
There are already quite a few publications about the Apple Matrix coprocessor (AMX). But most are not very clear to everyone and everyone. I will try to explain the nuances of the coprocessor in clear language.
Why isn't Apple talking too much about this coprocessor? What's so secret about it? And if you've read about the Neural Engine in SoC M1, you may have a hard time understanding what's so unusual about AMX.
But first, let's remember the basic things ( if you know well what matrices are, and I'm sure there are most of such readers on Habré, then you can skip the first section, - approx. Transl. ).
What is a matrix?
In simple terms, this is a table with numbers. If you have worked in Microsoft Excel, then it means that you have dealt with the similarity of matrices. The key difference between matrices and ordinary tables with numbers is in the operations that can be performed with them, as well as in their specific essence. The matrix can be thought of in many different forms. For example, as strings, then it is a row vector. Or as a column, then it is, quite logically, a column vector.

We can add, subtract, scale and multiply matrices. Addition is the simplest operation. You just add each item separately. The multiplication is a little trickier. Here's a simple example.
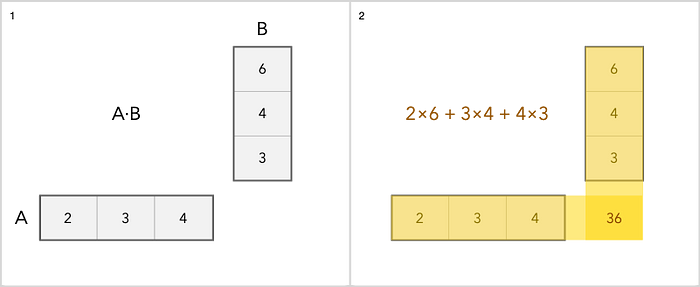
As for other operations with matrices, you can read about it here .
Why are we even talking about matrices?
The fact is that they are widely used in:
• Image processing.
• Machine learning.
• Handwriting and speech recognition.
• Compression.
• Work with audio and video.
When it comes to machine learning, this technology requires powerful processors. And just adding a few cores to the chip is not an option. Now the kernels are "sharpened" for certain tasks.

The number of transistors in the processor is limited, so the number of tasks / modules that can be added to the chip is also limited. In general, you could just add more cores to the processor, but that will just speed up standard computations that are already fast. So Apple decided to take a different route and highlight modules for image processing, video decoding, and machine learning tasks. These modules are coprocessors and accelerators.
What's the difference between the Apple Matrix coprocessor and the Neural Engine?
If you were interested in the Neural Engine, you probably know that it also performs matrix operations for working with machine learning problems. But if so, then why did you also need the Matrix coprocessor? Maybe it's the same thing? Am I confusing anything? Let me clarify the situation and tell you what the difference is, explaining why both technologies are needed.
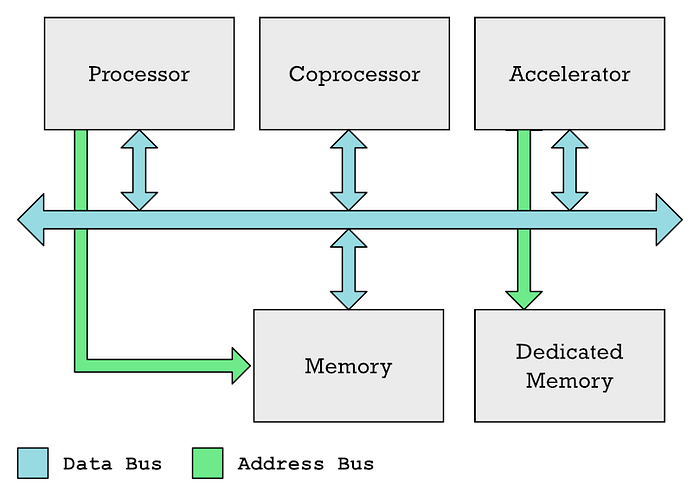
The main processing unit (CPU), coprocessors, and accelerators can usually communicate over a common data bus. The CPU usually controls access to memory, while an accelerator such as a GPU often has its own dedicated memory.
I admit that in my previous articles I have used the terms "coprocessor" and "accelerators" interchangeably, although they are not the same thing. So, GPU and Neural Engine are different types of accelerators.
In both cases, you have special areas of memory that the CPU must fill with the data it wants to process, plus another area of memory that the CPU fills with a list of instructions that the accelerator must execute. The processor takes time to complete these tasks. You have to coordinate all this, fill in the data, and then wait for the results.
And such a mechanism is suitable for large-scale tasks, but for small tasks this is overkill.

This is the advantage of coprocessors over accelerators. Coprocessors sit and watch the flow of machine code instructions that come from memory (or in particular the cache) to the CPU. The coprocessor is forced to respond to the specific instructions that they were forced to process. Meanwhile, the CPU mostly ignores these instructions or helps make them easier for the coprocessor to handle.
The advantage is that the instructions executed by the coprocessor can be included in regular code. In the case of the GPU, everything is different - shader programs are placed in separate memory buffers, which must then be explicitly transferred to the GPU. You won't be able to use regular code for this. And that's why AMX is great for simple matrix processing tasks.
The trick here is that you need to define instructions in the instruction set architecture (ISA) of your microprocessor. Thus, when using a coprocessor, there is a tighter integration with the processor than when using an accelerator.
The creators of ARM, by the way, have long resisted adding custom instructions to ISA. And this is one of the advantages of RISC-V. But in 2019, the developers gave up, however, stating the following: “The new instructions are combined with the standard ARM instructions. To avoid software fragmentation and maintain a consistent software development environment, ARM expects clients to use custom instructions primarily in library calls. "
This might be a good explanation for the lack of description of AMX instructions in the official documentation. ARM simply expects Apple to include instructions in the libraries provided by the customer (in this case, Apple).
What is the difference between a matrix coprocessor and a vector SIMD?
In general, it is not so difficult to confuse a matrix coprocessor with vector SIMD technology, which is found in most modern processors, including ARM. SIMD stands for Single Instruction Multiple Data.

SIMD allows you to increase system performance when you need to perform the same operation on several elements, which is closely related to matrices. In general, SIMD instructions, including ARM Neon or Intel x86 SSE or AVX instructions, are often used to speed up matrix multiplication.
But the SIMD vector engine is part of the microprocessor core, just as the ALU (Arithmetic Logic Unit) and FPU (Floating Point Unit) are part of the CPU. Well, already the instruction decoder in the microprocessor "decides" which functional block to activate.

But the coprocessor is a separate physical module, and not part of the microprocessor core. Earlier, for example, Intel's 8087 was a separate chip that was intended to accelerate floating point operations.

You may find it odd that someone would develop such a complex system, with a separate chip that processes the data going from memory to the processor in order to detect a floating point instruction.
But the chest opens simply. The fact is that the original 8086 processor had only 29,000 transistors. The 8087 already had 45,000 of them. Ultimately, the technologies allowed integrating FPUs into the main chip, getting rid of coprocessors.
But why AMX is not part of the M1 Firestorm core is not entirely clear. Maybe Apple just decided to move non-standard ARM elements outside of the main processor.
But why isn't AMX much talked about?
If AMX is not described in the official documentation, how could we even find out about it? Thanks to developer Dougall Johnson, who did a wonderful reverse engineering of the M1 and discovered the coprocessor. His work is described here . As it turned out, Apple created specialized libraries and / or frameworks like Accelerate for mathematical operations related to matrices . All of this includes the following elements:
• vImage - higher level image processing, such as converting between formats, manipulating images.
• BLASIs a kind of industry standard for linear algebra (what we call mathematics dealing with matrices and vectors).
• BNNS - used to run neural networks and train.
• vDSP - digital signal processing. Fourier transforms, convolution. These are mathematical operations performed when processing an image or any signal containing sound.
• LAPACK - Higher level linear algebra functions, such as solving linear equations.
Johnson understood that these libraries would use the AMX coprocessor to speed up computations. Therefore, he developed specialized software for analyzing and monitoring library actions. Ultimately, he was able to locate undocumented AMX machine code instructions.
And Apple doesn't document all of this because ARM LTD. tries not to advertise too much information. The fact is that if custom functions are really widely used, this can lead to fragmentation of the ARM ecosystem, as discussed above.
Apple has the opportunity, without really advertising all this, later to change the operation of systems if necessary - for example, delete or add AMX instructions. For developers, the Accelerate platform is enough, the system will do the rest itself. Accordingly, Apple can control both hardware and software for it.
Benefits of the Apple Matrix coprocessor
There is a lot here, an excellent overview of the element's capabilities was made by Nod Labs, which specializes in machine learning, intelligence and perception. In particular, they performed comparative performance tests between AMX2 and NEON.
As it turned out, AMX performs the operations necessary to perform operations with matrices twice as fast. This does not mean, of course, that AMX is the best, but for machine learning and high performance computing - yes.
The bottom line is that Apple's coprocessor is an impressive technology that gives Apple ARM an edge in machine learning and high performance computing.
