Hello! My name is Dmitry Shelamov and I work at Vivid.Money as a backend developer in the Customer Care department. Our company is a European startup that creates and develops internet banking services for European countries. This is an ambitious task, which means that its technical implementation requires a well-thought-out infrastructure that can withstand high loads and scale according to business requirements.
The project is based on a microservice architecture, which includes dozens of services in different languages. These include Scala, Java, Kotlin, Python, and Go. The latter is where I write the code, so the practical examples in this series will use mostly Go (and some docker-compose).
Working with microservices has its own characteristics, one of which is the organization of communications between services. The interaction model in these communications can be synchronous or asynchronous and can have a significant impact on the performance and fault tolerance of the system as a whole.
Asynchronous communication
So, let's imagine that we have two microservices (A and B). We will assume that communication between them is carried out through the API and they do not know anything about the internal implementation of each other, as prescribed by the microservice approach. The format of the data transferred between them is pre-agreed.
The task before us is the following: we need to organize the transfer of data from one application to another and, preferably, with minimal delays.
In the simplest case, the task is achieved by synchronous interaction, when A sends a request to application B, after which service B processes it and, depending on whether the request was successfully or not successfully processed, sends a responseservice A that expects this response.
If the response to the request has not been received (for example, B breaks the connection before sending the response, or A falls off by timeout), service A can repeat its request to B.
On the one hand, such an interaction model gives a certainty of the data delivery status for each request when the sender knows for sure whether the data was received by the recipient and what further actions he needs to do depending on the response.
On the other hand, the price to pay is waiting. After sending a request, service A (or the thread in which the request is executed) is blocked until it receives a response or considers the request to be unsuccessful according to its internal logic, after which it takes further action.
The problem is not only that waiting and downtime take place, but delays in network communication are inevitable. The main problem is the unpredictability of this delay. Participants in the communication in the microservice approach do not know the details of each other's implementation, therefore, it is not always obvious to the requesting party whether its request is being processed normally or whether the data needs to be resent.
All that remains with this model of interaction is simply to wait. Maybe a nanosecond, maybe an hour. And this figure is quite real if B, in the process of data processing, performs any heavy operations, such as video processing.
Perhaps the problem did not seem significant to you - one piece of iron is waiting for the other to answer, is the loss great?
To make this problem more personal, imagine that service A is an application running on your phone and while it is waiting for a response from B, you see a loading animation on the screen. You cannot continue using the application until service B responds, and you have to wait. Unknown amount of time. Given that your time is much more valuable than the running time of a piece of code.
Such roughness is solved as follows - you divide the interaction participants into two "camps": some cannot work faster, no matter how you optimize them (video processing), while others cannot wait longer than a certain time (application interface on your phone).
Then you replace the syncthe interaction between them (when one part is forced to wait for the other to make sure that the data has been delivered and processed by the recipient service) to asynchronous , that is, the model of work is sent and forgotten - in this case, service A will continue its work without waiting for a response from B.
But how can you ensure that the transfer was successful in this case? You cannot, for example, after uploading a video to a video hosting service, display a message to the user: “your video may be processed, but it may not be,” because the service that downloads the video has not received confirmation from the service-processor that the video has reached him without incident.
As one of the solutions to this problem, we can add a layer between services A and B, which will act as a temporary storage and guarantor of data delivery at a rate convenient for the sender and receiver. Thus, we can decouple services, the synchronous interaction of which can potentially be problematic:
- Data that is lost when the receiving service ends abnormally can now be retrieved from the staging store again while the sending service continues to do its work. Thus, we get a delivery guarantee mechanism ;
- This layer also protects recipients from load surges, because the recipient is given data as it is processed, and not as it arrives;
- Requests for heavyweight operations (such as video rendering) can now be passed through this layer, providing less connectivity between the fast and slow parts of the application.
An ordinary DBMS is quite suitable for the above requirements. Data in it can be stored for a long time without worrying about loss of information. The overload of recipients is also excluded, because they are free to choose the pace and volumes of reading the records intended for them. The confirmation of processing can be realized by marking the read records in the corresponding tables.
However, choosing a DBMS as a data exchange tool can lead to performance problems as the workload increases. This is because most databases are not designed for this use case. Also, many DBMS lacks the ability to separate connected clients into recipients and senders (Pub / Sub) - in this case, the data delivery logic must be implemented on the client side.
We probably need something more specialized than a database.
Message brokers
A message broker (message queue) is a separate service that is responsible for storing and delivering data from sender services to recipient services using the Pub / Sub model.
This model assumes that asynchronous communication follows the following logic of two roles:
- Publishers publish new information as messages grouped by some attribute;
- Subscribers subscribe to message streams with specific attributes and process them.
The message grouping attribute is the queue , which is needed to separate the data streams - thus, recipients can subscribe only to those message groups that interest them.
Similar to subscribing to various content platforms - by subscribing to a specific author, you can filter content by choosing to watch only the one that interests you.

The queue can be thought of as a communication channel stretched between the writer and the reader. Writers put messages on a queue, after which they are “pushed” to readers who have subscribed to that queue. One reader receives one message at a time, after which it becomes inaccessible to other readers.
A message is a unit of data, usually consisting of a message body and broker metadata.
In general, a body is a collection of bytes in a specific format.
The recipient must know this format in order to be able to deserialize its body for further processing after receiving a message.
You can use any convenient format, however, it is important to remember about backward compatibility, which is supported, for example, by the binary Protobuf and the Apache Avro framework.
Most message brokers based on AMQP (Advanced Message Queuing Protocol) work according to this principle, a protocol that describes a standard for fault-tolerant messaging through queues.
This approach provides us with several important advantages:
- Weak cohesion. It is achieved through asynchronous message transmission: that is, the sender drops the data and continues to work without waiting for a response from the receiver, and the receiver reads and processes messages when it is convenient for him, and not when they were sent. In this case, the queue can be compared to a mailbox in which the postman puts your letters, and you pick them up when it suits you.
- . , ( , ), - .
, . - . - . , , : , , , -, .
- . “at least once” “at most once”.
At most once eliminates reprocessing of messages, but allows them to be lost. In this case, the broker will deliver messages to recipients on a “send and forget” basis. If the recipient was unable for some reason to process the message on the first attempt, the broker will not re-send it.
At least once , on the other hand, guarantees that the recipient will receive the message, but there is the possibility that the same messages will be processed again.
Often this guarantee is achieved using the Ack / Nack (acknowledgment / negative acknowledgment) mechanism , which prescribes to re-send a message if the recipient, for some reason, could not process it.
Thus, for every message sent by the broker (but not yet processed), there are three final states - the receiver returned Ack (successful processing), returned Nack (unsuccessful processing), or dropped the connection. The last two scenarios result in message re-sending and re-processing.
However, the broker can resend the message even if the receiver successfully processes the message. For example, if the recipient processed the message, but exited without sending an Ack signal to the broker.
In this case, the broker will put the message into the queue again, after which it will be processed again, which can lead to errors and data corruption if the developer has not provided a mechanism for eliminating duplicates on the recipient's side.
It's worth noting that there is another delivery guarantee called “exactly once” . It is difficult to achieve in distributed systems, but it is also the most desirable.
In this regard, Apache Kafka, which we will talk about later, stands out favorably against the background of many solutions available on the market. Since version 0.11, Kafka provides an exactly once delivery guarantee within a cluster and transactions, while AMQP brokers cannot provide such guarantees. Transactions in Kafka is a topic for a separate post, today we will start by getting to know Apache Kafka.
Apache Kafka
It seems to me that it will be useful for understanding to start the story about Kafka with a schematic representation of the cluster device.
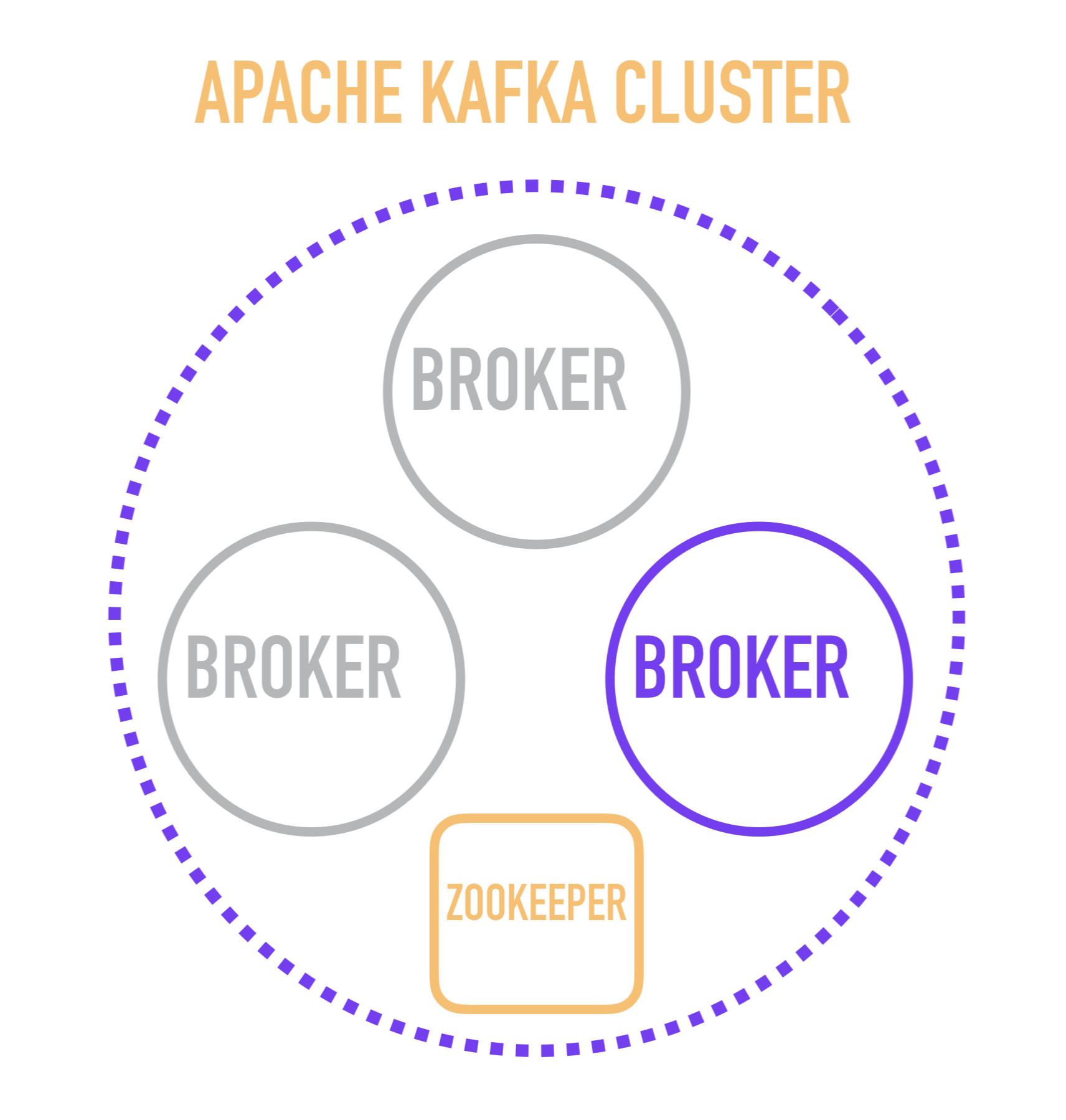
A separate Kafka server is called a broker . Brokers form a cluster in which one of these brokers acts as a controller that takes over some of the administrative operations (marked in purple).
The choice of a broker-controller, in turn, is the responsibility of a separate service - ZooKeeper, which also carries out service discovery of brokers, stores configurations and takes part in the distribution of new readers among brokers, and in most cases stores information about the last read message for each of the readers. This is an important point, the study of which requires you to go down one level and consider how a separate broker works inside.
Commit log
The data structure underlying Kafka is called the commit log, or the commit log.

New items added to the commit log are placed strictly at the end, and their order after that is not changed, so that in each individual log items are always listed in the order they were added.
The ordering property of the commit log allows it to be used, for example, for replication according to the principle of eventual consistency between database replicas: they store a log of changes made to the data in the master node, the sequential application of which on the slave nodes allows the data in them to be brought to the agreed upon with the master mind.
In Kafka, these logs are called partitions , and the data stored in them is called messages .
What is a message? It is the basic unit of data in Kafka, and is simply a collection of bytes in which you can pass arbitrary information - its content and structure are irrelevant to Kafka. The message can contain a key, which is also a set of bytes. The key allows you to get more control over the mechanism for distributing messages to partitions.
Partitions and topics
Why might this be important? The fact is that a partition is not analogous to a queue in Kafka, as it might seem at first glance. Let me remind you that technically a message queue is a means of grouping and managing message flows, allowing certain readers to subscribe only to certain data streams.
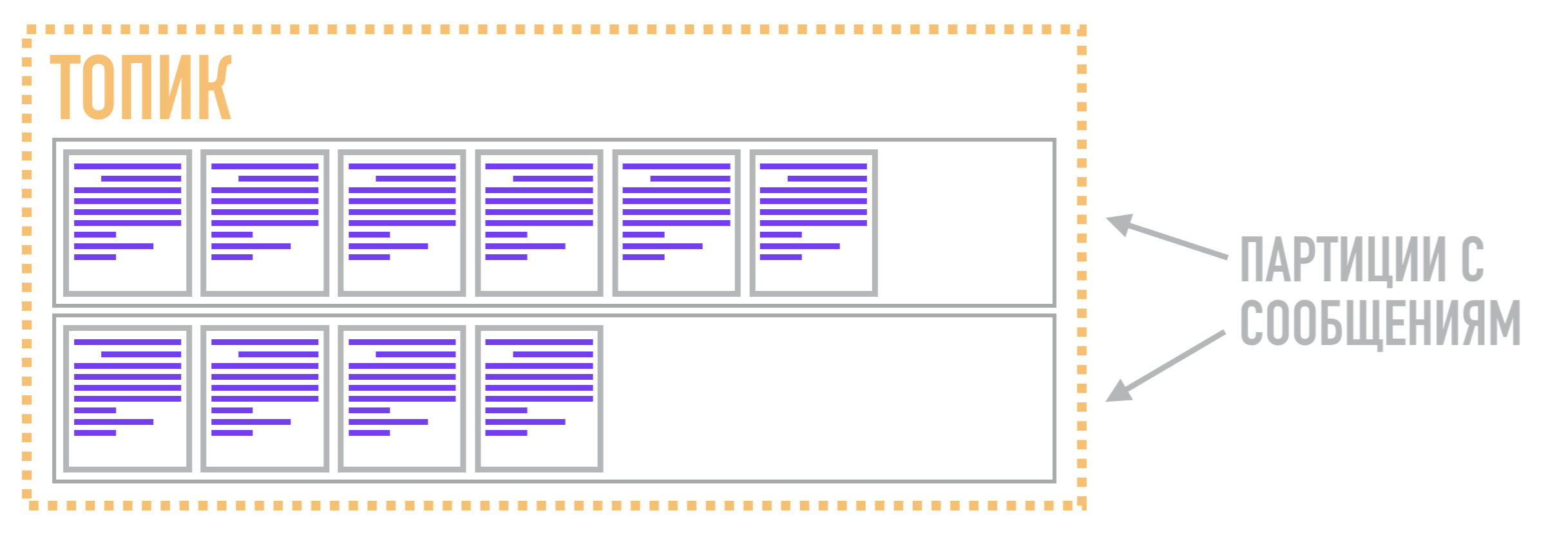
So in Kafka, the function of the queue is performed not by the partition, but by the topic . It is needed to combine several partitions into a common stream. The partitions themselves, as we said earlier, store messages in an ordered form according to the commit log data structure. Thus, a message related to one topic can be stored in two different partitions, from which readers can pull them out on request.
Therefore, the unit of parallelism in Kafka is not a topic (or a queue in AMQP brokers), but a partition. Due to this, Kafka can process different messages related to the same topic on several brokers at the same time, and also replicate not the entire topic as a whole, but only individual partitions, providing additional flexibility and scalability compared to AMQP brokers.
Pull and Push
Note that I did not accidentally use the word "pulls out" in relation to the reader.
In the brokers described earlier, messages are delivered by pushing them ( push ) to recipients through a conditional pipe in the form of a queue.
In Kafka delivery process itself is not: each reader himself is responsible for pulling ( pull ) messages from the partitions, which he reads.
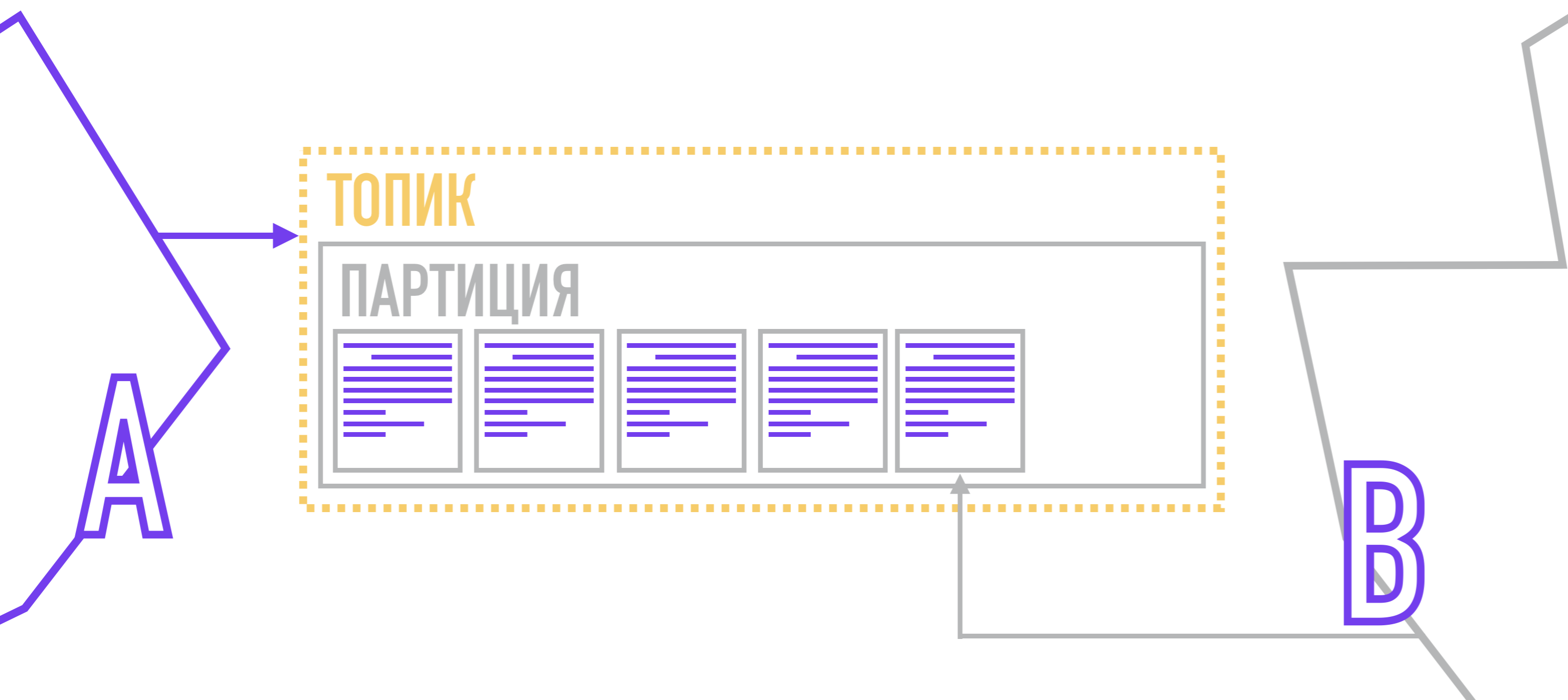
Producers, forming messages, attach a key and a partition number to it. The partition number can be chosen randomly (round-robin) if the message does not have a key.
If you need more control, you can attach a key to the message, and then use the hash function or write your own algorithm by which the partition for the message will be selected. After formation, the producer sends a message to Kafka, which saves it to disk, noting which partition it belongs to.
Each recipient is assigned to a specific partition (or several partitions) in the topic of interest, and when a new message appears, he receives a signal to read the next item in the commit log, while noting the last message he read. Thus, when reconnecting, he will know which message to read next.
What are the advantages of this approach?
- . , , . , ( Retention Policy, ), .
- Message Replay. , . , , .
- . , ( ) – , .
- . (batch) , , . : (1 ), .
The disadvantages of this approach include working with problem messages. Unlike classic brokers, broken messages (which cannot be processed taking into account the existing logic of the recipient or due to problems with deserialization) cannot be re-queued indefinitely until the recipient learns to process them correctly.
In Kafka, by default, reading messages from the partition stops when the recipient reaches the broken message, and until it is skipped and thrown into the "quarantine" queue (also called the " dead letter queue ") for further processing, continue reading the partition will not work.
Also in Kafka it is more difficult (in comparison with AMQP brokers) to implement message priority. This directly follows from the fact that messages in partitions are stored and read strictly in the order they were added. One of the ways to get around this limitation in Kafka is to create several topics for messages with different priorities (the topics will differ only in their names), for example, events_low, events_medium, events_high , and then implement the logic of priority reading of the listed topics on the side of the consumer application.
Another drawback of this approach is related to the fact that it is necessary to keep records of the last read message in the partition by each of the readers. Due to the simplicity of the structure of partitions, this information is presented in the form of an integer value called offset (offset). Offset allows you to determine which post is currently being read by each of the readers. The closest analogy to offset is the index of an element in an array, and the reading process is similar to walking through an array in a loop using an iterator as the index of the element.
However, this drawback is leveled out due to the fact that Kafka, starting from version 0.9, stores offsets for each user in a special topic __consumer_offsets (before version 0.9, offsets were stored in ZooKeeper).
In addition, you can keep track of offsets directly on the recipient's side.

Scaling also becomes more complicated: let me remind you that in AMQP brokers, in order to speed up the processing of the message flow, you just need to add several instances of the reader service and subscribe them to one queue, and you do not need to make any changes to the configuration of the broker itself.
However, scaling is a little more complicated in Kafka than in AMQP brokers. For example, if you add another instance of the reader and set it on the same partition, you will get zero efficiency, since in this case both instances will read the same dataset.
Therefore, the basic rule for Kafka scaling is that the number of competitive readers (that is, a group of services that implement the same processing logic (replicas)) of a topic should not exceed the number of partitions in this topic, otherwise some pair of readers will process the same data set.
Consumer Group
To avoid the situation with the reading of one partition by competitive readers, it is customary in Kafka to combine several replicas of one service in a consumer group , within which Zookeeper will assign no more than one reader to one partition.
Since readers are bound directly to the partition (while the reader usually does not know anything about the number of partitions in the topic), ZooKeeper, when a new reader is connected, redistributes participants in the Consumer Group so that each partition has one and only one reader.
The reader designates their Consumer Group when connecting to Kafka.
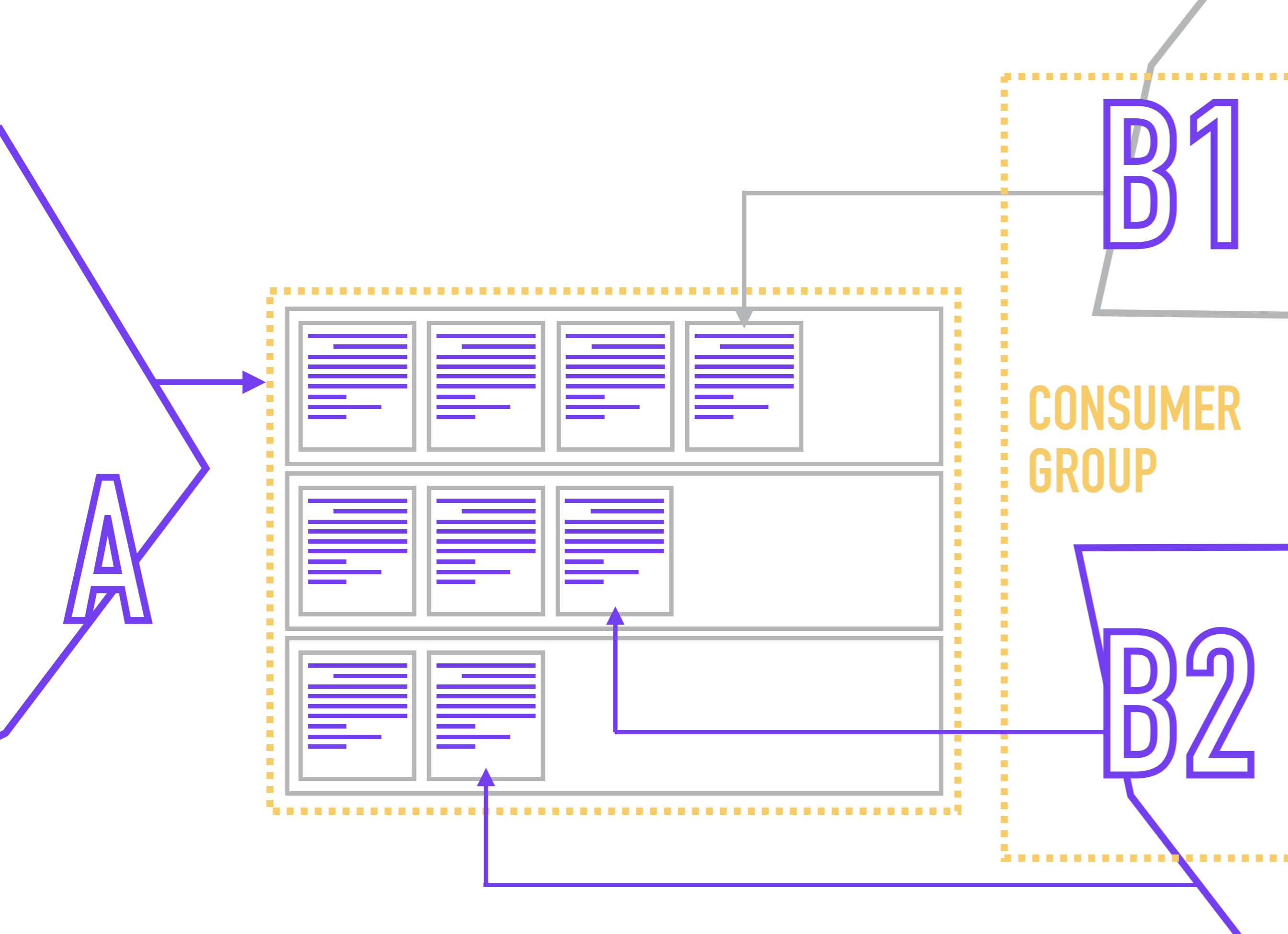
At the same time, nothing prevents you from hanging several readers with different processing logic on one partition. For example, you store in a topic a list of events by user actions and want to use these events to generate several views of the same data (for example, for business analysts, product analysts, system analysts, and the Yarovaya package) and then send them to the appropriate repositories.
But here we can face another problem, caused by the fact that Kafka uses a structure of topics and partitions. Let me remind you that Kafka does not guarantee the ordering of messages within a topic, only within a partition, which can be critical, for example, when generating reports on user actions and sending them to the as is storage.
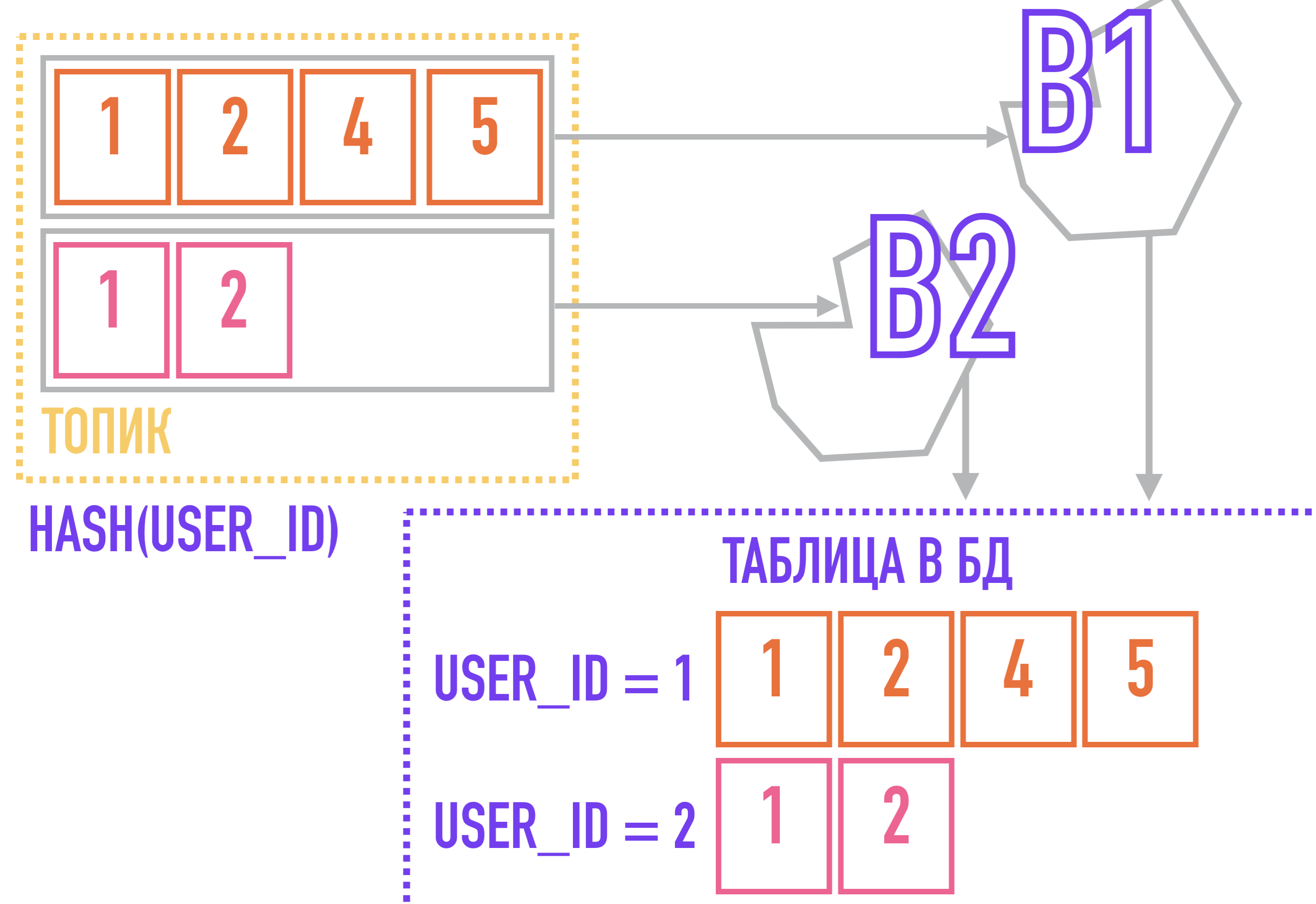
To solve this problem, we can go from the opposite: if all events related to one entity (for example, all actions related to the same user_id) will always be added to the same partition, they will be ordered within the topic simply because are in the same partition, the order within which is guaranteed by Kafka.
To do this, we need a key for messages: for example, if we use an algorithm that calculates the hash from the key to select the partition to which the message will be added, then messages with the same key will be guaranteed to fall into one partition, and therefore pull out the message recipient with the same key in the order they were added to the topic.
In a case with a stream of events about user actions, the partitioning key can be user_id.
Retention policy
Now it's time to talk about Retention Policy.
This is a setting that is responsible for deleting messages from the disk when the thresholds for the date of addition ( Time Based Retention Policy ) or the space occupied on the disk ( Size Based Retention Policy ) are exceeded .
- If you configure TBRP for 7 days, then all messages older than 7 days will be flagged for later deletion. In other words, this setting ensures that messages below the age threshold are available for reading at any given time. Can be set in hours, minutes and milliseconds.
- SBRP works in a similar way: when the disk space threshold is exceeded, messages will be marked for deletion from the end (older). It should be borne in mind: since the deletion of messages is not instantaneous, the occupied disk space will always be slightly more than specified in the setting. Set in bytes.
Retention Policy can be configured both for the entire cluster and for individual topics: for example, messages in a topic to track user actions can be stored for several days, while push notifications can be stored for several hours. By deleting data according to its relevance, we save disk space, which can be important when choosing an SSD as the main disk storage.
Compaction Policy
Another way to optimize disk space is to use the Compaction Policy - this setting allows you to store only the last message for each key, deleting all previous messages. This can be useful when we are only interested in the latest change.
Kafka use cases
- . : . , , , (Clickhouse !) .
Customer Care Vivid.Money CRM. - . , . , - ( ) , , .
, ( ) . , , , , . - . , .
- (commit log). , - / .
, , «» .
Customer Care CRM- .
Kafka
- – , ;
- – (pull) , . (, ) Consumer Group, ZooKeeper, , , , ;
- . , , , . , () ;
- , , AMQP , – . , ;
- . , , --, – .