At dentsu, we came up with Podcaster, an analytical tool for measuring podcast audiences and planning ads in them. How we started collecting data and solved the problem of audience recognition, what difficulties we encountered and what came of it, we will tell you in this article.

Background
Podcast scheduling is now based on data from sellers (studios or specialist agencies) who contact podcast authors and request a description of the listeners. The podcasters themselves receive data either from the platform on which the podcast is posted or from an external statistics system. There are a number of limitations in this approach:
- podcasts can be selected from a limited list, with which the seller has agreements and has data on the podcast audience;
- there is no possibility to choose more affinitive podcasts (affinity is the ratio of a given target audience among listeners to all podcast listeners), because, as a rule, a description of the core of listeners is available, and it is generally the same in terms of age for most podcasts;
- podcasters themselves have data on each podcast, but neither the podcasters themselves nor the sellers know how the listeners overlap between the podcasts.
In order to make scheduling of podcasts smarter, we tried to form a unified analytics system that would be based on data from the list of existing podcasts and the base of users listening to these podcasts, as well as it would be possible to determine the gender and age of these same listeners.
An approach
We quickly realized that we wouldn't be able to get user-specific auditions ourselves. But there are podcast likes / subscribers: a similar mechanic works, for example, on Instagram with bloggers, when a person subscribes to a blogger to see his news. We assumed that the same story is happening with podcasts - listeners subscribe to their favorite podcasts so that they are quickly accessible and can follow new episodes.
We decided to test this hypothesis using a popular platform through which the audience listens to podcasts. According to Tiburon, Yandex.Music is the leader in listening to podcasts.
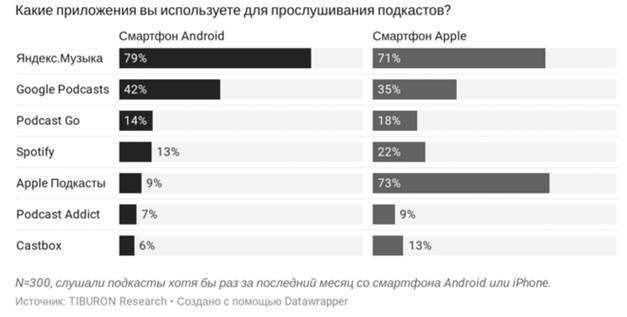
Fortunately, Ya Music has a user page that provides information about podcast subscriptions.
An example of a profile with a photo and subscriptions to podcasts
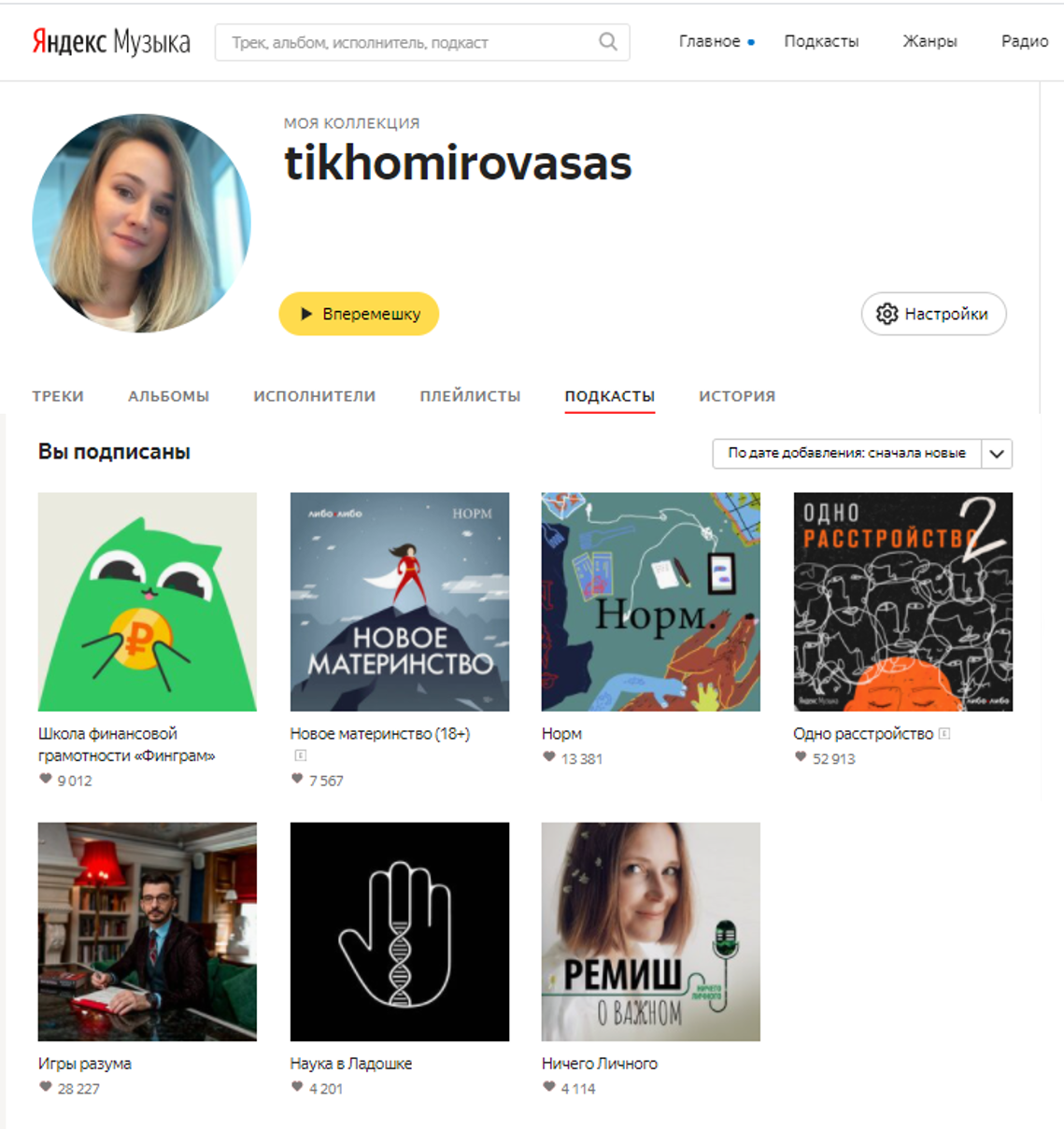
In addition to the subscription itself, there is a nickname and user avatar in the public domain. This is already something, since in fact we see the core of podcast listeners, that is, those who regularly listen to them. Also here we have the very user-podcast link that we wanted to find.
Mechanics
We started collecting data, namely users and podcasts that listeners subscribed to. Initially, we found Ya.Muzyka users with podcasts on the data of dentsu employees who provided their mailboxes on Yandex. It was not difficult to scale the project, since we have been working with public data for several years.
The good news was that the podcast subscriber base was gathering very quickly - in just a month and a half we got more than 10,000 users who subscribed to at least one podcast.
But there was also bad news - it is not always possible to determine gender and age by eye by photo and nickname, or rather, it is impossible at all. For us, in order to be able to select relevant podcasts for different audiences, we cannot do without gender and age. Our neural network
coped with this task of determining gender and age from a photograph , the accuracy of which is 96%. The algorithm is simple: we take a photo of the user J. Music, look for a face and use it to determine gender and age. The face is found by the face-recognition library
using dlib. And at the heart of our neural network is the pre-trained VGGFace model based on the ResNet-50 architecture, which we have trained on the photos of VK users, available through the public API. The dataset consists of a million photographs that have been additionally augmented through albumentations. It should be noted that we do not consider photographs of users under 12 and over 65 for training purposes.
results
After training, we realized that in about 45% of user profiles with podcasts, we can determine gender and age, since there are many profiles without a photo or a picture, a symbol or just a poor quality photo. But even this result suits us.
Taking into account the dynamics of finding profiles that subscribe to podcasts, we expect that in a few months the listener base will be 50,000 profiles, and 22,500 of them will have gender and age.
Example of a profile by which we cannot determine gender and age.
Current developments allow us to make samples of affinitive podcasts for different audience groups.
A selection of 20-50 podcasts in topics that are relevant to the brand

Affinity = target audience among podcast listeners / all podcast listeners) / (all podcast listeners / all people with podcasts)
We can also analyze a specific podcast if the advertiser is interested in it.
By seeing how many people are subscribed to podcasts, we can make recommendations on the podcast package that will build the greatest reach.
Coverage curve for 50 selected podcasts
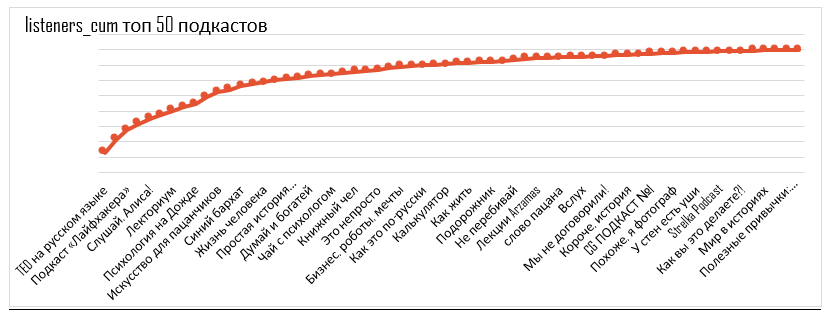
Each point +1 podcast per mix. The first dot is the podcast with the largest unique audience, the last dot is the podcast with the smallest unique audience.
Curve mechanics and mathematical model
First, we take the podcast that has a larger audience, in our case it is podcast 3. Below is a table in which the brute force logic is revealed, that is, the principle of distributing conciliators among podcasts.

Next, we cross out the listeners we reach with podcast 3, and again select the podcast with the most unique audience (podcast 4). This is a podcast that gives us 2 new unique listeners, so we recommend placing it next.

We repeat the exercise, and it turns out that we will not cover more unique listeners, that is, placement in 2 out of 6 podcasts is enough to cover all possible unique audience.

conclusions
We didn't answer all the questions, so we continue to search for data. For example, recently Ya.Muzyka began publishing information about the number of subscribed audience for each of the podcasts. Now we understand the volume of the collected listeners from the total.
We are working on the mechanics of combining subscription data with data from sites and podcasters to refine the model for estimating the number and composition of listeners. But already now, our approach is helping to change the scheduling scheme for advertising integrations in podcasts and proceed not from aggregated data of sellers or advertisers' intuition about the podcast audience, but from the brand audience. And also to compose podcast packages that are relevant specifically for this brand audience and build the maximum reach for it.
Author Sasha_Kopylova