
Photo by Richard Jacobs on Unsplash
In November 2020, we started a major migration to upgrade our PostgreSQL cluster from 9.6 to 12.4. In this post, I will briefly describe our architecture at Coffee Meets Bagel, explain how the upgrade downtime was reduced to below 30 minutes, and share what we learned in the process.
Architecture
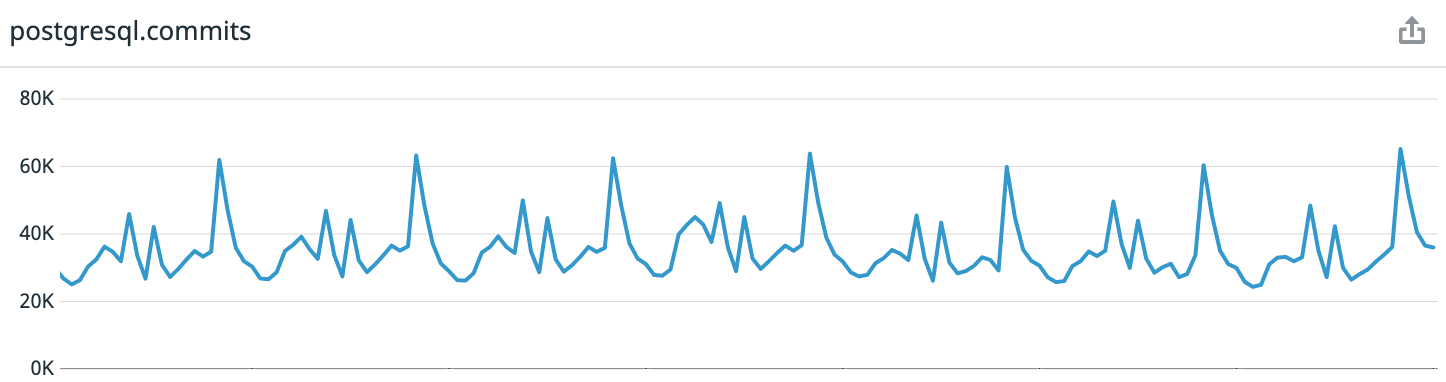
For reference: Coffee Meets Bagel is a romantic dating app with a curation system. Every day, our users receive a limited batch of high-quality candidates at noon in their time zone. This leads to highly predictable load patterns. If you look at the data for the last week from the moment of writing the article, we get an average of 30 thousand transactions per second, at the peak - up to 65 thousand.
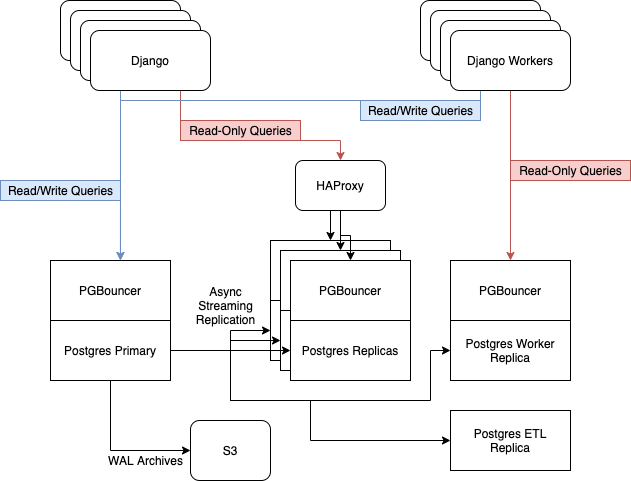
Before the update, we had 6 Postgres servers running on i3.8xlarge instances on AWS. They contained one master node, three replicas for serving read-only web traffic, balanced with HAProxy, one server for asynchronous workers, and one server for ETL [ Extract, Transform, Load ] and Business Intelligence....
We rely on Postgres built-in streaming replication to keep our replica fleet up to date.
Reasons for the upgrade
Over the past few years we have noticeably ignored our data layer, and as a result, it is slightly outdated. Especially a lot of "crutches" were picked up by our main server - it has been online for 3.5 years. We patch various system libraries and services without stopping the server.

My candidate for the r / uptimeporn subreddit
As a result, a lot of oddities have accumulated that make you nervous. For example, new services are
systemd
not started. I had to configure the launch of the agent
datadog
in the session
screen
. Sometimes SSH stopped responding when the processor load was above 50%, and the server itself regularly sent database requests.
And also the free space on the disk began to approach dangerous values. As I mentioned above, Postgres ran on i3.8xlarge instances in EC2, which have 7.6 TB of NVMe storage. Unlike EBS, the size of the disk cannot be dynamically changed here - what was originally laid down will be. And we filled about 75% of the disk. It became clear that the instance size would need to be changed to support future growth.
Our requirements
- Minimum downtime. We have set a goal of 4 hours of total downtime, including unplanned outages caused by upgrade errors.
- Build a new database cluster on new instances to replace the current fleet of aging servers.
- Go to i3.16xlarge for room to grow.
We know of three ways to upgrade Postgres: backing up and restoring from it, pg_upgrade, and pglogical logical replication.
We immediately abandoned the first method, restoring from a backup: for our 5.7 TB dataset, it would take too long. At its speed, pg_upgrade did not meet requirements 2 and 3: it is a migration tool on the same machine. Therefore, we chose logical replication.
Our process
Enough has been written about the key features of pglogical. Therefore, instead of repeating common truths, I will simply give articles that turned out to be useful to me:
- Major-version upgrading with minimal downtime ;
- Upgrading PostgreSQL from 9.4 to 10.3 with pglogical ;
- Demystifying pglogical - Tutorial .
We created a new primary Postgres 12 server and used pglogical to synchronize all our data. When it synchronized and moved on to replicate incoming changes, we started adding streaming replicas for it. After setting up a new streaming replica, we included it in HAProxy, and removed one of the old version 9.6.
This process continued until the Postgres 9.6 servers were completely shut down except for the master. The configuration took the following form.

Then it was the turn of the cluster switching (failover), for which we requested the maintenance window. The switching process is also well documented on the Internet, so I will only talk about the general steps:
- Transfer of the site to the technical work mode;
- Changing the master's DNS records to a new server;
- Forced synchronization of all sequences of primary keys;
- Manual start of checkpoint (
CHECKPOINT
) on the old master. - On the new wizard - performing some data validation and test procedures;
- Enabling the site.
Overall, the transition went well. Despite such major changes in our infrastructure, there was no unplanned downtime.
Lessons learned
With the overall success of the operation, a couple of problems were encountered along the way. The worst of them nearly killed our Postgres 9.6 master ...
Lesson # 1: Slow Synchronization Can Be Dangerous
Let's start with a context: how does pglogical work? The sender process on the provider (in this case our old wizard 9.6) decodes the write-ahead WAL log, fetches the logical changes and sends them to the subscriber.
If the subscriber lags behind, the provider will store WAL segments so that when the subscriber catches up, no data is lost.
The first time a table is added to the replication stream, pglogical must first synchronize the table data. This is done with the Postgres command
COPY
. After that, WAL segments begin to accumulate on the provider so that changes during operation
COPY
it turned out to be transferred to the subscriber after the initial synchronization, ensuring no data loss.
In practice, this means that when synchronizing a large table on a system with a heavy write / change load, you must carefully monitor disk usage. At the first attempt to synchronize our largest (4 TB) table, the team and the operator
COPY
worked for more than a day. During this time, the vendor node has accumulated more than one terabyte of proactive WAL logs.
As you may recall from what was said, our old database servers only had two terabytes of free disk space left. We estimated from the fullness of the subscriber's server disk that only a quarter of the table was copied. Therefore, the synchronization process had to be stopped immediately - the disk on the master would have ended earlier.
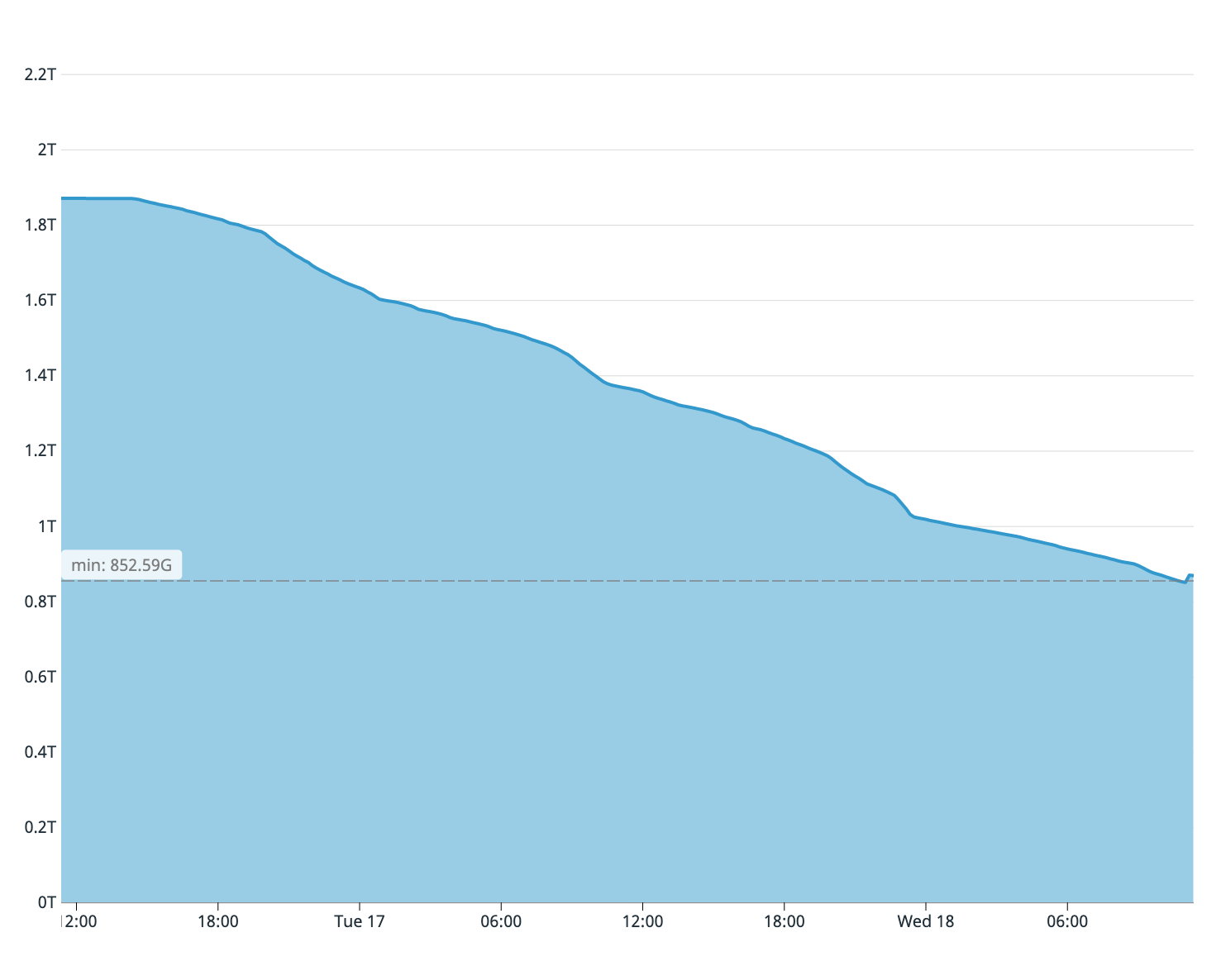
Available disk space on the old wizard on the first synchronization attempt
To speed up the synchronization process, we made the following changes to the subscriber database:
- Removed all indexes on the synchronized table;
fsynch
switched tooff
;- Changed
max_wal_size
to50GB
; - Changed
checkpoint_timeout
to1h
.
These four steps significantly speed up the synchronization process at the Subscriber, and our second attempt at table synchronization completed in 8 hours.
Lesson # 2: every row change is logged as a conflict
When pglogical detects a conflict, the application leaves a "
CONFLICT: remote UPDATE on relation PUBLIC.foo. Resolution: apply_remote
" entry in the logs .
However, it turned out that every row change processed by the Subscriber was logged as a conflict. In a few hours of replication, the subscriber's database left behind gigabytes of conflicting log files.
This problem was solved by setting a parameter
pglogical.conflict_log_level = DEBUG
in the file
postgresql.conf
.
about the author
 Tommy Lee is a Senior Software Engineer at Coffee Meets Bagel. Prior to that, he worked for Microsoft and Wave HQ, a Canadian accounting automation system manufacturer.
Tommy Lee is a Senior Software Engineer at Coffee Meets Bagel. Prior to that, he worked for Microsoft and Wave HQ, a Canadian accounting automation system manufacturer.