, we measure how many story points we get on average each iteration. This is our Velocity - average team development speed.
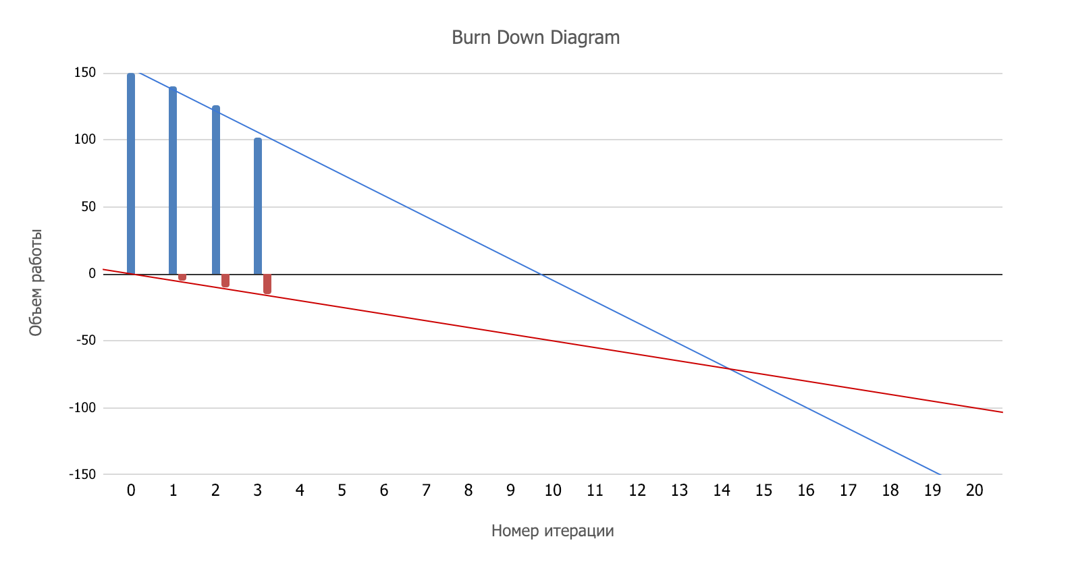
- . burndown chart. , .

But the world is not perfect, so we fix how many new features (also estimated in storypoints) our Product Owner generates each sprint. The red line will show the growth of the backlog, now the intersection of the red and blue lines is the desired date.
If the Product Owner is very creative, then it may even be like this:

And now we remember that the assessment obeys the laws of normal distribution, but the plot twist - such Gaussians add up perfectly. Therefore, this is what turns out (this is called the enchanced burndown chart):
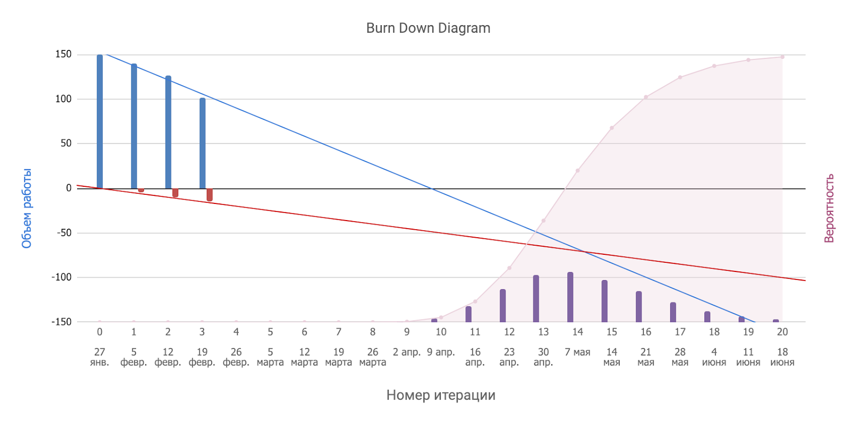
It would seem that the dream of the young mathematician has come true: from the heap of chaos we got a beautiful graph and can intelligently broadcast that “with 50% probability we will finish in sprint 14, with 80% probability - in the 17th, from 95% - in the 19th ".
There are a number of pitfalls in this entire process.
Firstly, I will immediately say about the elephant in the room: the backlog is large, there are a lot of tasks about which nothing is known except the description in the user story format, so the estimate will be very approximate in any case. I have already shown above how a rough estimate looks in the language of mathematics.
Secondly, the problem "developers work with different productivity" is not solved in any way in principle... This means that we get a very flat increase in probability, which does not help much to make managerial decisions: “with a 50% probability we will finish in the 14th sprint, with an 80% probability - in the 27th, with 95% - in the 39th” - so in the language of mathematics, it sounds "a finger to the sky."
Therefore, I personally maximize the "rate of assessment" metric and now I will tell you the methods that I tried.
Planning poker method
This is one of the most popular assessment techniques, probably because it is the oldest.
- Participants in the process use cards specially numbered with Fibonacci numbers.
- Product Owner makes a short announcement of the next story and answers questions from the team.
- After receiving the information, the participants of the "poker" choose a card with a suitable, in their opinion, assessment and do not show it to anyone.
- Then all are revealed together, and the participants with the lowest and highest scores give short comments explaining their choice of score.
- As a result of the discussion process, the team comes to a single decision, and then moves on to the next story.
During an hour session in this way, you can evaluate from 4 to 8 stories. This is the biggest problem with this method - it is long, people get bored and distracted. It was not for nothing that I used the phrase "all are revealed together."
The "building order" method
This is the approach we are currently using at work. The point is to evaluate tasks relative to each other. This is how a sequence of tasks sorted by difficulty is built. For this method, you must first accumulate a pool of evaluated tasks and place them on the scale.
- When it's time to evaluate, each team member takes turns making their move (like in a board game). The moves can be as follows: put the task on the scale, move the task along the scale, discuss the story with colleagues, skip your move.
- As a result, tasks are constantly moving around the board, their assessment relative to each other is refined until a state is obtained that satisfies the entire team.
- When all participants miss their turn, you're done.
This is a fast technique. With its help, you can estimate 15-20 stories per hour, which is usually quite enough.
Big / small / obscure method
I have used it several times, but it did not take root.
- Three zones are marked on the board: "large task", "small task" and "insufficient information".
- , «/». « » = « ».
- .
The method has a huge plus - it's super fast. So you can process 50 user stories per hour.
Here there is a problem with translating these estimates into story points, but when the velocity of the team is already known, then we understand how many storypoints a person will chew per sprint in Jira and evaluate small tasks around this metric.
As for the rest of the tasks. I sent tasks from the "insufficient information" area to analytics, and tasks from the "large task" - to decomposition, so that they could be re-evaluated at the next session.
As a result, in our product we simply draw a roadmap with features that we think we will have time to write in the near future. If we do not have time - well, it happens. And we use estimates only for the immediate tasks, which we have normalized, and even then, not always.
Perhaps I am engaged in throwing my incompetence in the field of assessment in pseudo-scientific terms, but for me personally, the process itself looks rather dumb, like a strange cargo cult that we play in order to pretend that we are the same stable and predictable industry. like some other really stable and predictable industry. I would love to read about your experience in this area, maybe I'm missing something.