
I decided to write an article for anyone trying to find relevant Amazon interview questions and answers. I have taken a few interview questions that have been asked in recent months and tried to provide concise and clear answers to them. There are difficult questions, there are simple ones, but in any case, both of them can be useful.
Q: The couple have two children and the couple knows that one of the children is a boy. What is the likelihood that the other child will be a boy?
There is no catch here. The probability that one child will be a boy is independent of the other, so it is 50%. You may get confused by Leonard Mlodinov's question , where the answer is one third, but this is a completely different question, not related to ours.
Q: Explain what a p-value is.
If you google what a p-value is, you will get the following answer: “This is the probability of getting for a given probabilistic model of the distribution of values of a random variable the same or more extreme value of statistics (arithmetic mean, median, etc.), compared to the previously observed, provided that the null hypothesis is correct. "
Verbose answer, for the reason that p is very specific in meaning and often misunderstood.
A simpler definition of a p-value is: "This is the probability that the observed statistic will occur by chance, given the distribution of the sample."
Alpha sets the standard for how extreme values must be before the null hypothesis can be rejected. The p value indicates the extreme of the data.
Q: There are 4 red and 2 blue balls, what is the probability that they will be the same in two elections?
The answer is the probability that both are red, plus the probability that both are blue. Let's assume that this question is without replacement.
- Probability of 2 reds = (4/6) * (3/6) = 1/3 or 33%
- Probability of 2 blue = (2/6) * (1/6) = 1/18 or 5.6%
Therefore, the probability that the balls will be the same is approximately 38.6%.
Q: Describe tree, SVM and random forest. Tell us about their advantages and disadvantages.
Decision trees: A tree-like model used to model decisions based on one or more conditions.
Pros: Easy to implement, intuitive, handles missing values.
Cons: high variance, imprecise
Pros: high dimensional accuracy
Cons: tendency to overfit, does not directly estimate the probability
Pros: Can achieve higher precision, handle missing values, no function scaling required, can determine function importance.
Cons: black box, computationally intensive.
Dimensionality reduction is the process of reducing the number of features in a dataset. This is mainly important when you want to reduce the variance of your model (overfitting).
Wikipedia states four benefits of dimensionality reduction:
- Reduces the required storage time and space.
- Removing multicollinearity improves the interpretation of machine learning model parameters.
- It becomes easier to visualize data when scaled down to very small dimensions such as 2D or 3D.
- Avoids the curse of dimension.
We need to make some assumptions on this question before we can answer it. Suppose there are two possible locations to buy a particular item on Amazon, and the probability of finding it at location A is 0.6 and B is 0.8. The likelihood of finding a product on Amazon can be explained as follows:
We can reformulate the above as P (A) = 0.6 and P (B) = 0.8. Also, let's assume that these are independent events, which means that the probability of one event does not depend on another. We can then use the formula ...
P (A or B) = P (A) + P (B) - P (A and B)
P (A or B) = 0.6 + 0.8 - (0.6 * 0 , 8)
P (A or B) = 0.92
Q: If there are 8 balls of equal weight and 1 ball that weighs a little more (9 balls in total), how many weighings are needed to determine which ball is the heaviest?

Two weighings are required (see Parts A and B above):
You must divide the nine balls into three groups of three and weigh two groups. If the scales are balanced (option 1), you know that the heavy ball belongs to the third group of balls. Otherwise, you will take a group with a large weight (option 2).
Then you follow the same step, but you will have three groups of one balloon instead of three groups of three.
Q: What is "retraining"?
Overfitting is an error when a model “fits” too well to the data, resulting in a model with high variance and low bias. As a consequence, the overfitting model will inaccurately predict new data points, even if it has high fidelity in the training data.
Q: We have two models, one with 85% accuracy, the other with 82% accuracy. Which one will you choose?
If we only care about the accuracy of the model, then the answer is 85%. But if the interviewer asked about this, it is probably worth finding out in what context the question is asked, i.e. what the model is trying to predict. This will give us a better idea of whether the scoring metric should really be accuracy, or another metric like recall or f1 score.
Q: What is a naive Bayesian algorithm?
The Naive Bayesian Classifier is a popular classifier used in Data Science. The idea behind this is based on Bayes' theorem:

In simple terms, this equation is used to answer the next question. “What is the probability of y (my output variable) with X (my input variables)? And because of the naive assumption that the variables are independent for a given class, you can say that:

Also, by removing the denominator, we can say that P (y | X) is proportional to the right side.
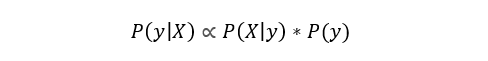
Therefore, the goal is to find the class with the highest proportional probability.
Q: How will changing the basic membership fee affect the market?
I'm not 100% sure of the answer to this question, but I'll try my best!
Let's take an example of increasing the basic membership fee - there are two parties involved: buyers and sellers.
For buyers, the impact of an increase in the basic membership fee ultimately depends on the price elasticity of demand for buyers. If the price elasticity is high, then a given price increase will lead to a significant drop in demand, and vice versa. Buyers who keep buying membership dues are probably Amazon's most loyal and active customers - they'll also likely pay more attention to premium products.
Sellers will suffer as the cost of buying a basket of Amazon products is now higher. This will make some foods more affected while others may not. It's likely that the premium products that Amazon's most loyal customers are buying won't be hit as badly as electronics.
Thank you for attention!
What I love about these interviews and the issues they deal with are two things:
- They help you learn new concepts that you weren't familiar with before.
- They open up concepts that you know from a new angle.
I hope all of this will help you prepare for your journey into the world of Data Science!
, Data Science AR- Banuba - Skillbox.
, -: , , . «» .
« ». . , , , .
:
1) , ?
2) ?
3) ?
4) , , -?
5) , ?
, .