
Hello, Habr! More recently, we wrote about an open dataset assembled by a team of Data Science graduate students from NUST MISIS and Zavtra.Online (SkillFactory's university department) as part of the first educational Dataton. And today we will present you as many as 3 datasets from teams that also reached the final.
They are all different: some have researched the music market, some have researched the labor market of IT specialists, and some have studied domestic cats. Each of these projects is relevant in its own area and can be used to improve something in the usual course of work. A dataset with cats, for example, will help judges at exhibitions. The datasets that students had to collect had to be MVP (table, json or directory structure), the data had to be cleaned up and analyzed. Let's see what they did.
Dataset 1: Glide on musical waves with Data Surfers
Line-up:
- Kirill Plotnikov - project manager, development, documentation.
- Dmitry Tarasov - development, data collection, documentation.
- Shadrin Yaroslav - development, data collection.
- Merzlikin Artyom - product manager, presentation.
- Ksenia Kolesnichenko - preliminary data analysis.
As part of their participation in the hackathon, the team members proposed several different interesting ideas, but we decided to focus on collecting data on Russian music artists and their best tracks from Spotify and MusicBrainz.
Spotify is a music platform that came to Russia not so long ago, but is already actively gaining popularity in the market. In addition, in terms of data analysis, Spotify provides a very convenient API with the ability to query a large amount of data, including their own metrics, such as "danceability" - a score from 0 to 1 that describes how good a track is for dancing.
MusicBrainzIs a musical encyclopedia containing the most complete information about existing and existing musical groups. A kind of "musical wikipedia". We needed data from this resource in order to get a list of all performers from Russia.
Collecting artist data
We have compiled a whole table containing 14363 unique entries for various artists. To make it convenient to navigate in it, there is a description of the table fields under the spoiler.
Description of table fields
artist – ;
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .

Example of Record
Fields artist, musicbrainz_id and type are retrieved from the Musicbrainz music database, since there is an opportunity to get a list of artists associated with one country. There are two ways to retrieve this data:
- Parse the Artists section on the page with information about Russia.
- Get data via API. MusicBrainz API
Documentation MusicBrainz API
Documentation Search
Example GET Request on musicbrainz.org
In the course of work, it turned out that the MusicBrainz API does not quite correctly respond to a request with the Area: Russia parameter, hiding from us those artists who have an Area specified, for example, Izhevsk or Moskva. Therefore, the data from MusicBrainz was taken by the parser directly from the site. Below is an example of the page from where the data was parsed.
The obtained data about the artists of Musicbrainz.
The rest of the fields are obtained as a result of GET requests to the endpoint . When sending a request, specify the artist's name in the value of the q parameter, and specify artist in the value of the type parameter.
Collecting data about popular tracks
The table contains 44473 records of the most popular tracks by Russian artists, presented in the table above. Under the spoiler there is a description of the table fields.
Description of table fields
artist – ;
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
Audio Features
key – , , 0 = C, 1 = C♯/D♭, 2 = D ..;
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
You can read more about each parameter here .

An example of a record The
fields name, spotify_id, duration_ms, explicit, popularity, album_type, album_name, album_spotify_id, release_date are obtained using a GET request for
https://api.spotify.com/v1//v1/artists/{id}/top-tracks
, specifying as the value of the Spotify id parameter the artist ID that we received earlier, and in the value of the market parameter we specify RU. Documentation .
The album_popularity field can be obtained by making a GET request for
https://api.spotify.com/v1/albums/{id}
, specifying the album_spotify_id obtained earlier as the value for the id parameter. Documentation .
As a result, we get the dataabout the best tracks from Spotify artists. Now the challenge is to get the audio features. This can be done in two ways:
- To get data about one track, you need to make a GET request for
https://api.spotify.com/v1/audio-features/{id}
, specifying its Spotify ID as the value of the id parameter. Documentation .
- To get data about several tracks at once, you should send a GET request to
https://api.spotify.com/v1/audio-features
, passing Spotify IDs of these tracks separated by commas as the value for the ids parameter. Documentation .
All scripts are in the repository at this link .
After collecting the data, we conducted a preliminary analysis, which is visualized below.
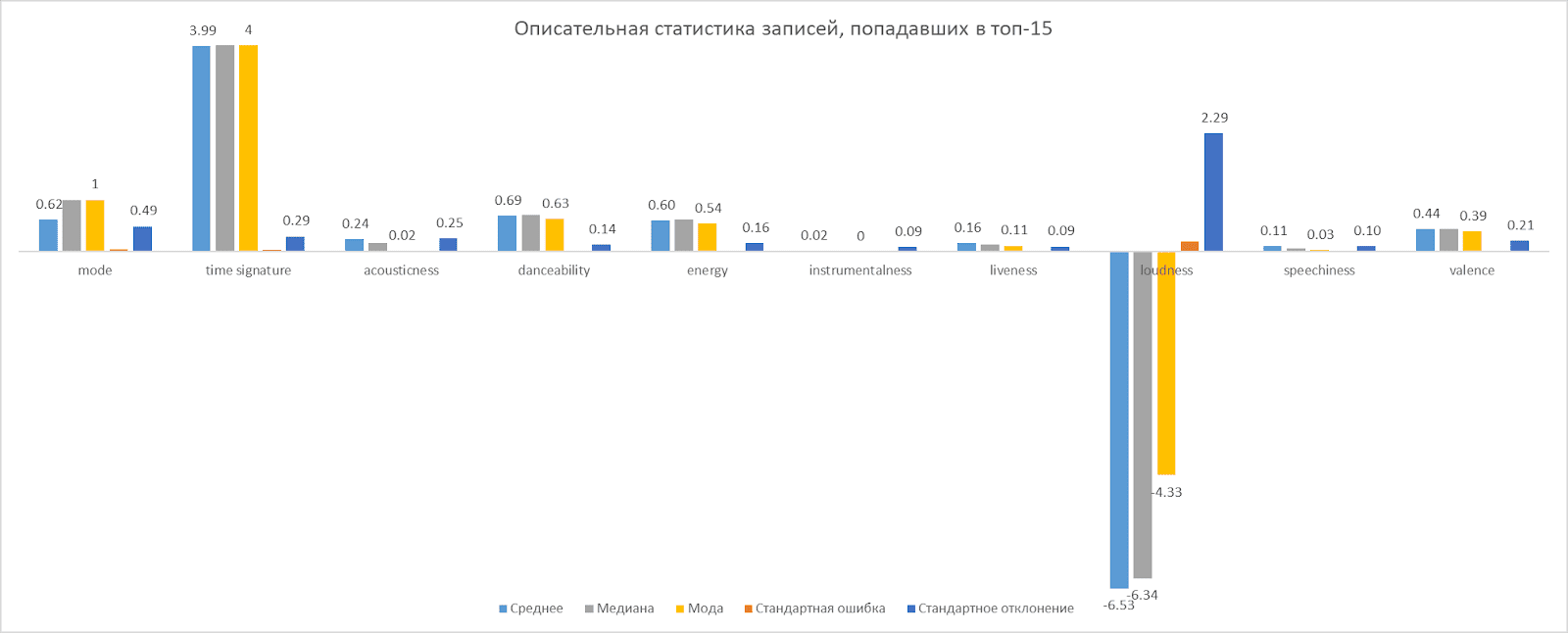
Outcome
As a result, we managed to collect data on 14363 artists and 44473 tracks. By combining data from MusicBrainz and Spotify, we have obtained the most complete dataset to date of all Russian music artists represented on the Spotify platform.
Such a dataset will allow creating B2B and B2C products in the music field. For example, systems for recommending performers who can be organized for promoters, or systems for helping young performers write tracks that are more likely to become popular. Also, with regular replenishment of the dataset with fresh data, you can analyze various trends in the music industry, such as the formation and growth of popularity of certain trends in music, or analyze individual performers. The dataset itself can be viewed on GitHub .
Dataset 2: We research the job market and identify key skills with "Hedgehog is clear"
Line-up:
- Andrey Pshenichny - collecting and processing data, writing an analytical note on the dataset.
- Pavel Kondratenok - Product Manager, data collection and description of its process, GitHub.
- Svetlana Shcherbakova - data collection and processing.
- Evseeva Oksana - preparation of the final presentation of the project.
- Elfimova Anna - Project Manager.
For our dataset, we chose the idea of collecting data on vacancies in Russia from the IT and Telecom sphere from the site hh.ru for October 2020.
Skill data collection
The most important metric for all user categories is Key Skills. However, when analyzing them, we encountered difficulties: when filling out vacancy data, HRs select key skills from the list, and can also enter them manually, and therefore, a large number of duplicate skills and incorrect skills got into our dataset (for example, we encountered the name of the key skill "0.4 Kb"). There is one more difficulty that caused problems when analyzing the resulting dataset - only about half of the vacancies contain data on salaries, but we can use average salary indicators from another resource (for example, from the resources My Circle or Habr.Career).
We started with data acquisition and in-depth analysis. Next, we sampled the data, that is, we selected features (features or, in other words, predictors) and objects, taking into account their relevance for the purposes of Data Mining, quality and technical constraints (volume and type).
Here we were helped by an analysis of the frequency of mentioning skills in the tags of required skills in the job description, what characteristics of the vacancy affect the proposed reward. At the same time, 8915 key skills were identified. Below is a chart showing the top 10 key skills and how often they are mentioned.
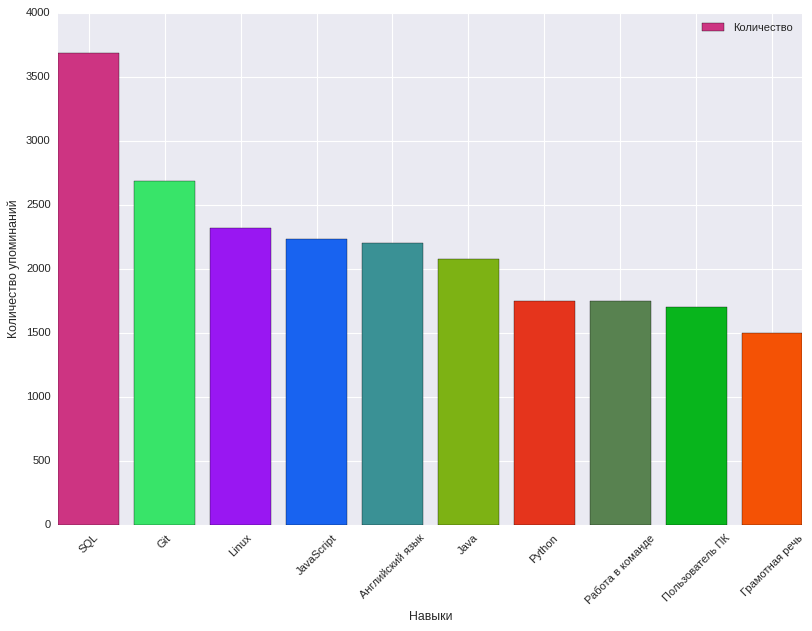
The most common key skills in IT vacancies, Telecom
Data were obtained from the hh.ru website using their API. The code for uploading data can be found here . We have manually selected the features that we need for the dataset. The structure and type of collected data can be seen in the description of the documentation for the dataset.
After these manipulations, we got a Dataset with a size of 34,513 lines. You can see a sample of the collected data below, and also find the link .

Sample data collected
Outcome
The result is a dataset with which you can find out what skills are most in demand among IT specialists in different areas, and it can be useful for job seekers (both beginners and experienced), employers, hr-specialists, educational organizations and organizers of conferences. In the process of collecting data, there were also difficulties: there are too many signs and they are written in a low-formalized language (description of skills for the candidate), half of the vacancies do not have open data on salaries. The dataset itself can be viewed on GitHub .
Dataset 3: Enjoy the variety of cats with "Team AA"
Line-up:
- Evgeny Ivanov - web scraping development.
- Sergey Gurylev - product manager, development process description, GitHub.
- Yulia Cherganova - preparation of project presentation, data analysis.
- Elena Tereshchenko - data preparation, data analysis.
- Yuri Kotelenko - project manager, documentation, project presentation.
A dataset dedicated to cats? Why not, we thought. Our catset contains sample images of cats of various breeds.
Collecting cat data
Initially, we chose catfishes.ru to collect data , it has all the advantages we need: it is a free source with a simple HTML structure and high-quality images. Despite the advantages of this site, it had a significant drawback - a small number of photos in general (about 500 for all breeds) and a small number of images of each breed. Therefore, we chose another site - lapkins.ru .

Because of the slightly more complex HTML structure, scraping the second site was a little more difficult than the first, but the HTML structure was easy to figure out. As a result, we managed to collect already 2600 photos of all breeds from the second site.
We didn't even need to filter the data, since the photos of the cats on the site are of good quality and correspond to the breeds.
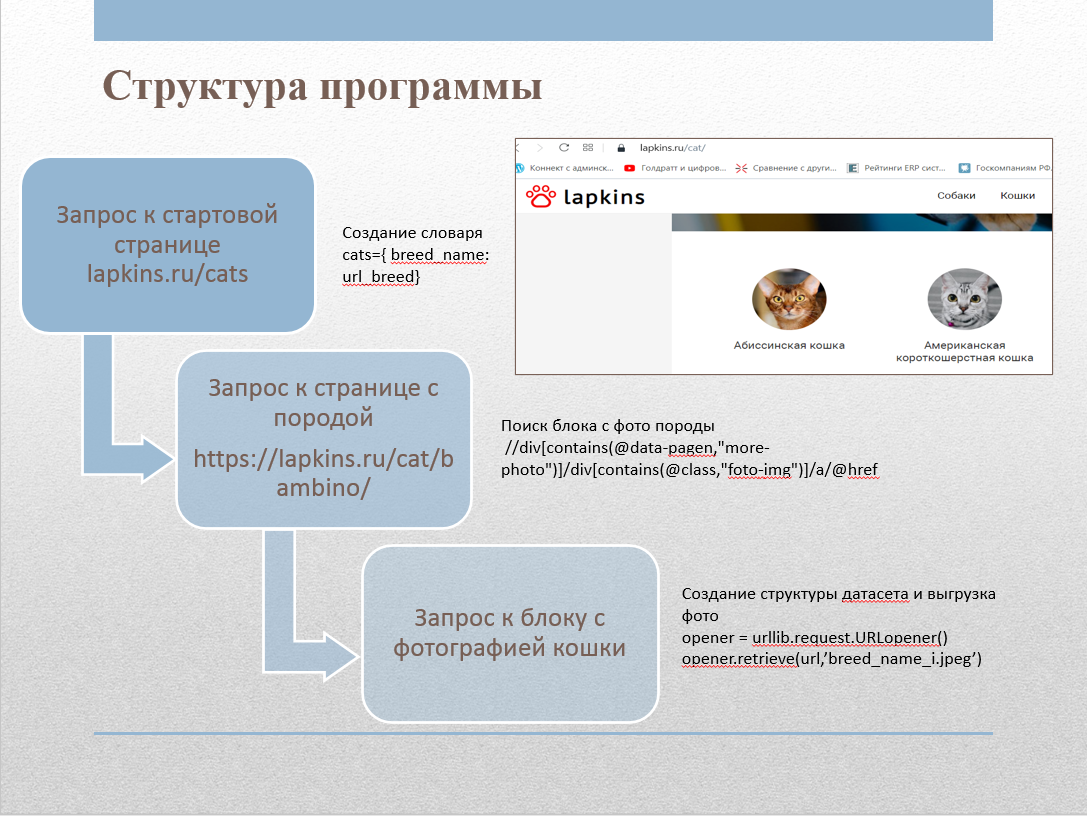
To collect images from the site, we wrote a web scraper. The site contains a page lapkins.ru/cat with a list of all breeds. After parsing this page, we got the names of all breeds and links to the page for each breed. Having iteratively looped through each of the rocks, we got all the images and put them in the appropriate folders. The scraper code was implemented in Python using the following libraries:
- urllib : functions for working with URLs;
- html : functions for processing XML and HTML;
- Shutil : high-level functions for handling files, groups of files and folders;
- OS : functions for working with the operating system.
We used XPath to work with tags.
The Cats_lapkins directory contains folders whose names correspond to the names of cat breeds. The repository contains 64 directories for each breed. In total, the dataset contains 2600 images. All images are in .jpg format. File name format: for example "Abyssinian cat 2.jpg", first comes the name of the breed, then the number - the serial number of the sample.

Outcome
Such a dataset can, for example, be used to train models that classify domestic cats by breed. The collected data can be used for the following purposes: determining the characteristics of caring for a cat, selecting a suitable diet for cats of certain breeds, as well as optimizing the primary identification of the breed at shows and when judging. Cotoset can also be used by businesses - veterinary clinics and feed manufacturers. The cotoset itself is freely available on GitHub .
Afterword
Based on the results of the dataton, our students received the first case in their data scientist portfolio and feedback on work from mentors from such companies as Huawei, Kaspersky Lab, Align Technology, Auriga, Intellivision, Wrike, Merlin AI. Dataton was also useful in that he immediately pumped the profile hard and soft skills that future data scientists will need when they will already work in real teams. It is also a good opportunity for mutual "knowledge exchange", since each student has a different background and, accordingly, his own view of the problem and its possible solution. We can say with confidence that without such practical work, similar to some already existing business tasks, the training of specialists in the modern world is simply unthinkable.
You can find out more about our master's program on the website data.misis.ru and in the Telegram channel .
Well, and, of course, not a single master's degree! If you want to learn more about Data Science , Machine Learning and Deep Learning - take a look at our corresponding courses, it will be difficult, but exciting. And the HABR promo code will help you to learn new things by adding 10% to the discount on the banner.

- Data Scientist Profession
- Data Analyst profession
- Data Engineering Course
Other professions and courses
- Java-
- QA- JAVA
- Frontend-
- C++
- Unity
- -
- iOS-
- Android-
- Machine Learning
- « Machine Learning Data Science»
- «Python -»
- « »
- DevOps