
With 12 issues behind us, it’s time to change the name and design a little, but inside you are still waiting for research, demos, open models and datasets. Meet the new installment of the Machine Learning Toolkit.
DALL E
Accessibility: project page / access to closed API via waiting list
OpenAI presented their new DALL-E transformer language model with 12 billion parameters, trained on image-text pairs. The model is based on GPT-3 and is used to synthesize images from textual descriptions.
Last June, the company showed how a model trained on sequences of pixels with an accurate description can fill in voids in images that are fed into the input. The results were already impressive then, but here Open AI exceeded all expectations. Just like GPT-3 synthesizes coherent complete sentences, DALL · E creates complex images.

The models are surprisingly good at anthropomorphic objects (radishes walking the dog) and a combination of incompatible objects (a snail in the form of a harp), which is why they chose the merger of two names for the name - the Spanish surrealist Salvador Dali and the Pixar robot WALL-I.
So what results does the model boast?
The model is able to visualize the depth of space, thus it is possible to manipulate a three-dimensional scene. It is enough to indicate when describing the desired image from what angle the object should be visible and under what lighting. In the future, this will allow the creation of true 3D representations.
In addition, the model is capable of applying optical effects to the scene, for example, as when shooting with a fisheye lens. But so far he does not cope well with reflections - the cube in the mirror has not been convincingly synthesized. Thus, with varying degrees of reliability, DALL · E through natural language copes with the tasks for which 3D modeling engines are used in the industry. This allows it to be used to render room design renders.
The model is well aware of geography and iconic landmarks, as well as the distinctive features of individual eras. She can synthesize a photograph of an old telephone or the Golden Gate Bridge in San Francisco.
With all this, the model does not need an ultra-precise description - it will fill in some of the gaps itself. As noted by Open AI, the more accurate the description, the worse the result.
Recall that the GPT-3 is a zero-shot model, it does not need to be additionally tuned and trained to perform specific tasks. In addition to the description, you can give a hint so that the model generates the desired answer. DALL · E does the same with rendering and can perform various image-to-image conversion tasks based on prompts. For example, you can give an image as an input and ask to make it in the form of a sketch.
Surprisingly, the creators did not set themselves such a goal and did not provide for this in any way when training the model. The ability was revealed only during testing.
Guided by this discovery, the authors studied the ability of DALL · E to solve logical problems of the visual IQ test and set the task not to choose the correct answer from the presented options, but to fully predict the missing element.
In general, the model managed to correctly continue the sequence in the part of the tasks where geometric comprehension was required.
The model has not yet been published, and there is not even a rough description of its architecture. At this stage, you can request access to the API or check out the unofficial implementation on PyTorch ( an unofficial version on TensorFlow is also being worked on ).
CLIP (Contrastive Language – Image Pre-training)
Accessibility: Project Page / Source Code
Deep Learning has revolutionized computer vision, but current approaches still have two significant issues that call into question the use of DNN in this area.
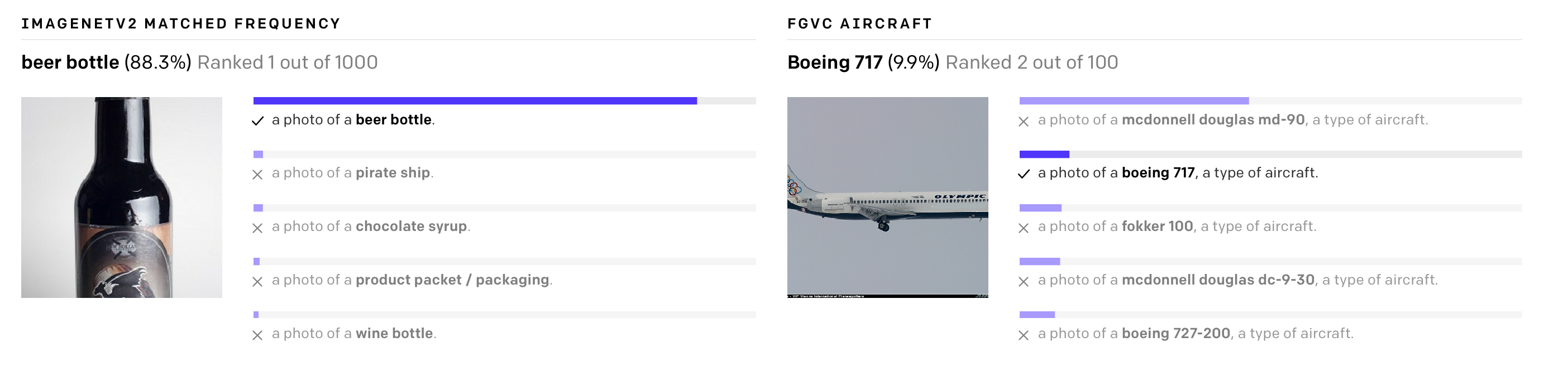
Firstly, creating datasets remains very expensive, but at the same time, as a result, it allows recognizing a very limited set of visual images and is suitable for narrow tasks. For example, when preparing the ImageNet dataset, it took 25,000 people to compose descriptions of 14 million images for 22,000 object categories. At the same time, the ImageNet model is good for predicting only those categories that are represented in the dataset, and if any other task is required, specialists will have to create new datasets and complete the model.
Second, models that perform well in benchmarks fall short in their natural environment. Models deployed in the real world do not perform as well as in a laboratory setting. In other words, the model is optimized to pass a specific test as a student cramming past exam questions.
OpenAI's open neural network CLIP aims to solve these problems. The model is trained on a large number of images and text descriptions available on the Internet and translates them into vector representations, embeddings. These representations are compared so that the numbers of the inscription and the picture suitable for it will be close.
CLIP can be immediately tested on different benchmarks without training on their data. The model performs classification tests without direct optimization. For example, the ObjectNet test tests the model's ability to recognize objects at different locations and with changing backgrounds, while ImageNet Rendition and ImageNet Sketch test the model's ability to recognize more abstract images of objects (not just a banana, but a sliced banana or banana sketch). CLIP performs equally well on all of them.
CLIP can be adapted to perform a wide range of visual classification tasks without additional training examples. To apply CLIP to a new problem, you just need to give the encoder the names of the visual representations, and it will produce a linear classifier of these representations, which is not inferior in accuracy to the models trained with the teacher.
Github already has an implementation for photos from Unsplash, which shows how well the model groups images. Designers can already use it to design moodboards.
DeBERTa from Microsoft
Availability: Source / Project Page
As usual, news from OpenAI overshadowed other announcements, although there was another event that was actively discussed in the community. Microsoft's DeBERTa model outperforms human baseline scores on the SuperGLUE Natural Language Comprehension (NLU) test.
A benchmark based on 10 parameters determines whether the algorithm “understands” what it has read and makes a rating. The average score for non-experts is 89.8 points, and the problems that the models need to solve are comparable to an English exam. DeBERTa showed 90.3, followed by Google's T5 + Meena.
Thus, the model managed to overtake a human for the second time, but it is noteworthy that DeBERTa has 1.5 billion training parameters, 8 times less than T5.
The model represents a new, different from the original transformer, divided attention mechanism, where each token is encoded by content vectors and positions that do not add up into one vector, separate matrices work with them.
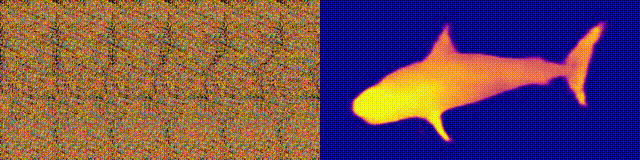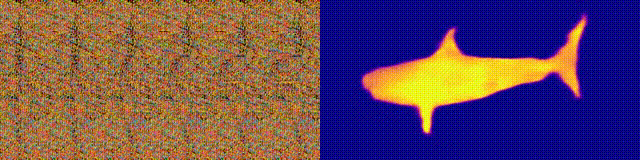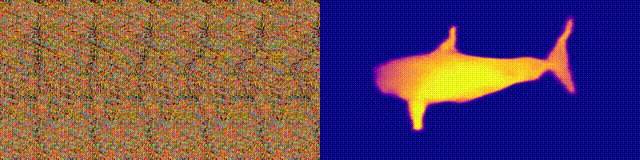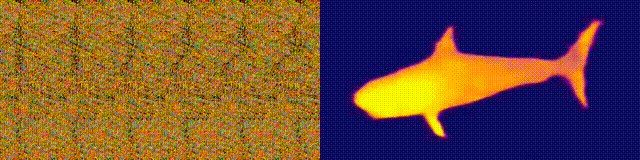
NeuralMagicEye
Accessibility: project page / code / colab
Remember the Magic Eye albums with stereograms? Here is something similar, only for autostereograms, in which both parts of the stereopair are in the same image and encoded in a raster structure, so that it can create visual illusions of three-dimensionality.
The author of the study trained the CNN model to reconstruct the autostereogram depth and understand its content. To achieve the stereo effect, the model had to be trained to detect and evaluate the mismatch of quasi-periodic textures. The model was trained on a dataset from 3D models, without a teacher.
The method allows you to accurately restore the depth of the autostereogram. The researchers hope that this will help people with visual impairments, and stereograms can be used as watermarks in images.
StyleFlow

Accessibility: Source Code
As we've seen more than once, unconditional GANs (such as StyleGANs) can create high-quality, photorealistic images. However, it is rarely possible to manage the generation process using semantic attributes while maintaining the quality of the output. Because of the complex and confusing GAN latency, editing one attribute often results in unwanted changes to others. This model helps to solve this problem. For example, you can change the viewing angle, lighting variation, expression, facial hair, gender, and age.
Taming Transformers
Accessibility: project page / source code
Transformers are capable of delivering excellent results in a variety of applications. But in terms of computing power, they are very demanding, so they are not suitable for working with high-resolution images. The study authors combined a transformer with an inductively displaced convolutional network and were able to image with high resolution.
POse EMbedding

Accessibility: Source Code
Everyday activities, be it running or reading a book, can be thought of as a sequence of postures, consisting of the position and orientation of a person's body in space. Pose recognition opens up a number of possibilities in AR, gesture control, etc. However, the data obtained from the 2D image differs depending on the camera's point of view. This algorithm from Google AI recognizes the similarity of poses from different angles, matching the key points of the 2D display of the pose with the view-invariant embedding.
Learning to Learn
Accessibility: Source Code
To learn how to pick up or place a bottle on the table, we just need to see another person doing it. To learn how to operate such objects, a machine requires manually programmed rewards for successfully completing the building blocks of a task. Before a robot can learn to place a bottle on a table, it needs to be rewarded for learning to move the bottle vertically. Only after a series of such iterations will he learn to place the bottle. Facebook introduced a method that trains a machine in a couple of human observation sessions.
This is how bright the first month of this year was. Thanks for reading, and stay tuned for future releases!