For some areas, such as NLP, the workhorse was Transformer, which requires huge amounts of GPU memory. Realistic models just don't fit in memory. The last method called Sharded [lit. 'segmented'] was introduced in Microsoft's Zero paper , in which they developed a method that brings humanity closer to 1 trillion parameters.
Especially for the start of a new course on Machine Learning, share with you an article on Sharded that shows you how to use it with PyTorch today to train models with twice the memory and in just a few minutes. This feature in PyTorch is now available through a collaboration between the FairScale Facebook AI Research and PyTorch Lightning teams .

Who is this article for?
This article is for anyone who uses PyTorch to train models. Sharded works on any model, no matter which model to train: NLP (transformer), visual (SIMCL, swav, Resnet) or even speech models. Here's a snapshot of the performance gain you can see with Sharded across all model types.
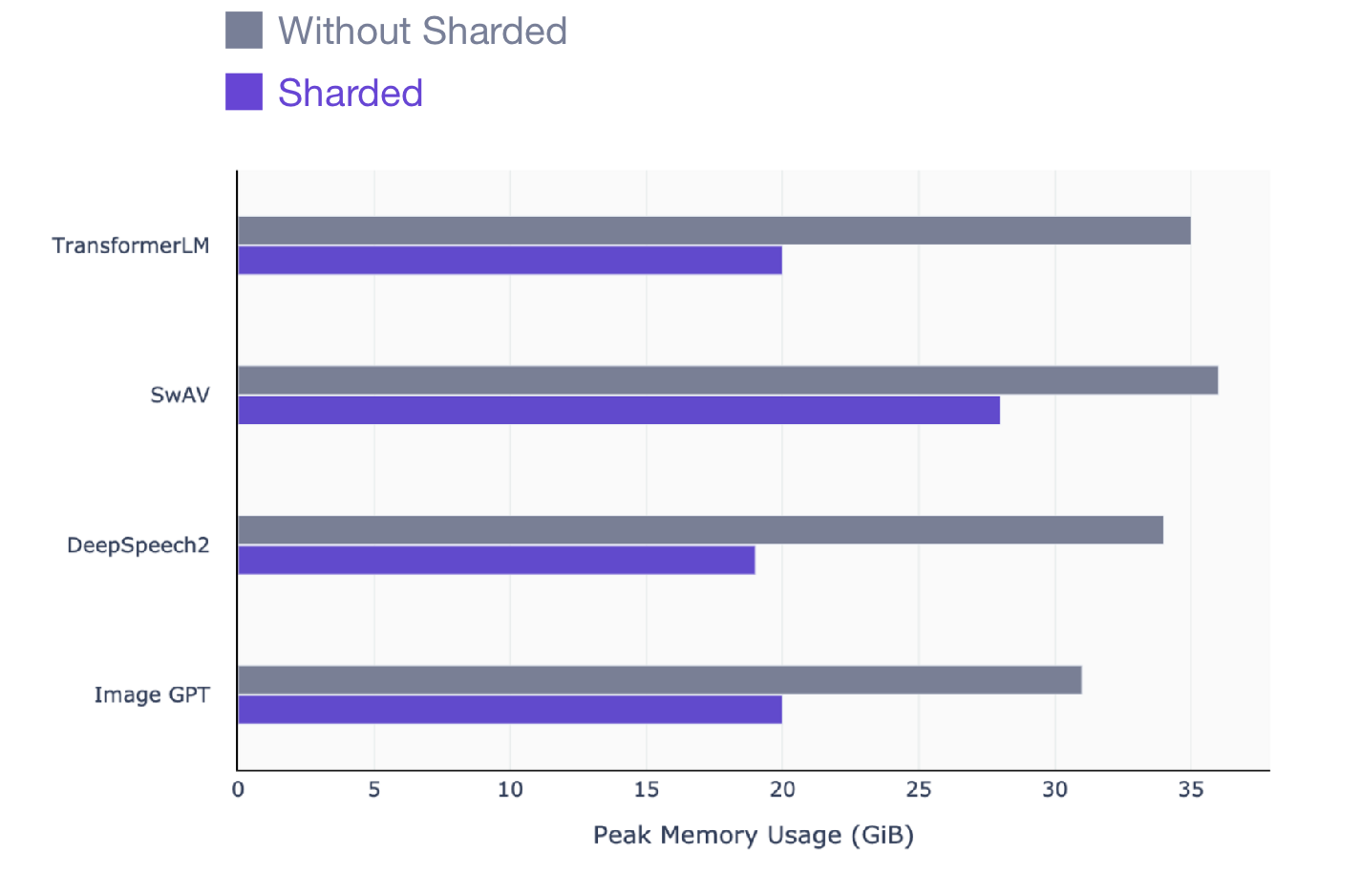
SwAV is a state-of-the-art data-driven learning method in computer vision.
DeepSpeech2 is a modern technique for speech models.
Image GPT is an advanced method for visual models.
Transformer is an advanced natural language processing technique.
How to use Sharded with PyTorch
For those who don't have much time to read the intuitive explanation of how Sharded works, I'll explain right away how to use Sharded with your PyTorch code. But I urge you to read the end of the article to understand how Sharded works.
Sharded is designed to be used with multiple GPUs to take full advantage of the available benefits. But training on multiple GPUs can be daunting and very painful to set up.
The easiest way to charge your code with Sharded is to convert your model to PyTorch Lightning (this is just a refactoring). Here is a 4 minute video that shows you how to convert your PyTorch code to Lightning.
Once you've done that, enabling Sharded on 8 GPUs is as easy as changing a single flag: no changes to your code are required.

If your model is from another deep learning library, it will still work with Lightning (NVIDIA Nemo, fast.ai, Hugging Face). All you need to do is import the model into LightningModule and start learning.
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
Intuitive explanation of how Sharded works
Several approaches are used to effectively train on a large number of GPUs. In one approach (DP), each package is split between GPUs. Here is a DP illustration where each part of the package is sent to a different GPU and the model is copied multiple times to each one.

DP Training
This approach is bad, however, because the model weights are transmitted through the device. In addition, the first GPU supports all optimizer states. For example, Adam keeps an additional complete copy of your model's weights.
In another technique (parallel data distribution, DDP), each GPU is trained on a subset of the data and the gradients are synchronized between the GPUs. This method also works on many machines (nodes). In this figure, each GPU receives a subset of the data and initializes the same model weights for all GPUs. Then, after the back pass, all gradients are synchronized and updated.
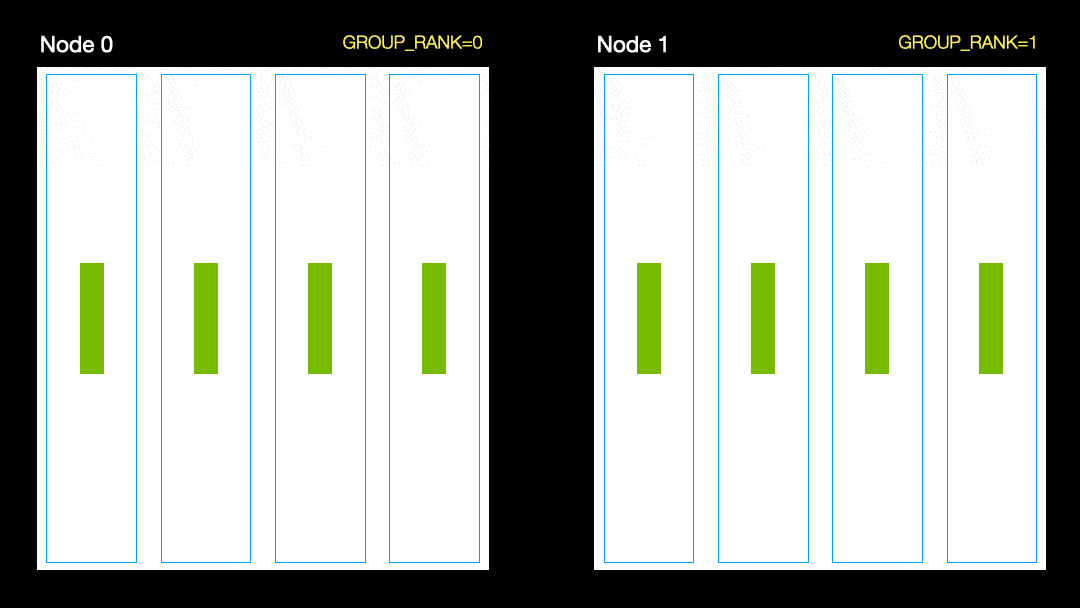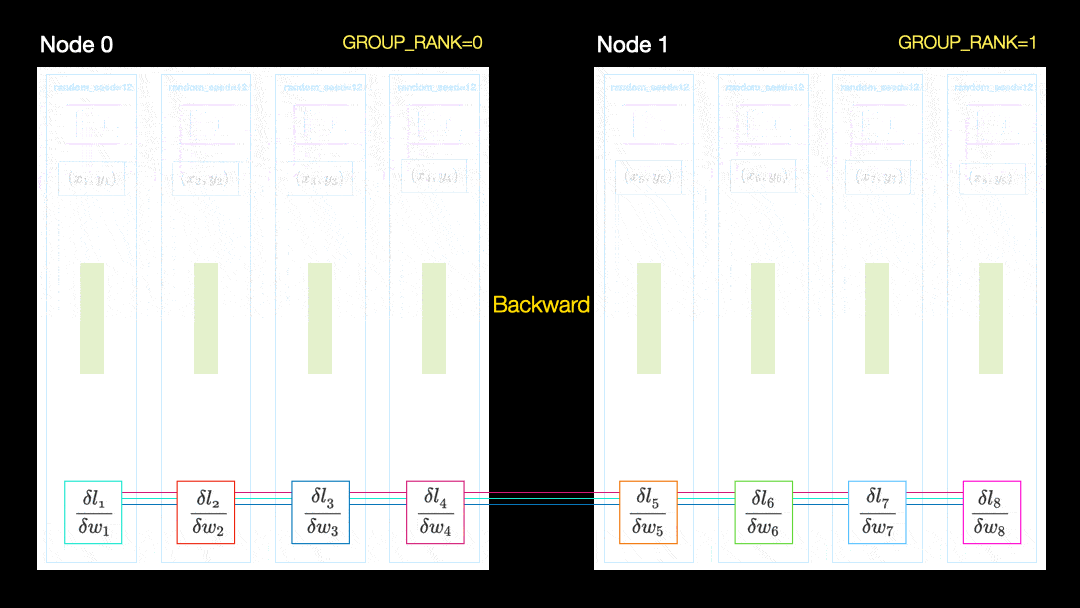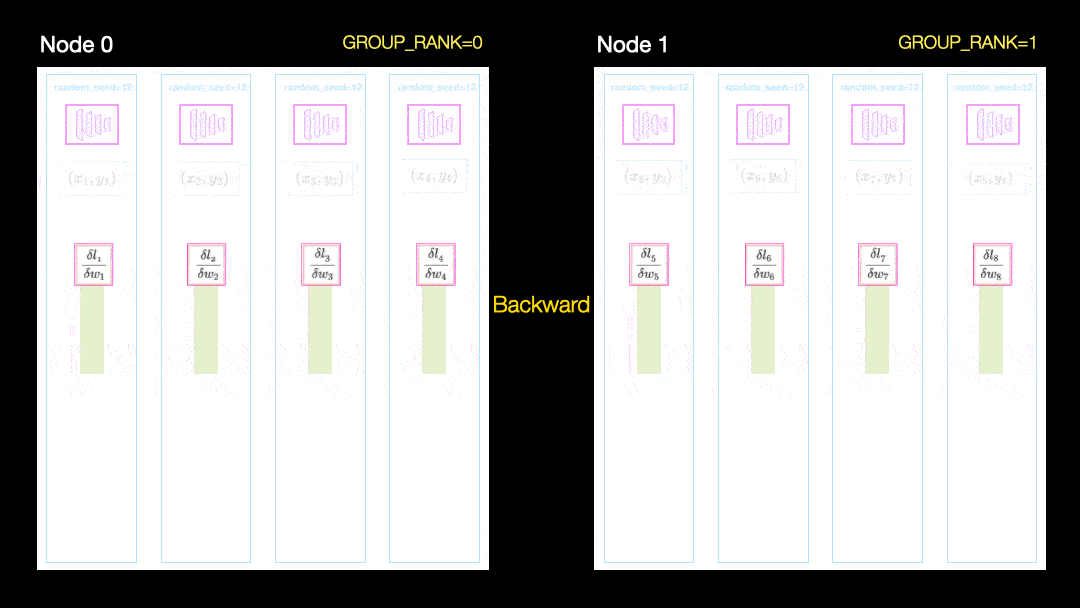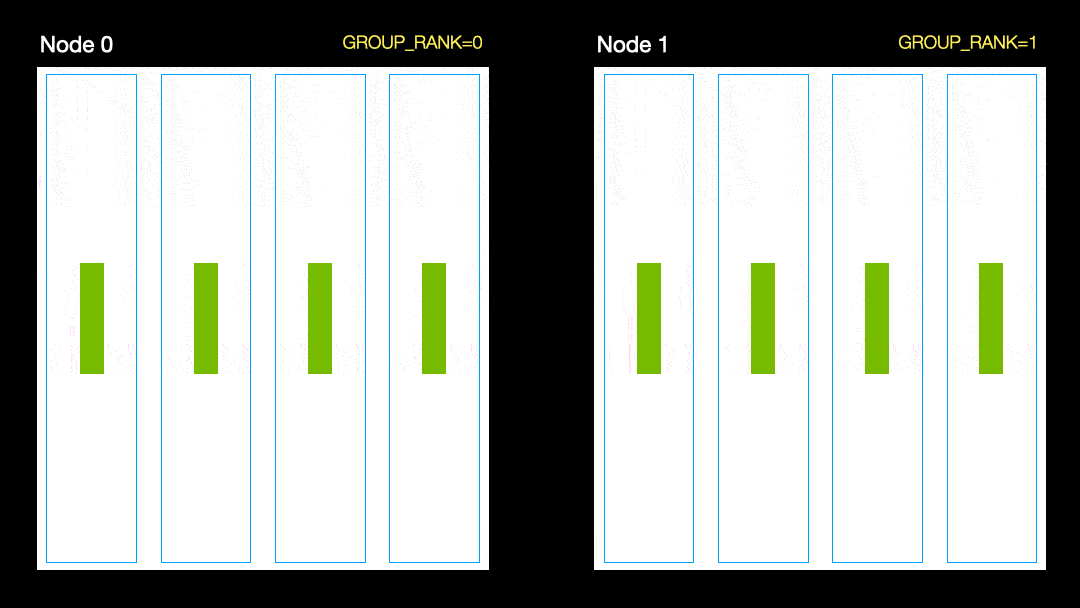
Parallel data distribution
However, this method still has a problem, which is that each GPU must maintain a copy of all optimizer states (about 2-3 times the model parameters), as well as all forward and backward activations.
Sharded removes this redundancy. It works in the same way as DDP, except that all overhead (gradients, optimizer state, etc.) is calculated for only a fraction of the total parameters, and thus we eliminate the redundancy of storing the same gradient and states optimizer on all GPUs. In other words, each GPU stores only a subset of activations, optimizer parameters, and gradient calculations.
Using some kind of distributed mode

In PyTorch Lightning, switching distribution modes is trivial.
As you can see, with any of these optimization approaches, there are many ways to get the most out of distributed learning.
The good news is that all of these modes are available in PyTorch Lightning without the need for code changes. You can try any of them and adjust if necessary for your specific model.
One method that is not there is the parallel model. However, this method should be warned as it has proven to be much less effective than segmented training and should be used with caution. It might work in some cases, but in general it is best to use sharding.
The advantage of using Lightning is that you never fall behind the latest advances in AI research! The open source team and community are committed to sharing the latest advances with Lightning through Lightning.

- Machine Learning Course
- Data Science profession training
- Data Analyst training
Other professions and courses
PROFESSION
- Java developer profession
- Frontend-
- -
- C++
- Unity
- iOS-
- Android-
- «Python -»
- JavaScript
- « Machine Learning Data Science»
- «Machine Learning Pro + Deep Learning»
- DevOps