 It is convenient to photograph a page from a passport, a business card of a colleague, an agreement with a bank or a check from a restaurant on a smartphone. Important documents are always close at hand and can be printed or sent. But quickly finding the files you need in the mobile phone gallery is becoming increasingly difficult. As a rule, users accumulate a whole collection of memes and pictures with cats mixed with photos of electricity bills, SNILS, etc. Employees of companies, for example, field managers of a bank or a law firm, also have similar situations. Only instead of pictures of pussies - hundreds of photographs of customer agreements and other documents. How to find the necessary copy to send to colleagues in the office, or how to print a photo of a driver's license in the correct scale, and not on the whole A4? We'll have to tinker.
It is convenient to photograph a page from a passport, a business card of a colleague, an agreement with a bank or a check from a restaurant on a smartphone. Important documents are always close at hand and can be printed or sent. But quickly finding the files you need in the mobile phone gallery is becoming increasingly difficult. As a rule, users accumulate a whole collection of memes and pictures with cats mixed with photos of electricity bills, SNILS, etc. Employees of companies, for example, field managers of a bank or a law firm, also have similar situations. Only instead of pictures of pussies - hundreds of photographs of customer agreements and other documents. How to find the necessary copy to send to colleagues in the office, or how to print a photo of a driver's license in the correct scale, and not on the whole A4? We'll have to tinker.
It is much easier to accomplish all these tasks with one application. That is why we have updated ABBYY FineScanner AI . Now he is able to automatically sort photos from the smartphone gallery into 7 groups of documents and quickly searches for the necessary photos by text queries.
Today we will tell you in detail how we created each of these features, what technologies we used, and how the ABBYY NeoML framework helped in this. We will also show how it works in the application. And at the end - we will share our plans for the development of FineScanner and ask you a few questions.
Put everything on the shelves of daddies
According to a study by Appsflyer , mobile device usage and app downloads, including non- gaming , skyrocketed in 2020. To work together remotely, employees need not only corporate messengers, but also convenient mobile tools for efficient information processing, printing, remote workflow and data storage.
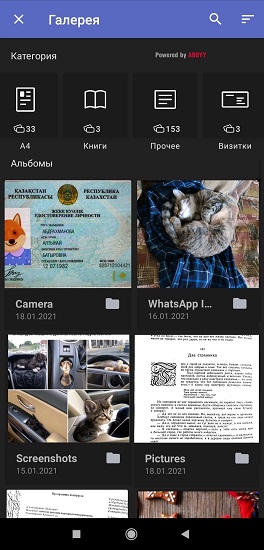
According to polls of FineScanner users and interviews with them, most often single and multi-page A4 pages (contracts, invoices, official letters, etc.), passports and driver's licenses, books, receipts and business cards are scanned using the application. 40% of respondents take photographs of documents about once a month, and 20% - once a week. Based on statistics, we have compiled a list of those types of documents that users most often shoot with a camera and store in the smartphone gallery for themselves or for work. And then we taught FineScanner to divide photos into groups. The process consists of two stages, takes place entirely in the background and does not require an Internet connection.
one). FineScanner first classifies photos from the user's gallery
After the first launch of the application and receiving all permissions from the user, the built-in neural networks automatically analyze photos on the smartphone and distribute them into 7 categories: A4 format, books, business cards, identity cards, receipts, handwritten text and “other” (posters, postcards are stored in this folder , color magazines, etc.).

Our neural network on the ABBYY NeoML engine , which we talked about in detail on Habré, is working on the intelligent classification of images . The mechanism consists of two neural networks: the first one detects the presence of text in the image, the second one determines the types of documents. The network architecture is based on MobilenetV3 blocks.
It was important for us to separate handwritten documents from printed ones, so the first grid divides files into 3 classes:
- image with handwritten text,
- image with printed text,
- image without text (cats, selfies and the environment).
In the first grid, we additionally used information about the center crop (a piece of the image from the center, cropped at high resolution) to determine the presence of text in the image. We took just such a crop, because in the sample (we'll talk about it a little below), in all the photos, the text was mainly in the central part. This image is fed along with the thumbnail to a separate branch of the network and helps it decide whether there is text in the picture or not.
The second grid defines the types of documents:
- A4 document (with a few drawings),
- 4 ( , — , ),
- ( - ),
- ( , , ),
- ,
- ID (, .) – , ,
- ( . ).
The dataset for training neural networks was collected and marked by our employees. The sample consisted of about 40 thousand photographs (business cards, flyers, bank cards, certificates, insurance, etc.) taken with a smartphone.
Due to the neural network, the weight of the application has increased insignificantly - by only 3MB. We specifically tried to make the neural network compact. I didn't want to bloat the application too much for the sake of such a somewhat "experimental" feature.
2). After classification, the text is recognized on the found photographs of documents.
To do this, we use our ABBYY Mobile Capture SDK technology , which works both in TextGrabber for OCR or video sequences, and in Business Card Reader for processing business cards. FineScanner has used this SDK before - for fast offline document recognition. This time we used it to the fullest: it can recognize text in thousands of pictures. Of course, we try to do it gently and carefully so that the process does not load the device and does not devour the battery. In addition, we have decided not to download the user's photos uploaded to the clouds for now, but process only those that are available locally on the device.
The total time for all processing of the gallery depends on the number of photos and documents among them, as well as on the generation of the phone and is on average 10-30 minutes for the first time. In the future, only new photographs will be scanned, and there will already be much less of them, not thousands of pieces.
Find a document by its text
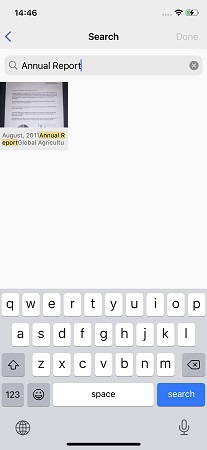 Sorting images by type is a good thing, but what if there are hundreds of images in the Books folder, and you need to find one, for example, a spicy shakshuka recipe photographed from a rare culinary encyclopedia? Or find in the A4 folder a rental agreement signed two years ago?
Sorting images by type is a good thing, but what if there are hundreds of images in the Books folder, and you need to find one, for example, a spicy shakshuka recipe photographed from a rare culinary encyclopedia? Or find in the A4 folder a rental agreement signed two years ago?
For such cases, we taught FineScanner how to search the text of the document. Moreover, the option with a search for an exact query, word for word, was discarded immediately. As a rule, it is not difficult to search for text on well-photographed documents, but in the gallery on a smartphone there can be anything - strongly rotated or blurred photos. It is not difficult to organize the so-called "clear search" according to them, but the results will be sad. Capitalization (using capital letters), of course, can and should be ignored, but there are, for example, spelling mistakes by users when writing a request.
In order for the application to swallow this spectrum of errors, we did a "fuzzy search". They were not going to write their own full-fledged search engine, so they looked at the existing approaches and libraries. As a result, to solve our problem came good diff algorithm Eugene Myers (Myer's diff algorithm).
The diff algorithm is not used for searching, but for comparing two texts or two versions of the same document.
They took the finished implementation from here . True, I had to add on top of it the calculation of the Levenshtein distance between the search query and the substring found and select thresholds so that there were no completely wild options. As a result, our text search works clearly, quickly and in real time.
AR ruler in iOS version, or how to determine the size of a document without dancing with a tambourine
 When we developed new features in FineScanner, we took into account the wishes of users. For example, they often need to print documents of not only the usual sizes (A4, A5, A6, business card), but also non-standard ones: leaflets, flyers, SNILS, etc. And with the printing of such files, difficulties arise: for example, the photo is stretched to the entire A4, although the original proportions are different.
When we developed new features in FineScanner, we took into account the wishes of users. For example, they often need to print documents of not only the usual sizes (A4, A5, A6, business card), but also non-standard ones: leaflets, flyers, SNILS, etc. And with the printing of such files, difficulties arise: for example, the photo is stretched to the entire A4, although the original proportions are different.
The most common document sizes can be selected from a ready-made list in the appendix, there are 8 types of them. Any others - postcards, visas, etc. - can now be measured automatically. To do this, we have integrated ARKit (line in augmented reality) into the new version of FineScanner for iOS. For its development, we used the Apple API in conjunction with our crop-module ABBYY Mobile Capture SDK, which allows you to define document boundaries even on a white background and complete them if they are closed by hand. The ruler determines the physical size of the document in order to specify it in the properties and get it correctly displayed on paper when printed on a printer.
This is how it works:
How our business customers use FineScanner
Our B2C clients will be the first to try the new functionality, and businesses will start using the application a little later. This is primarily due to strict corporate security policies.
Our customers from large companies use their versions of ABBYY FineScanner under the control of various MDM platforms (Mobile Device Management, that is, solutions that allow you to configure the levels of protection of corporate information from unauthorized access and distribution, and also determine whether information stored on a mobile device will be available for third-party applications). For example, PwC audit or business consulting staff use a mobile scannerfor fast digitization of any documents. During audits, they take photos of, for example, contracts or orders in just a few seconds, convert them to searchable PDF and send them to corporate repositories for additional verification and data analysis.
For the convenience of our customers, we are now preparing to release a version of FineScanner with support for the most popular MDM systems - Microsoft InTune, Mobile Iron, Workspace One and others.
For the future
We hope that the updated FineScanner will help simplify the tasks of digitizing and recognizing documents and books right on your smartphone, as well as quickly finding the files you need in the gallery and printing them.
We regularly collect user requests for FineScanner in order to understand how to develop the product further. According to our last survey, half of users send photographed documents to their own or another mail and continue to work with them on the computer, for example, print or store. Moreover, over 70% expect FineScanner to integrate with ABBYY FineReader PDF . It became interesting to us to find out what the Khabrovites think about it.