
How do I update the attribute value for all records in a table? How do I add a primary or unique key to a table? How do I split a table in two? How ...
If the application may be unavailable for some time for migrations, then the answers to these questions are not difficult. But what if you need to migrate hot - without stopping the database and without disturbing others to work with it?
We will try to answer these and other questions that arise during schema and data migrations in PostgreSQL in the form of practical advice.
This article - decoding performance at SmartDataConf conference ( here you can find the presentation, the video will appear in due course). There was a lot of text, so the material will be divided into 2 articles:
- basic migrations
- approaches for updating large tables.
At the end there is a summary of the entire article in the form of a pivot table cheat sheet.
Content
The crux of the problem
Add a column
Add a default
column Delete a column
Create an index
Create an index on a partitioned table
Create a NOT NULL constraint
Create a foreign key
Create a unique constraint
Create a primary key Quick Migration Cheat Sheet
The essence of the problem
Suppose we have an application that works with a database. In the minimal configuration, it can consist of 2 nodes - the application itself and the database, respectively.

With this scheme, application updates often occur with downtime. At the same time, you can update the database. In such a situation, the main criterion is time, that is, you need to complete the migration as quickly as possible in order to minimize the time of service unavailability.
If the application grows and it becomes necessary to carry out releases without downtime, we start using multiple application servers. There can be as many of them as you like, and they will be on different versions. In this case, it becomes necessary to ensure backward compatibility.

At the next stage of growth, the data ceases to fit into one database. We begin to scale the database as well - by sharding. Since in practice it is very difficult to migrate multiple databases synchronously, this means that at some point they will have different data schemas. Accordingly, we will be working in a heterogeneous environment, where application servers may have different code and databases with different data schemas.
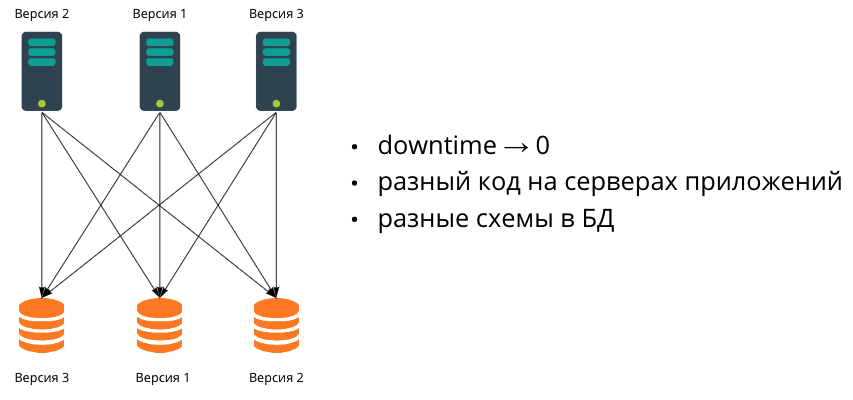
It is about this configuration that we will talk about in this article and consider the most popular migrations that developers write - from simple to more complex.
Our goal is to perform SQL migrations with minimal impact on application performance, i.e. change the data or data schema so that the application continues to run and users don't notice.
Adding a column
ALTER TABLE my_table ADD COLUMN new_column INTEGER --
Probably, any person who works with the database wrote a similar migration. If we talk about PostgreSQL, then this migration is very cheap and safe. The command itself, although it captures the highest level lock ( AccessExclusive ), is executed very quickly, since “under the hood” only meta information about a new column is added without rewriting the data of the table itself. In most cases, this happens unnoticed. But problems can arise if at the time of migration there are long transactions working with this table. To understand the essence of the problem, let's look at a small example of how locks work in a simplified way in PostgreSQL. This aspect will be very important when considering most other migrations as well.
Suppose we have a large table and we SELECT all data from it. Depending on the size of the database and the table itself, it can take several seconds or even minutes.

The weakest AccessShare lock that protects against changes to the table structure is acquired during the transaction .
At this moment, another transaction comes, which is just trying to make an ALTER TABLE query to this table. The ALTER TABLE command, as mentioned earlier, grabs an AccessExclusive lock that is not compatible with any other lock at all. She gets in line.
This lock queue is "raked" in strict order; even if other queries come after ALTER TABLE (for example, also SELECTs), which by themselves do not conflict with the first query, they all queue up for ALTER TABLE. As a result, the application "stands up" and waits for ALTER TABLE to be executed.
What to do in such a situation? You can limit the time it takes to acquire a lock using the SET lock_timeout command . We execute this command before ALTER TABLE (the LOCAL keyword means that the setting is valid only within the current transaction, otherwise - within the current session):
SET LOCAL lock_timeout TO '100ms'
and if the command fails to acquire the lock in 100 milliseconds, it will fail. Then we either restart it again, expecting it to be successful, or we go to figure out why the transaction takes a long time, if this should not be in our application. In any case, the main thing is that we did not crash the application.
It should be said that setting a timeout is useful before any command that grabs a strict lock.
Adding a column with a default value
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42
If this command is executed in older PostgreSQL version (below 11), then it will overwrite all rows in the table. Obviously, if the table is large, this can take a long time. And since a strict lock ( AccessExclusive ) is captured for the execution time , all queries to the table are also blocked.
If PostgreSQL is 11 or newer, this operation is quite cheap. The fact is that in the 11th version an optimization was made, thanks to which, instead of rewriting the table, the default value is saved to a special table pg_attribute, and later, when performing SELECT, all empty values of this column will be replaced on the fly with this value. In this case, later, when the rows in the table are overwritten due to other modifications, the value will be written to these rows.
Moreover, from the 11th version, you can also immediately create a new column and mark it as NOT NULL:
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42 NOT NULL
What if PostgreSQL is older than 11?
Migration can be done in several steps. First, we create a new column without constraints and default values. As stated earlier, it's cheap and fast. In the same transaction, we modify this column by adding a default value.
ALTER TABLE my_table ADD COLUMN new_column INTEGER;
ALTER TABLE my_table ALTER COLUMN new_column SET DEFAULT 42;
This division of one command into two may seem a little strange, but the mechanics are such that when a new column is created immediately with a default value, it affects all the records that are in the table, and when the value is set for an existing column (even if only what is created, as in our case), it only affects new records.
Thus, after executing these commands, it remains for us to update the values that were already in the table. Roughly speaking, we need to do something like this:
UPDATE my_table set new_column = 42 --
But such an UPDATE “head-on” is actually impossible, because when updating a large table, we will lock the entire table for a long time. In the second article (here in the future there will be a link) we will look at what strategies exist for updating large tables in PostgreSQL, but for now we will assume that we have somehow updated the data, and now both the old data and the new will be with the required value by default.
Removing a column
ALTER TABLE my_table DROP COLUMN new_column --
Here the logic is the same as when adding a column: the table data is not modified, only the meta information is changed. In this case, the column is marked as deleted and unavailable for queries. This explains the fact that when a column is dropped in PostgreSQL, physical space is not reclaimed (unless you perform a VACUUM FULL), that is, the data of old records still remains in the table, but is not available when accessed. The deallocation occurs gradually as rows in the table are overwritten.
Thus, the migration itself is simple, but, as a rule, errors sometimes occur on the backend side. Before deleting a column, there are a few simple preparatory steps to take.
- First, you need to remove all restrictions (NOT NULL, CHECK, ...) that are on this column:
ALTER TABLE my_table ALTER COLUMN new_column DROP NOT NULL
- The next step is to ensure backend compatibility. You need to make sure that the column is not used anywhere. For example, in Hibernate, you need to mark a field using annotation
@Transient
. In the JOOQ we are using, the field is added to exceptions using a tag<excludes>
:
<excludes>my_table.new_column</excludes>
You also need to look closely at queries"SELECT *"
- frameworks can map all columns into a structure in the code (and vice versa) and, accordingly, you may again face the problem of accessing a non-existent column.
After the changes are posted to all application servers, you can delete the column.
Index creation
CREATE INDEX my_table_index ON my_table (name) -- ,
Those who work with PostgreSQL probably know that this command locks the entire table. But since the very old version 8.2 there is the CONCURRENTLY keyword , which allows you to create an index in a non-blocking mode.
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name) --
The command is slower, but does not interfere with parallel requests.
This team has one caveat. It can fail — for example, when creating a unique index on a table that contains duplicate values. The index will be created, but it will be marked as invalid and will not be used in queries. Index status can be checked with the following query:
SELECT pg_index.indisvalid
FROM pg_class, pg_index
WHERE pg_index.indexrelid = pg_class.oid
AND pg_class.relname = 'my_table_index'
In such a situation, you need to delete the old index, correct the values in the table and then recreate it.
DROP INDEX CONCURRENTLY my_table_index
UPDATE my_table ...
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name)
It is important to note that the REINDEX command , which is just intended for rebuilding the index, works only in blocking mode until version 12 , which makes it impossible to use it. PostgreSQL 12 adds CONCURRENTLY support and can now be used.
REINDEX INDEX CONCURRENTLY my_table_index -- PG 12
Creating an Index on a Partitioned Table
We should also discuss creating indexes for partitioned tables. In PostgreSQL, there are 2 types of partitioning: through inheritance and declarative, which appeared in version 10. Let's look at both with a simple example.
Suppose we want to partition a table by date, and each partition will contain data for one year.
When partitioning through inheritance, we will have approximately the following scheme.
Parent table:
CREATE TABLE my_table (
...
reg_date date not null
)
Child partitions for 2020 and 2021:
CREATE TABLE my_table_y2020 (
CHECK ( reg_date >= DATE '2020-01-01' AND reg_date < DATE '2021-01-01' ))
INHERITS (my_table);
CREATE TABLE my_table_y2021 (
CHECK ( reg_date >= DATE '2021-01-01' AND reg_date < DATE '2022-01-01' ))
INHERITS (my_table);
Indexes by the partitioning field for each of the partitions:
CREATE INDEX ON my_table_y2020 (reg_date);
CREATE INDEX ON my_table_y2021 (reg_date);
Let's leave the creation of a trigger / rule for inserting data into a table.
The most important thing here is that each of the partitions is practically an independent table that is maintained separately. Thus, creating new indexes is also done as with regular tables:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name);
CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
Now let's look at declarative partitioning.
CREATE TABLE my_table (...) PARTITION BY RANGE (reg_date);
CREATE TABLE my_table_y2020 PARTITION OF my_table FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE my_table_y2021 PARTITION OF my_table FOR VALUES FROM ('2021-01-01') TO ('2021-12-31');
Index creation depends on the PostgreSQL version. In version 10, indexes are created separately - just like in the previous approach. Accordingly, creating new indexes for an existing table is also done in the same way.
In version 11, declarative partitioning has been improved and tables are now served together . Creating an index on the parent table automatically creates indexes for all existing and new partitions that will be created in the future:
-- PG 11 ()
CREATE INDEX ON my_table (reg_date)
This is useful when creating a partitioned table, but it is not applicable when creating a new index on an existing table because the command grabs a strong lock while the indexes are being created.
CREATE INDEX ON my_table (name) --
Unfortunately, CREATE INDEX does not support the CONCURRENTLY keyword for partitioned tables. To get around the limitation and migrate without blocking, you can do the following.
- Create index on parent table with ONLY option
CREATE INDEX my_table_index ON ONLY my_table (name)
The command will create an empty invalid index without creating indexes for the partitions . - Create indexes for each of the partitions:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name); CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
- Attach indexes of partitions to index of parent table:
ALTER INDEX my_table_index ATTACH PARTITION my_table_y2020_index; ALTER INDEX my_table_index ATTACH PARTITION my_table_y2021_index;
Limitations
Now let's go through the constraints: NOT NULL, foreign, unique and primary keys.
Creating a NOT NULL constraint
ALTER TABLE my_table ALTER COLUMN name SET NOT NULL --
Creating a constraint in this way will scan the entire table - all rows will be checked for the not null condition, and if the table is large, this may take a long time. The strong block that this command captures will block all concurrent requests until it completes.
What can be done? PostgreSQL has another type of constraint, CHECK , that can be used to get the desired result. This constraint tests any boolean condition that consists of row columns. In our case, the condition is trivial -
CHECK (name IS NOT NULL)
. But most importantly, the CHECK constraint supports invalidation (keyword
NOT VALID
):
ALTER TABLE my_table ADD CONSTRAINT chk_name_not_null
CHECK (name IS NOT NULL) NOT VALID -- , PG 9.2
The restriction created in this way applies only to newly added and modified records, and existing ones are not checked, so the table is not scanned.
To ensure that the existing records also satisfy the constraint, it is necessary to validate it (of course, by first updating the data in the table):
ALTER TABLE my_table VALIDATE CONSTRAINT chk_name_not_null
The command iterates over the rows of the table and checks that all records are not null. But unlike the usual NOT NULL constraint, the lock captured in this command is not as strong (ShareUpdateExclusive) - it does not block insert, update, and delete operations.
Creating a foreign key
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) --
When a foreign key is added, all records in the child table are checked for a value in the parent. If the table is large, then this scan will be long, and the lock held on both tables will also be long.
Fortunately, foreign keys in PostgreSQL also support NOT VALID, which means we can use the same approach as discussed earlier with CHECK. Let's create an invalid foreign key:
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) NOT VALID
then we update the data and perform validation:
ALTER TABLE my_table VALIDATE CONSTRAINT fk_group_id
Create a unique constraint
ALTER TABLE my_table ADD CONSTRAINT uk_my_table UNIQUE (id) --
As in the case with the previously discussed constraints, the command captures a strict lock, under which it checks all rows in the table against the constraint - in this case, uniqueness.
It is important to know that under the hood PostgreSQL implements unique constraints using unique indexes. In other words, when a constraint is created, a corresponding unique index with the same name is created to serve that constraint. Using the following query, you can find out the serving index of the constraint:
SELECT conindid index_oid, conindid::regclass index_name
FROM pg_constraint
WHERE conname = 'uk_my_table_id'
At the same time used on most of the time constraints of creating just the same goes for the index, and its subsequent binding to limit very quickly. Moreover, if you already have a unique index created, you can do this yourself by creating an index using the USING INDEX keywords:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id UNIQUE
USING INDEX uk_my_table_id -- , PG 9.1
Thus, the idea is simple - we create a unique index CONCURRENTLY, as we discussed earlier, and then create a unique constraint based on it.
At this point, the question may arise - why create a constraint at all, if the index does exactly what is required - guarantees the uniqueness of the values? If we exclude partial indices from the comparison , then from a functional point of view, the result is really almost identical. The only difference we have found is that constraints can be deferrable , but indexes cannot. The documentation for older versions of PostgreSQL (up to and including 9.4) had a footnotewith the information that the preferred way to create a unique constraint is to explicitly create a constraint
ALTER TABLE ... ADD CONSTRAINT
, and the use of indexes should be considered an implementation detail. However, in more recent versions this footnote has been removed.
Creating a primary key
In addition to being unique, the primary key imposes the not null constraint. If the column originally had such a constraint, then it will not be difficult to "turn" it into a primary key - we also create a unique index CONCURRENTLY, and then the primary key:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id PRIMARY KEY
USING INDEX uk_my_table_id -- id is NOT NULL
It is important to note that the column must have a "fair" NOT NULL constraint - the previously discussed CHECK approach will not work.
If there is no limit, then until the 11th version of PostgreSQL there is nothing to be done - there is no way to create a primary key without locking.
If you have PostgreSQL 11 or newer, this can be accomplished by creating a new column that will replace the existing one. So, step by step.
Create a new column that is not null by default and has a default value:
ALTER TABLE my_table ADD COLUMN new_id INTEGER NOT NULL DEFAULT -1 -- PG 11
We set up the synchronization of the data of the old and new columns using a trigger:
CREATE FUNCTION on_insert_or_update() RETURNS TRIGGER AS
$$
BEGIN
NEW.new_id = NEW.id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg BEFORE INSERT OR UPDATE ON my_table
FOR EACH ROW EXECUTE PROCEDURE on_insert_or_update();
Next, you need to update the data for rows that were not affected by the trigger:
UPDATE my_table SET new_id = id WHERE new_id = -1 --
The request with the update above is written "on the forehead", on a large table it is not worth doing this, because there will be a long blocking. As mentioned earlier, the second article will discuss approaches for updating large tables. For now, let's assume the data is updated and all that remains is to swap the columns.
ALTER TABLE my_table RENAME COLUMN id TO old_id;
ALTER TABLE my_table RENAME COLUMN new_id TO id;
ALTER TABLE my_table RENAME COLUMN old_id TO new_id;
In PostgreSQL, DDL commands are transactional - this means that you can rename, add, delete columns, and at the same time a parallel transaction will not see this during its operations.
After changing the columns, it remains to create an index and "clean up" - delete the trigger, function and old column.
A quick cheat sheet with migrations
Before any command that captures strong locks (almost all
ALTER TABLE ...
), it is recommended to call:
SET LOCAL lock_timeout TO '100ms'
| Migration | Recommended approach |
|---|---|
| Adding a column | |
| Adding a column with a default value [and NOT NULL] | with PostgreSQL 11:
before PostgreSQL 11:
|
| Removing a column |
|
| Index creation | If it fails:
|
| Creating an Index on a Partitioned Table | Partitioning via inheritance + declarative in PG 10:
Declarative Partitioning with PG 11:
|
| Creating a NOT NULL constraint |
|
| Creating a foreign key |
|
| Create a unique constraint |
|
| Creating a primary key | If the column is IS NOT NULL:
If column IS NULL with PG 11:
|
In the next article, we'll look at approaches to updating large tables.
Easy migrations everyone!