The usual way of paging is by offset or page number. You make a request like this:
GET /api/products?page=10 {"items": [...100 products]}
and then this:
GET /api/products?page=11 {"items": [...another 100 products]}
In the case of a simple displacement, it turns out
?offset=1000
and
?offset=1100
- the same eggs, only in profile. Here we either go straight to the SQL query of the type
OFFSET 1000 LIMIT 100
, or multiply by the page size (value
LIMIT
). This is not an optimal solution anyway, as every database must skip those 1000 rows. And to skip them, you need to identify them. It doesn't matter if it's PostgreSQL, ElasticSearch, or MongoDB, it has to order, recalculate, and throw them away.
This is unnecessary work. But it repeats itself over and over again, since this design is easy to implement - you directly map your API to a database request.
What then is to be done? We could see how the databases work! They have a concept of a cursor - it is a pointer to a string. So you can tell the database, "Give me back 100 rows after this ." And such a query is much more convenient for the database, since there is a high probability that you are identifying a row by a field with an index. And you don't have to fetch and skip these lines, you will walk right by them.
Example:
GET /api/products {"items": [...100 products], "cursor": "qWe"}
The API returns a (opaque) string, which can then be used to get the next page:
GET /api/products?cursor=qWe {"items": [...100 products], "cursor": "qWr"}
In terms of implementation, there are many options. Typically, you have some query criteria, such as a product id. In this case, you encode it with some reversible algorithm (say hash identifiers ). And when you receive a query with a cursor, you decode it and generate a query like
WHERE id > :cursor LIMIT 100
.
Small performance comparison. Here is the result of the offset: And here is the result of the operation : A difference of several orders of magnitude! Of course, the actual numbers depend on the size of the table, filters, and storage implementation. Here is a great article
=# explain analyze select id from product offset 10000 limit 100;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1114.26..1125.40 rows=100 width=4) (actual time=39.431..39.561 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1274406.22 rows=11437243 width=4) (actual time=0.015..39.123 rows=10100 loops=1)
Planning Time: 0.117 ms
Execution Time: 39.589 ms
where
=# explain analyze select id from product where id > 10000 limit 100;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..11.40 rows=100 width=4) (actual time=0.016..0.067 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1302999.32 rows=11429082 width=4) (actual time=0.015..0.052 rows=100 loops=1)
Filter: (id > 10000)
Planning Time: 0.164 ms
Execution Time: 0.094 ms
for more technical information, see slide 42 for performance comparison.
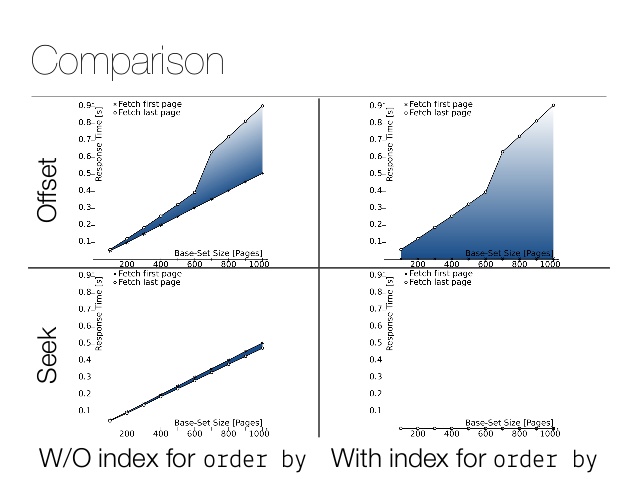
Of course, no one queries products by ID - they are usually queried for some sort of relevance (and then ID as a decisive parameter ). In the real world, choosing a solution requires looking at specific data. Requests can be ordered by identifier (as it increases monotonically). Items from the list of future purchases can also be sorted in this way - by the time the list was compiled. In our case, the products are loaded from ElasticSearch, which naturally supports such a cursor.
The downside is that you can't create a Previous Page link using the stateless API. In the case of user pagination, there is no way around this problem. So if it is important to have buttons for the previous / next page and "Go directly to page 10", then you have to use the old method. But in other cases, the by cursor method can significantly improve performance, especially on very large tables with very deep pagination.