
The problems that machine learning solves today are often complex and include a large number of features (features). Due to the complexity and diversity of the initial data, the use of simple machine learning models often does not allow achieving the required results, so complex, non-linear models are used in real business cases. Such models have a significant drawback: due to their complexity, it is almost impossible to see the logic by which the model assigned this particular class to the account operation. The interpretability of the model is especially important when the results of its work need to be presented to the customer - he will most likely want to know on the basis of what criteria decisions are made for his business.
, sklearn, xgboost, lightGBM (). , . , , ? ? , . SHAP. SHAP . , .
. , . 213 , .
kaggle .
:
%%time
# LOAD TRAIN
X_train=pd.read_csv('train_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols+['isFraud'])
train_id= pd.read_csv('train_identity.csv',index_col='TransactionID', dtype=dtypes)
X_train = X_train.merge(train_id, how='left', left_index=True, right_index=True)
# LOAD TEST
X_test=pd.read_csv('test_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols)
test_id = pd.read_csv('test_identity.csv',index_col='TransactionID', dtype=dtypes)
fix = {o:n for o, n in zip(test_id.columns, train_id.columns)}
test_id.rename(columns=fix, inplace=True)
X_test = X_test.merge(test_id, how='left', left_index=True, right_index=True)
# TARGET
y_train = X_train['isFraud'].copy()
del train_id, test_id, X_train['isFraud']; x = gc.collect()
# PRINT STATUS
print('Train shape',X_train.shape,'test shape',X_test.shape)
X_train.head()

, , , , .
, () , , . , , , .
.
:
if BUILD95:
feature_imp=pd.DataFrame(sorted(zip(clf.feature_importances_,cols)), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False).iloc[:50])
plt.title('XGB95 Most Important Features')
plt.tight_layout()
plt.show()
del clf, h; x=gc.collect()

, , . : ? . , , . , , SHAP. , , : 20 . 50 .
:
import shap
shap.initjs()
shap_test = shap.TreeExplainer(h).shap_values(X_train.loc[idxT,cols])
shap.summary_plot(shap_test, X_train.loc[idxT,cols],
max_display=25, auto_size_plot=True)
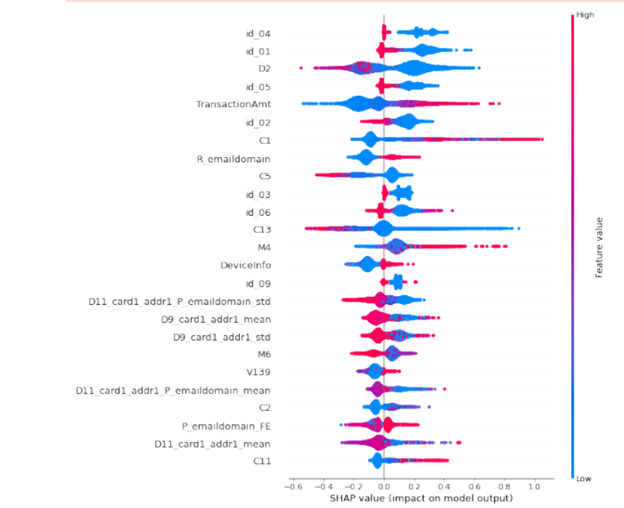
, . 2 . «0», «1». , . , . , , , : , , . , email.
Based on the data obtained, it is possible to simplify the model, that is, to leave only the parameters that have a significant impact on the prediction results of our model. In addition, it becomes possible to assess the importance of features for certain subgroups of data, for example, customers from different regions, transactions at different times of the day, etc. In addition, this tool can be used to analyze individual cases, for example, to analyze "outliers" and extreme values. SHAP can also help in finding falling zones when classifying negative phenomena. This tool, in combination with other approaches, will make the models lighter, better quality, and the results interpretable.