How we built parallel universes for our (and your) CI / CD pipeline in Octopod

Hello, Habr! My name is Denis and I will tell you how it was suggested to us to make a technical solution to optimize the development process and QA in our Typeable. It began with a general feeling that we were doing everything right, but it would still be possible to move faster and more efficiently - accept new tasks, test, synchronize less. All of this led us to discussions and experiments, which resulted in our open-source solution, which I will describe below and which is now available to you.
Let us, however, not run ahead of the locomotive, but start from the very beginning and understand in detail what I am talking about. Let's imagine a fairly standard situation - a project with a three-tier architecture (storage, backend, frontend). There is a development process and a quality assurance process in which there are several environments (often called outlines) for testing:
- Production is the main working environment where system users go.
- Pre-Production – - (, production, ; RC), production, production . Pre-production – , Production .
- Staging – , , , Production, .
With Pre-production, everything is quite clear: release candidates consistently go there, the release history is the same as in Production . There are nuances with Staging :
- ORGANIZATIONAL. Testing critical parts may require a delay in publishing new changes; changes can interact in unpredictable ways; tracing errors becomes difficult due to the large amount of activity on the server; sometimes there is confusion about what version is implemented; it is sometimes unclear which of the accumulated changes caused the problem.
- . : production , «». staging , . . : , . , QA production , .
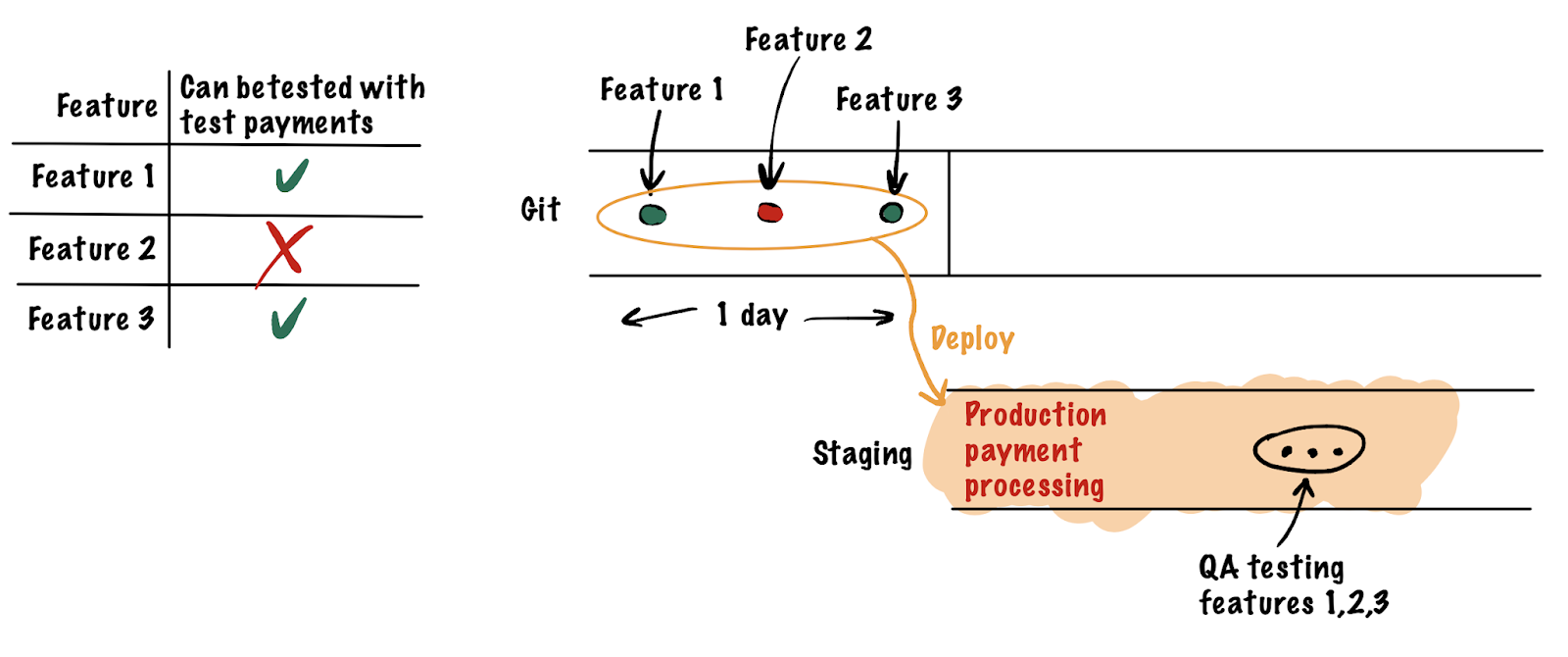
- .
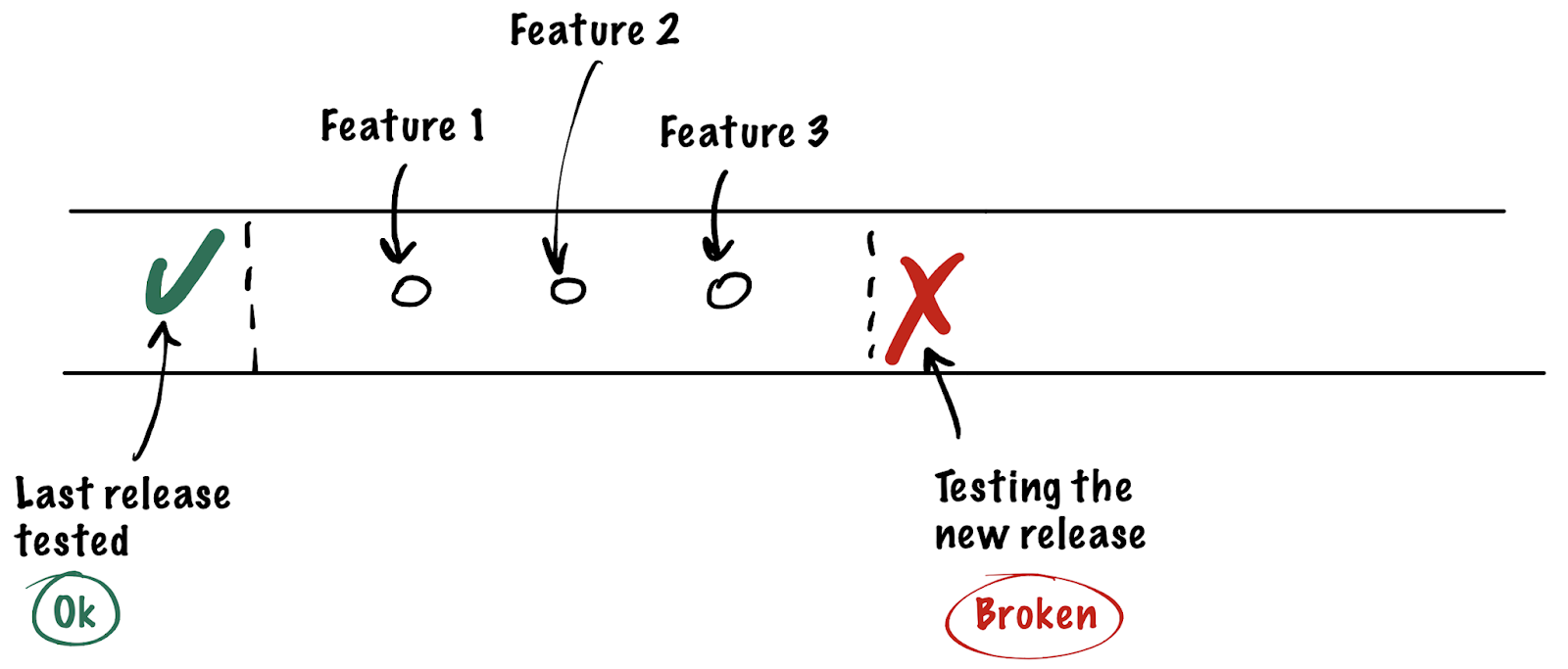
- . . -. , . , . , .
- . - , , , , . , , , . , . production , time-to-production time-to-market .
Each of these points is solved in one way or another, but all this led to the question, will it be possible to simplify our life if we move away from the concept of one staging stand to their dynamic number. Similar to how we have CI checkouts for each branch in git, we can get QA checkouts for every branch as well. The only thing stopping us from such a move is the lack of infrastructure and tools. Roughly speaking, to accept a feature, a separate staging is created with a dedicated domain name, QA tests it, accepts or returns it for revision. Something like this:

With this approach, the problem of different environments is solved in a natural way:

Tellingly, after the discussion, the opinions in the team were divided into “let's try, I want better than now” and “it seems so normal, I don't see monstrous problems,” but we'll come back to this later.
Our path to solution
The first thing we tried was a prototype built by our DevOps: a combination of docker-compose (orchestration), rundeck (management) and portainer (introspection), which allowed us to test the overall direction of thought and approach. There were problems with convenience:
- Any change required access to the code and rundeck, which the developers had, but did not have, for example, the QA engineers.
- This was raised on one large machine, which soon became insufficient, and for the next step, Kubernetes or something similar was already needed.
- Portainer gave information not about the state of a particular staging, but about a set of containers.
- I had to constantly merge the file with the description of the stages, the old stands had to be deleted.
Even with all its drawbacks and with some inconvenience of operation, the approach came in and began to save the time and effort of the project team. The hypothesis was tested, and we decided to do everything the same, but in a tightly knocked manner. In pursuit of the goal of optimizing the development process, we collected the requirements for a new one and understood what we wanted:
- Use Kubernetes to scale to any number of staging environments and have a standard set of tools for modern DevOps.
- A solution that would be easy to integrate into the infrastructure already using Kubernetes.
- , Product QA-. , . – .
- , CI/CD , . , Github Actions CI.
- , DevOps .
- , , / - .
- Full information and a list of actions should be available to superusers in the person of DevOps engineers and team leads.
And we started developing Octopod . The name was a confusion of several thoughts about K8S, which we used to orchestrate everything on the project: many projects in this ecosystem reflect marine aesthetics and themes, and we imagined a kind of octopus orchestrating many underwater containers with tentacles. Plus, the Pod is one of the founding entities in Kubernetes.
On the technical stack, Octopod is Haskell, Rust, FRP, compilation to JS, Nix. But in general the story is not about this, so I will not dwell on this in more detail.
The new model became known as Multi-staging within our company. Operating multiple staging environments simultaneously is akin to traveling across parallel universes and dimensions in science fiction (and not so much). In it, the universes are similar to each other with the exception of one small detail: somewhere different sides won the war, somewhere a cultural revolution happened, somewhere - a technological breakthrough. The premise may be small, but what changes it can lead to! In our processes, this premise is the content of each individual feature branch.
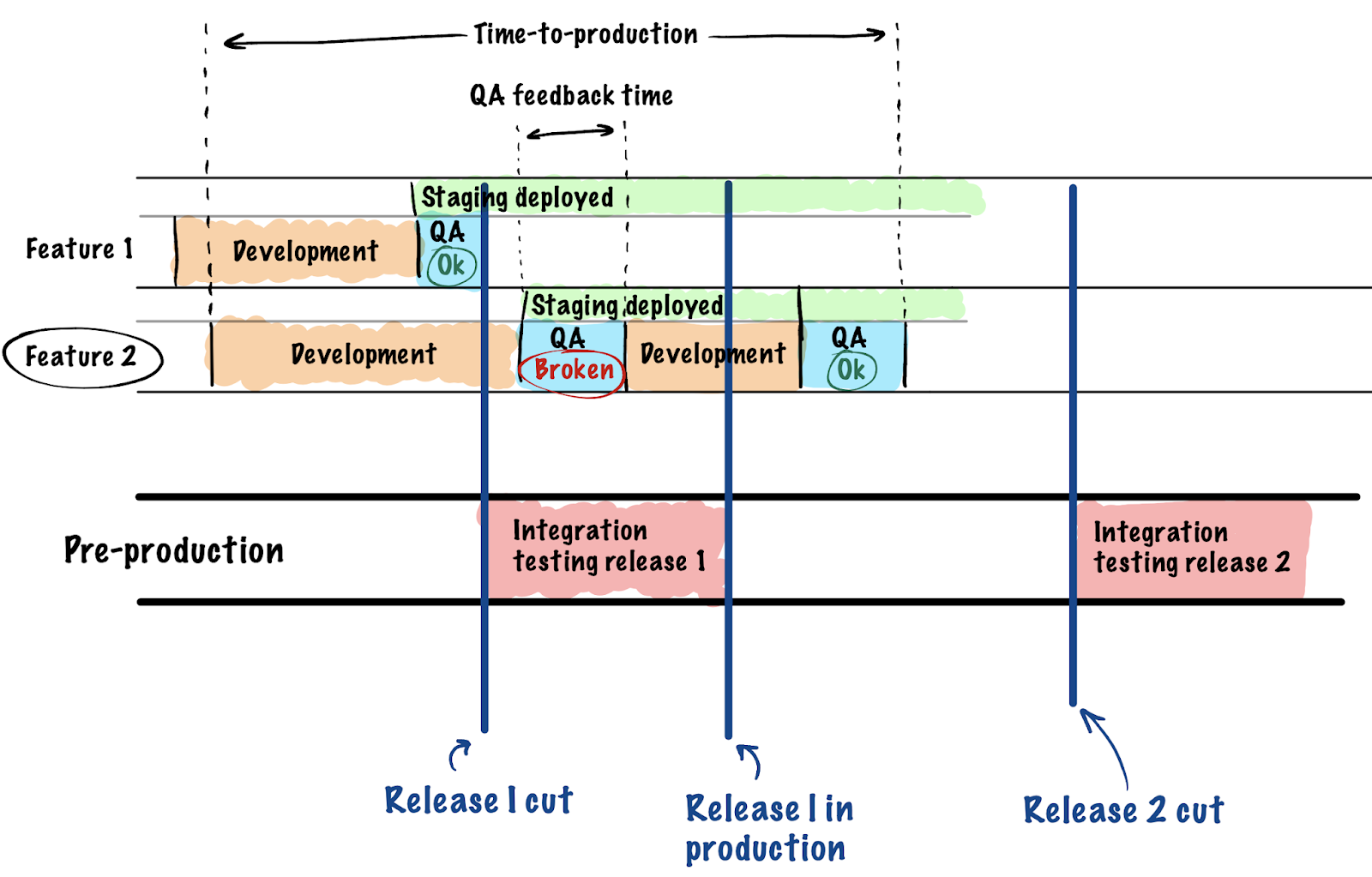
Our implementation took place in several stages and began with one project. This includes adjusting the project orchestration from the DevOps side and reorganizing the testing and communication process from the project manager.
As a result of a number of iterations, some features of Octopod itself have been removed or changed beyond recognition. For example, in the first version we had a page with a deployment log for each circuit, but here's the bad luck - not every team accepts that credentials can flow through these logs to all employees involved in development. As a result, we decided to get rid of this functionality, and then returned it in a different form - now it is customizable (and therefore optional) and implemented through integration with the kubernetes dashboard .
There are also other points: with the new approach, we use more compute resources, disks and domain names to support the infrastructure, which raises the question of cost optimization. If you combine this with DevOps-subtleties, then the material will be typed in a separate post, or even two, so I will not continue about this here.
In parallel with solving emerging problems on one project, we began to integrate this solution into another, when we saw interest from another team. This allowed us to make sure that our solution was customizable and flexible enough for the needs of different projects. At the moment, Octopod has been widely used in our country for three months.
As a result
As a result, the system and processes were implemented in several projects, there is interest from one more. Interestingly, even those colleagues who did not see problems with the old scheme, now would not want to switch back to it. It turned out that for some we solved problems that they didn't even know about!
The most difficult, as usual, was the first implementation - most of the technical issues and problems were caught on it. Feedback from users made it possible to better understand what needs to be improved in the first place. In the latest versions, the interface and work with Octopod looks like this:
For us, Octopod has become an answer to a procedural question, and I would call the current state an unequivocal success - flexibility and convenience have clearly increased. There are still not fully resolved issues: we drag the authorization of Octopod itself in the cluster to Atlassian oauth for several projects, and this process is delayed. However, this is nothing more than a matter of time, technically the problem has already been solved in the first approximation.
Open-source
We hope that Octopod will be useful not only for us. We will be glad to receive suggestions, pull requests and information on how you optimize similar processes. If the project is interesting to the audience, we will write about the features of orchestration and operation with us.
All source code with configuration examples and documentation is available in the repository on Github .