At present, one of the trends in the study of graph neural networks is the analysis of the operation of such architectures, comparison with nuclear methods, assessment of complexity and generalizing ability. All this helps to understand the weak points of existing models and creates space for new ones.
The work is aimed at investigating two problems related to graph neural networks. First, the authors give examples of graphs that are different in structure, but indistinguishable for both simple and more powerful GNNs . Second, they bound the generalization error for graph neural networks more accurately than VC bounds.
Introduction
Graph neural networks are models that work directly with graphs. They allow you to consider information about the structure. A typical GNN includes a small number of layers that are applied sequentially, updating the vertex representations at each iteration. Examples of popular architectures: GCN , GraphSAGE , GAT , GIN .
The process of updating vertex embeddings for any GNN architecture can be summarized by two formulas:

where AGG is usually a function invariant to permutations ( sum , mean , max etc.), COMBINE is a function that combines the representation of a vertex and its neighbors.

More advanced architectures may consider additional information such as edge features, edge angles, etc.
The article discusses the GNN class for the graph classification problem. These models are structured like this:
First, vertices are embeddings using L steps of graph convolutions
(, sum, mean, max)
GNN:
(LU-GNN). GCN, GraphSAGE, GAT, GIN
CPNGNN, , 1 d, d - ( port numbering)
DimeNet, 3D-,
LU-GNN
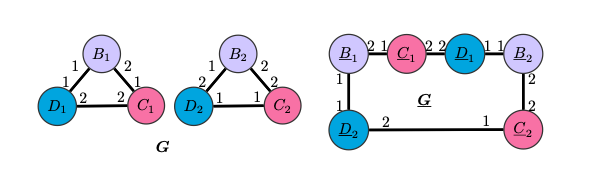
G G LU-GNN, , , readout-, . CPNGNN G G, .
CPNGNN

, “” , CPNGNN .
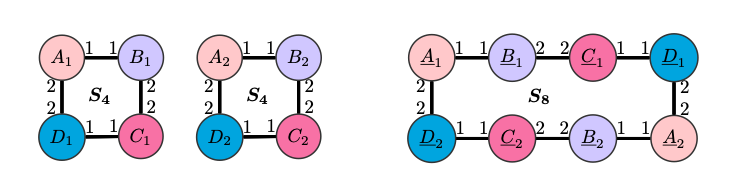
S8 S4 , , ( ), , , CPNGNN readout-, , . , .
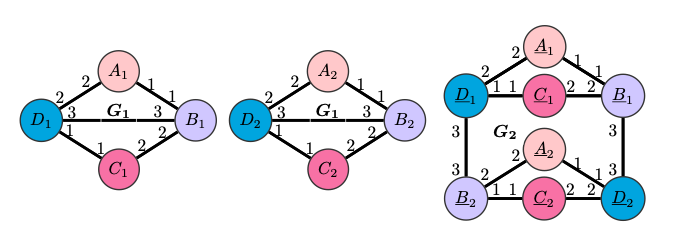
CPNGNN G2 G1. , DimeNet , , , , 
 .
.
DimeNet

DimeNet G4 , G3, . , . , G4 G3 S4 S8, , , DimeNet S4 S8 .
GNN
. , , .
GNN, :
DimeNet
message-



 , c - i- v, t - .
, c - i- v, t - .
:

readout-
.
: LU-GNN,

 - ,
- ,  - v, ,
- v, ,  . ,
. , 
 ,
,  .
.  GNN.
GNN.
. 
 .
.
 - GNN
- GNN  ,
,  - ,
- ,  .
.
,  ,
, - :
![loss _ {\ gamma} \ left (a \ right) = \ mathbb {I} \ left [a> 0 \ right] + (1 + \ frac {a} {\ gamma}) \ mathbb {I} \ left [a \ in \ left [\ gamma, 0 \ right] \ right].](https://habrastorage.org/getpro/habr/upload_files/10f/f87/63c/10ff8763ced82f8bcc4a3f1514442cd6.svg)
GNN 
 :
:

, , , , GNN . , (GNN, ), , , .
, :
,
( )

 - “ ”:
- “ ”:  , r - , d - , m - , L - ,
, r - , d - , m - , L - ,  - ,
- ,

( ), . , , , , , , .
Evidence and more detailed information can be found by reading the original article or by watching a report from one of the authors.