Key points:
- Interaction between components directly with each other can lead to unexpected behavior that is difficult for developers, operators, and business analysts to understand.
- To ensure the sustainability of your business, you need to see all the interactions that arise in the system.
- : , -; , ; , ; (process mining), ; , .
- , , , .
In 2018, I met an architect from a large internet company. He told me that they follow all the correct guidelines and divide functionality into small chunks within different areas, although they don't call this architectural style "microservices." Then we talked about how these services interact with each other to support business logic that transcends service boundaries, because this is where theory is put into practice. He said that their services interact using events published on the bus - this approach is called " choreography " (I'll talk about it in more detail below). The company considers this to be optimal in terms of reducing cohesion. But they faced a problem: it is difficult to understand what is happening in the system, and it is even more difficult to change it. " This is not the choreographed dance you see in microservices presentations, this is uncontrollable pogo jumping! "
All this is in tune with what other clients have told me, for example, Josh Wolf of Credit Sense :" The system we are replacing uses complex peer-to-peer choreography that requires analysis of several codebases to understand. "

Let's understand this situation using a simplified example. Let's say you are building an order fulfillment application. You have chosen to use an event-driven architecture, and have chosen, say, Apache Kafka as the event bus. When someone places an order, the checkout service generates an event that is picked up by the payment service. This payment service receives money and generates an event that is picked up by the inventory service.
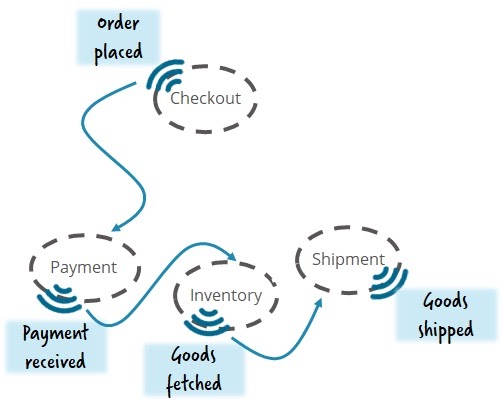
Choreographed stream of events.
The advantage of this approach is that you can easily add new components to the system. Let's say you want to create a notification service that sends emails to your customers. You can simply add a new service and subscribe to the appropriate events without touching the rest of the system. And now you can centrally manage the interaction settings and the complexity of notifications that meet the requirements of the GDPR (EU data protection regulation).

This style of architecture is called choreography because there is no need for an orchestrator to tell the other components what to do. Here, each component generates events to which other components can react. This style is supposed to reduce coupling between components and make it easier to design and modify the system, as is true for our notification service outline.
Loss of transparency in the flow of events
I want to focus on the question that comes up most often when I participate in discussions of this architecture: "How to avoid losing transparency (and probably control) of the flow of events?" In one study , Camunda (where I work) asked about using microservices. 92% of respondents have at least considered them, and 64% have already used them in one form or another. This is no longer a hype. But in that study, we also asked about the difficulties, and received a clear confirmation of our fears: most often we were told about the loss of end-to-end transparency of business processes involving multiple services.

Remember architectures based on multiple database triggers? Architectures in which you never know what exactly will happen in response to some action, and why will this happen? Sometimes I am reminded of this by the difficulties associated with reactive microservices, although such a comparison is clearly inappropriate.
Ensuring transparency
What can be done in such a situation? The following approaches will help you regain transparency, but each has its own merits and demerits:
- Distributed tracing (like Zipkin or Jaeger).
- Data lakes or analytical tools (like Elastic).
- Process mining control and analysis (e.g. ProM).
- Tracking using task flow automation (like Camunda).
Note that all of these approaches involve observing a running system and examining the data flows in it. I do not know of any static analysis tool that can extract useful information.
Distributed tracing
This approach monitors the call stack between different systems and services. For this, unique identifiers are used, usually added to certain headers (for example, in HTTP or message headers). If everyone on your system understands, or at least relays these headers, you can trace the exchange of requests between services.
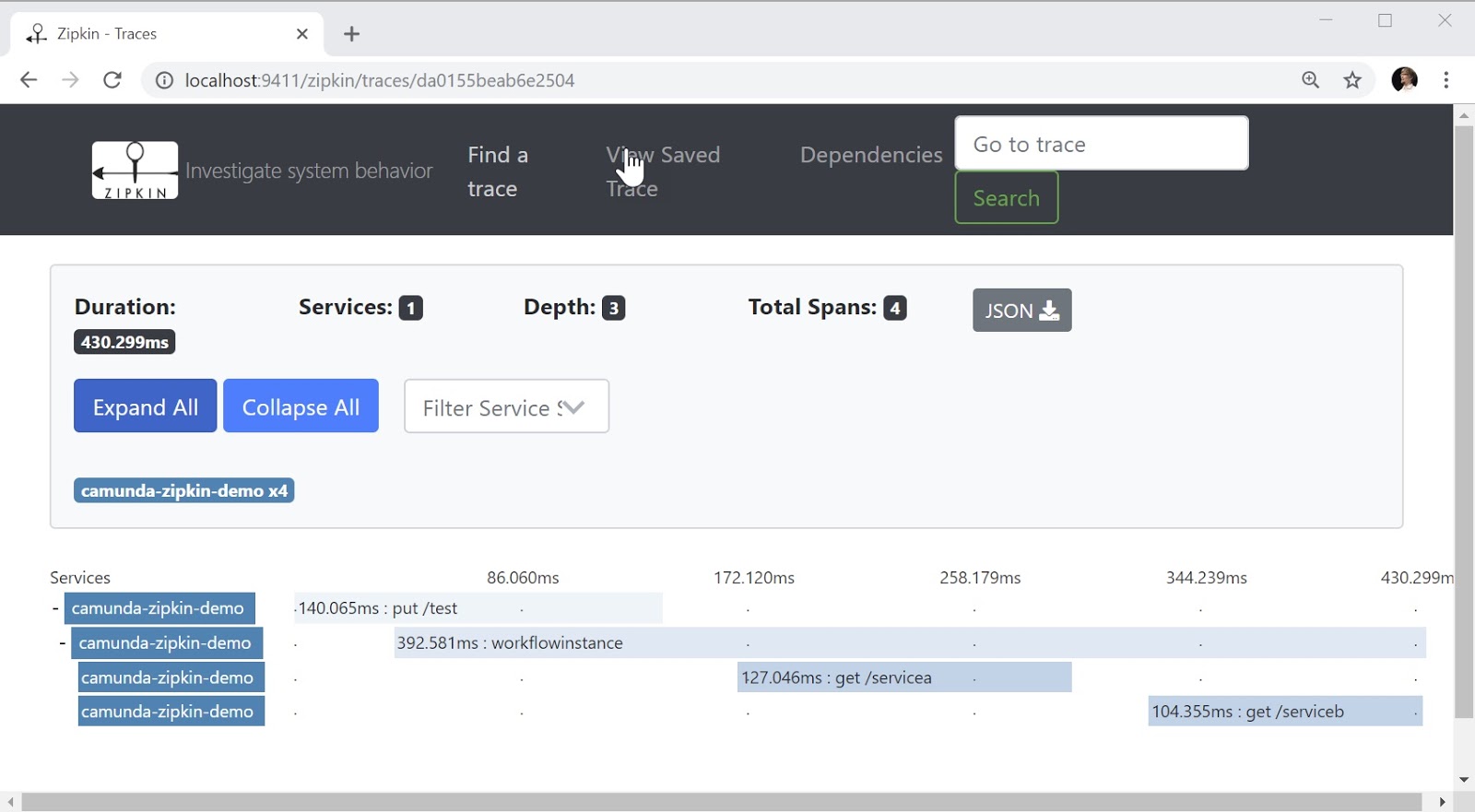
Typically, distributed tracing is used to understand how requests are flowing in the system, to find where there are failures and to investigate the causes of performance degradation. The advantages of the approach include the maturity of the toolkit and the living accompanying ecosystem. Therefore, it will be relatively easy for you to start using distributed tracing, even if you usually have to (perhaps aggressively) instruct your applications or containers.
So why not use this approach to understand how business processes generate events? There are usually two reasons for this:
- . , , . . , -.
- . , , 90 % . Three Pillars with Zero Answers — towards a New Scorecard for Observability. .
So, by itself, tracing is hardly suitable for us. It would be logical to turn to a similar approach, but taking into account our specific task. This usually means collecting not traces, but important business or thematic events that you may have already encountered. Often the solution comes down to creating a service that listens for all events and stores them in the database, which can increase the load on the system. Today many people use Elastic for this.
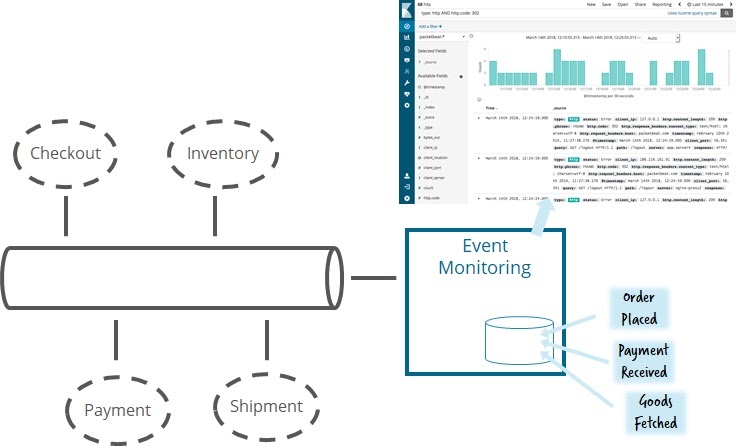
It is a powerful mechanism that is relatively easy to implement. And it has already been implemented by most of our event-driven clients. The main obstacle to implementation usually becomes the question of who in a large organization will manage such a tool, because it certainly needs to be managed centrally. It will be easy for you to create your own user interface to work with this mechanism, allowing you to quickly find information relevant to certain queries.

An example of an event monitoring interface .
The disadvantages include the lack of graphs that make it easier to work with the list of events. But you can add them to the infrastructure, say by projecting events into a renderer like BPMN. Small frameworks like bpmn.io allow you to add information to diagrams displayed as simple HTML pages ( example ) that can be packaged into the Kibana plugin.

This model cannot be executed with any business process management module, it is just a diagram used to visualize logged events. From this point of view, you have a certain freedom in choosing the display detail. And if you are especially interested in the full picture, then you can create models that show events from different microservices on one diagram. A diagram like this won't prevent you from making changes to individual services, so your company's flexibility won't be affected. But there is a risk that the diagrams will become outdated compared to the current state of the operating system.
Process mining tools
In the previous approach, you would have to explicitly model the diagram to be used for rendering. But if we cannot know in advance the nature of the flow of events, we must first investigate it.
This can be done using tools for monitoring and analyzing processes. They can create and graphically display a complete diagram, often allowing you to explore the details, especially related to system bottlenecks or potential optimizations.
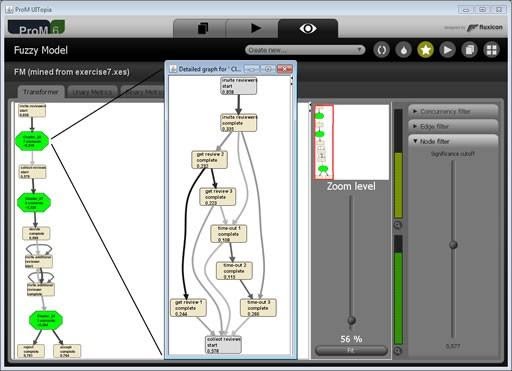
Sounds like the perfect solution to our problem. Unfortunately, such tools are most often used to investigate processes in legacy architectures, so they focus on analyzing logs and work mediocrely with live streams of events. Another disadvantage is that they are purely scientific tools that are difficult to use (eg ProM) or very heavyweight (eg Celonis). In my experience, it is impractical to use these types of tools in typical microservice endeavors.

In any case, process exploration and data analytics bring interesting opportunities for transparency in event flows and business processes. Hopefully there will soon be a technology with similar functionality, but lighter, more developer-friendly, and easier to implement.
Tracking with task flow automation
Another interesting approach is modeling task flows and then deploying and executing them through the control module. This model is special in the sense that it only tracks events, and does not actively do anything. That is, it does not manage anything - it only registers. I talked about this at the Kafka Summit San Francisco 2018 , using Apache Kafka and the open source Zeebe workflow module for demonstration .

This opportunity is especially interesting. There are many innovations in the field of control modules, which leads to the emergence of tools that are compact, easy to develop, and highly scalable. I wrote about this in Events, Flows and Long-Running Services: A Modern Approach to Workflow Automation . The obvious disadvantages include the need for preliminary modeling of the task flow. But on the other hand, this model can be executed using the process control module, in contrast to event monitoring. Basically, you start process instances for inbound events, or map events to an instance. It also allows you to check if the reality matches your model.
In addition, this approach allows you to leverage the entire tool chain provided by the task flow automation platform. You can see the actual state of the system, track SLAs, detect failures of process instances, or perform a thorough analysis of historical audit data.

An example of monitoring a task flow.
When I tested this approach with our clients, it was easy to set up. We just put together a generic component that receives events from the bus and matched it with the task flow control module. If the event could not be reconciled, we used a small decision table to determine whether it could be ignored or the event would lead to an incident that would have to be investigated later. We also improved the task flow control modules used within microservices to execute business logic so that they generate certain events (for example, a process instance is started, completed, or has completed some stage) that will be part of the big picture.
All of this is similar to event monitoring, but with an emphasis on business processes. Unlike tracing, the approach captures all business events and displays the big picture in different formats suitable for different stakeholders.
Business Outlook
The availability of business processes for monitoring allows you to understand the context. You can see for a specific instance how, when and in what state it ended. This means that you can understand which path this process did not follow (and others often follow it), and what events or data led to certain decisions. You can also understand what may happen in the near future. Other types of monitoring do not allow this. While it is often not customary today to discuss the issue of consistency between business and IT, it is imperative that non-specialists also be able to understand business processes and how events flow through different microservices.
From tracking to managing
Process tracking is a great tool to provide operational monitoring, reporting, KPIs and transparency; these are all important factors in maintaining the flexibility of the company. But in current projects, tracking is only the first step towards deeper management and orchestration in your microservices ecosystem.
For example, you can start by monitoring timeouts in end-to-end processes. When a timeout occurs, an action is automatically performed. In the example below, after 14 days we will notify the client about the delay, but we will still wait. And after 21 days we will cancel the order.
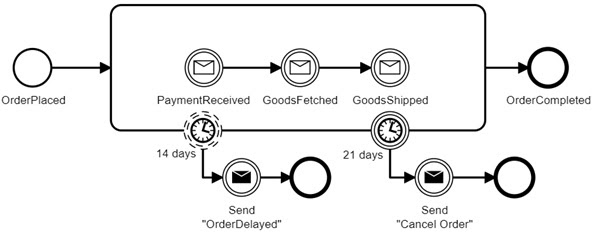
Curiously, sending a team to cancel an order here is orchestration that is often discussed in a controversial manner.
Orchestration
I often hear that orchestration should be avoided because it leads to coherency or disrupts the autonomy of individual microservices, and of course, it can be poorly implemented. But it is also possible to implement orchestration in a way that is consistent with the principles of microservices and brings great value to the business. I talked about this in detail at InfoQ New York 2018 .
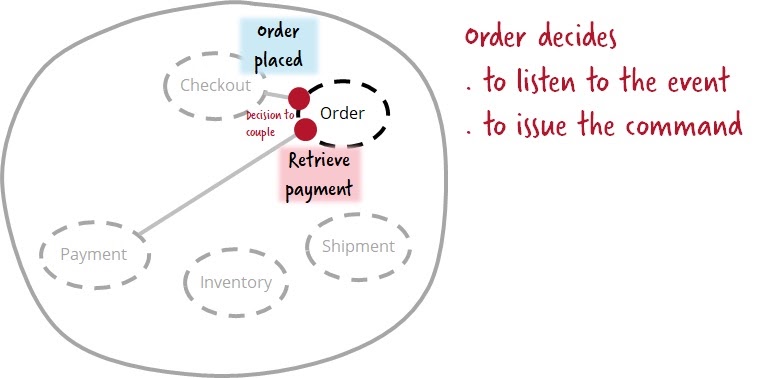
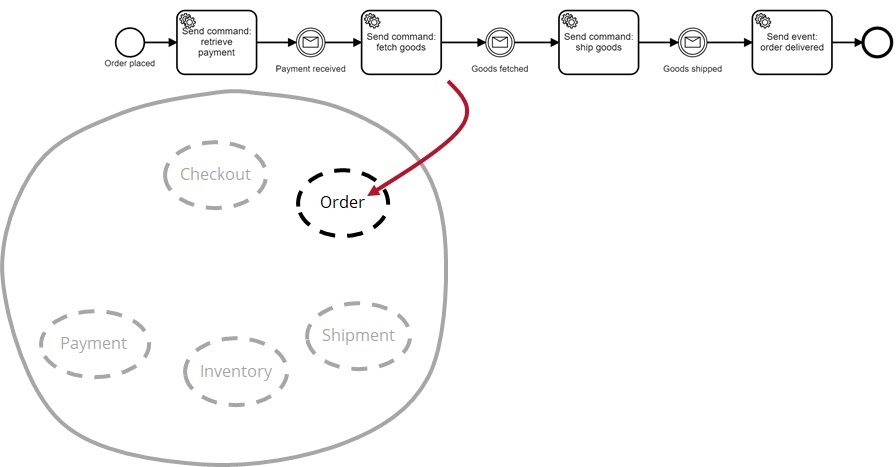
For me, orchestration means that one service can tell another to do something. And that's all. This is not a close connection, but a different kind of connection. Let's remember our example with an order. It might be advisable for the cash register service to just generate an order and put it on the event bus without knowing who will process it. The order service picks up the event about the order that has appeared. The recipient learns about the event and decides to do something about it. That is, the cohesion is present on the receiver's side.
With payment, the situation is different, since it is rather strange if the payment service knows what the payment has been received for. But he will need this knowledge in order to react to the right events like placing or placing an order. It also means that the service will have to be changed every time you want to receive payments for new products or services. In many projects, this unpleasant connection is bypassed by generating the necessary payment events, but these are not events, since the sender wants someone to do something about it. This is a team! The ordering service commands the payment service to receive money. In this case, the sender knows which command to send and does so, that is, the cohesion is present on the sender's side.
For every interaction between two services to be effective, it implies a certain degree of coupling. But depending on the specific task, it may be advisable to implement connectivity on one of the sides.
The order service may even be responsible for orchestration and other services, tracking the stages of order fulfillment. I discussed the benefits of this approach in detail in the above talk. The trick is that good architecture requires balancing orchestration and choreography, which is not always easy to do.
However, in this article, I wanted to focus on transparency. And there is an obvious advantage to orchestration using the task flow module: a model is not just code for the orchestrator to execute, it can be used to provide flow transparency.
Conclusion
It is very important to ensure the transparency of your business processes, regardless of their implementation. I considered different approaches, and in real projects everything usually comes down to some kind of event monitoring using tools like Elastic, or to tracking processes using control modules. In part, the choice may depend on the specific case and the roles of the people involved. For example, a business analyst needs to understand the data collected from all process instances with the required degree of detail, while an operations officer needs to analyze a specific process in varying degrees of detail and, probably, acquire tools to quickly resolve incidents at the system level.
If your project relies heavily on choreography, process tracking may lead you to add orchestration. And I think this is a very important step in maintaining long-term control over your business processes. Otherwise, you can "make a carefully decoupled event-driven system without realizing that you will lose transparency as the number of events and processes increases, and thereby provide yourself with problems in the years to come," as Martin Fowler said . If you are working on a completely new system, find a balance between orchestration and choreography from the beginning.
However, regardless of the specifics of the implementation of the system, make sure to provide the business with a clear display of the business processes implemented using the interacting services.