Description
Deep neural networks have proven to be effective in processing sensory data such as images and audio. However, for tabular data, tree models are more popular. A good property of tree models is their natural interpretability. In this paper, we present Deep Neural Decision Trees (DNDT) - tree models implemented by neural networks. DNDT is internally interpreted as it is a tree. However, since it is also a neural network (NN), it can be easily implemented with the NN toolkit and trained using a gradient descent algorithm rather than a greedy algorithm (a greedy partitioning algorithm). We evaluate DNDT on multiple tabular datasets, test its effectiveness, and explore the similarities and differences between DNDTs and conventional decision trees. Interesting,that DNDT is self-learning at both split and functional level.
Introduction
The interpretability of predictive models is important, especially when it comes to ethics - legal, medical and financial, mission-critical applications where we want to manually check the relevance of the model. Deep neural networks (Lecun et al., 2015 [18]; Schmidhuber, 2015 [25]) have achieved excellent results in many areas such as computer vision, speech processing, and language modeling. However, the lack of interpretability does not allow this family of models to be used in applications as a "black box" for which we need to know the forecast procedure in order to verify the decision-making process. Moreover, in some areas, such as business intelligence (BI), it is often more important to know how each factor affects the forecast, rather than the conclusion itself. Decision tree (DT) based methods such as C4.5 (Quinlan,1993 [23]) and CART (Breiman et al., 1984 [5]), have a clear advantage in this aspect, as the structure of the tree can be easily traced and precisely how the forecast is made.
– (DNDT), . DNDT- , DNDT . , DNDT (NN), , DT: DNDT NN; , «» . DNDT - GPU « », NN (back-propagation).
2.
. , , . / . C4. 5 (Quinlan, 1993 [23]) CART (Breiman et al., 1984 [5]). , , . , « » (Breiman, 2001 [6]) XGBoost (Chen & Guestrin, 2016 [8]), . .
. , , , (, ) , (Weller, 2017 [26]; Doshi-Velez, 2017 [11]). , (Bostrom & Yudkowsky, 2014 [4]) , , . . - (Ribeiro et al., 2016 [24]), , , (Dash et al., 2015 [10]; Malioutov et al., 2017 [19]), (Kim et al., 2016 [15]) (Kim et al., 2017 [16]).
. . Bul & Kontschieder (2014) [7] « » ( Neural Decision Forests NDF) , . Deep-NDF (Kontschieder et al., 2015 [17]) , ( CNNs) ( ). DNDT . -, () ( ). (back propagation). -, ( ), , (≥ 2) . , , , , . , (Bul & Kontschieder, 2014 [7]; Kontschieder et al., 2015 [17]) . . , Kontschieder et al. (2015 [17]), , , .
, (2017 [2]), «» , . «» , «» , , .
. DT «» (Quinlan, 1993; Breiman et al., 1984 [23]). , «» (Norouzi et al., 2015 [20]). , , (Norouzi et al., 2015 [20]) RNN (Xiong et al., 2017 [28]). , DNDT , , , DT, SGD. , , DT ( ), DNDT , .
3.
3.1.
, , - (Dougherty et al., 1995) (), DNDT. , x , . , .
, x, N + 1 . n , . [β1, β2,…, βn] , β1 < β2 < · · · < βn. β , . , β.
softmax.
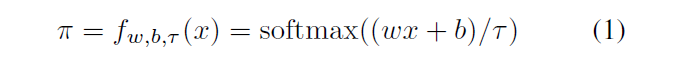
w- , , w = [1; 2; : : : ; n + 1]. b ,
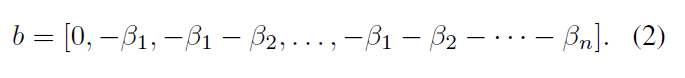
τ> 0 - . τ → 0 .
,



x

, 1 «» x, . , « » (Chung et al., 2017 [9]), , , , .
- «» ( ) , Straight-Through (ST) Gumbel-Softmax (Jang et al., 2017): , Gumbel-Max, (backward pass) Gumbel-Softmax (. Bengio (2013 [3]) .
.1 , x [0, 1] 0.33 0.66 . 1 2, o1 = x, o2 = 2x − 0.33, o3 = 3x − 0.99.
![Figure 1. A concrete example of our soft binning function using cut points at 0.33 and 0.66. The x-axis is the value of the continuous input variable x2 [0; one]. Top left: original logit values; top right: values after applying the softmax function with m = 1; Bottom left: t = 0.1; bottom right: t = 0.01.](https://habrastorage.org/getpro/habr/upload_files/ab5/1bd/c1f/ab51bdc1f73be966aff6556d810533d3.PNG "Figure 1. A concrete example of our soft binning function using cut points at 0.33 and 0.66. The x-axis is the value of the continuous input variable x2 [0; one]. Top left: original logit values; top right: values after applying the softmax function with m = 1; Bottom left: t = 0.1; bottom right: t = 0.01.")
3.2
, , ⊗. ,

xd fd (xd), ,
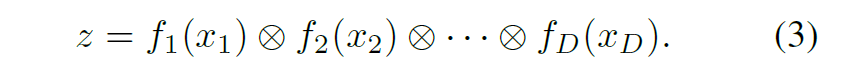
z «» , , x. , , z . DNDT . 2.
. : DNDT - , , – . : DT – , . 6 .")
3.3
. , . , (. 2, ) SGD.
. DNDT - . , - Kronecker . "" , «» (Ho, 1998 [13]) - . , . , «», : , . DNDT.
4.
4.1
DNDT ≈ 20 TensorFlow PyTorch. , DNDT " " GPU - , , .
4.2
DNDT ( TensorFlow (Abadi et al., 2015) [1]) ( Scikit-learn (Pedregosa et al., 2011 [22])) 14 , Kaggle UCI ( . . 1).
(DT) : 'gini' – 'best'. (NN) 50 . DNDT - ( ), 1 . 4.4. 12 , DNDT, 10 , 10 . .
4.3
DNDT, . 1. .2.
DT. DT , , .
) UCI: (#inst.), (#feat.) (#cl.)")
 , .")
, . DNDT , «» , . , , . , . « » (Wolpert, 1996[27]).
4.4
DNDT . , , , , xd, xd.
, DNDT. , . -Car Evaluation, Pima, Iris Haberman 1 5 , . 3. , . , DNDT : .
 , DNDT.")
, . . 4, , . , , DNDT , .
.")
4.5
DNDT , . , , DT, , - . , DNDT . DNDT 10 , - , .
- , , (, 0 iris) DNDT (. . 3 ). , DNDT , . () : , , , .
 of cases where DNDT ignores each function")
4.6
, 4.5, , DNDT DT . gini (), (. 5), (.3).
.")
, , DNDT DT , , Iris 3 . , , , DT 0 , DNDT . DNDT 2 , DT. . . 2, DNDT DT 70,9% 66,1% .
, DNDT DT, Tau . , .4, .

4.7 GPU
, DNDT - , DT. , , (. . 6).

5.
DNDT. , NN , . , DT, DNDT , SGD GPU. . ; DNDT , CNN, ; , SGD DNDT , «» DT ; , NN DT.
Abadi, Mart´ın, Agarwal, Ashish, Barham, Paul, Brevdo, Eugene, Chen, Zhifeng, Citro, Craig, Corrado, Greg S., Davis, Andy, Dean, Jeffrey, Devin, Matthieu, Ghemawat, Sanjay, Goodfellow, Ian, Harp, Andrew, Irving, Geoffrey, Isard, Michael, Jia, Yangqing, Jozefowicz, Rafal, Kaiser, Lukasz, Kudlur, Manjunath, Levenberg, Josh, Mane, Dandelion, Monga, Rajat, Moore, ´ Sherry, Murray, Derek, Olah, Chris, Schuster, Mike, Shlens, Jonathon, Steiner, Benoit, Sutskever, Ilya, Talwar, Kunal, Tucker, Paul, Vanhoucke, Vincent, Vasudevan, Vijay, Viegas, Fernanda, Vinyals, Oriol, Warden, Pete, Wattenberg, Martin, Wicke, Martin, Yu, Yuan, and Zheng, Xiaoqiang. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL https://www.tensorflow.org/.
Balestriero, R. Neural Decision Trees. ArXiv e-prints, 2017.
Bengio, Yoshua. Estimating or propagating gradients through stochastic neurons. CoRR, abs/1305.2982, 2013.
Bostrom, Nick and Yudkowsky, Eliezer. The ethics of artificial intelligence, pp. 316334. Cambridge University Press, 2014.
Breiman, L., H. Friedman, J., A. Olshen, R., and J. Stone, C. Classification and Regression Trees. Chapman & Hall, New York, 1984.
Breiman, Leo. Random forests. Machine Learning, 45(1): 5–32, October 2001.
Bul, S. and Kontschieder, P. Neural decision forests for semantic image labelling. In CVPR, 2014.
Chen, Tianqi and Guestrin, Carlos. Xgboost: A scalable tree boosting system. In KDD, 2016.
Chung, J., Ahn, S., and Bengio, Y. Hierarchical Multiscale Recurrent Neural Networks. In ICLR, 2017.
Dash, S., Malioutov, D. M., and Varshney, K. R. Learning interpretable classification rules using sequential rowsampling. In ICASSP, 2015.
Doshi-Velez, Finale; Kim, Been. Towards a rigorous science of interpretable machine learning. ArXiv e-prints, 2017.
Dougherty, James, Kohavi, Ron, and Sahami, Mehran. Supervised and unsupervised discretization of continuous features. In ICML, 1995.
Ho, Tin Kam. The random subspace method for constructing decision forests. IEEE Transactions on Pattern Analysis and Machine Intelligence, 20(8):832–844, 1998.
Jang, E., Gu, S., and Poole, B. Categorical Reparameterization with Gumbel-Softmax. In ICLR, 20
Kim, B., Gilmer, J., Viegas, F., Erlingsson, U., and Wattenberg, M. TCAV: Relative concept importance testing with Linear Concept Activation Vectors. ArXiv e-prints, 2017.
Kim, Been, Khanna, Rajiv, and Koyejo, Sanmi. Examples are not enough, learn to criticize! Criticism for interpretability. In NIPS, 2016.
Kontschieder, P., Fiterau, M., Criminisi, A., and Bul, S. R. Deep neural decision forests. In ICCV, 2015.
Lecun, Yann, Bengio, Yoshua, and Hinton, Geoffrey. Deep learning. Nature, 521(7553):436–444, 5 2015.
Malioutov, Dmitry M., Varshney, Kush R., Emad, Amin, and Dash, Sanjeeb. Learning interpretable classification rules with boolean compressed sensing. In Transparent Data Mining for Big and Small Data, pp. 95–121. Springer International Publishing, 2017.
Norouzi, Mohammad, Collins, Maxwell D., Johnson, Matthew, Fleet, David J., and Kohli, Pushmeet. Efficient non-greedy optimization of decision trees. In NIPS, 2015.
Paszke, Adam, Gross, Sam, Chintala, Soumith, Chanan, Gregory, Yang, Edward, DeVito, Zachary, Lin, Zeming, Desmaison, Alban, Antiga, Luca, and Lerer, Adam. Automatic differentiation in pytorch. In NIPS Workshop on Autodiff, 2017.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
Quinlan, J. Ross. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers Inc., 1993.
Ribeiro, Marco Tulio, Singh, Sameer, and Guestrin, Carlos. ”why should i trust you?”: Explaining the predictions of any classifier. In KDD, 2016.
Schmidhuber, J. Deep learning in neural networks: An overview. Neural Networks, 61: 85-117, 2015.
Weller, Adrian. Challenges for transparency. In ICML Workshop on Human Interpretability in Machine Learning, pp. 55–62, 2017.
Wolpert, David H. The lack of a priori distinctions between learning algorithms. Neural Computation, 8 (7): 1341-1390, 1996.
Xiong, Zheng, Zhang, Wenpeng, and Zhu, Wenwu. Learning decision trees with reinforcement learning. In NIPS Workshop on Meta-Learning, 2017.