But, since people are not computers, they are looking for something like " something like that was from Ivanov or from Ivanovsky ... no, not that, earlier, even earlier ... here it is! "
But this threatens the developer with terrible problems - after all, for FTS-search in PostgreSQL , "spatial" types of GIN and GiST indexes are used , which do not provide for the "slip" of additional data, except for a text vector.
It remains only sad to read all records by prefix match (thousands of them!) And sort or, conversely, go by the date index and filterall the records found for the prefix match until we find suitable ones (how soon will there be "gibberish"? ..).
Both are not very pleasant for query performance. Or can you still think of something for a quick search?
First, let's generate our "texts-to-date":
CREATE TABLE corpus AS
SELECT
id
, dt
, str
FROM
(
SELECT
id::integer
, now()::date - (random() * 1e3)::integer dt -- - 3
, (random() * 1e2 + 1)::integer len -- "" 100
FROM
generate_series(1, 1e6) id -- 1M
) X
, LATERAL(
SELECT
string_agg(
CASE
WHEN random() < 1e-1 THEN ' ' -- 10%
ELSE chr((random() * 25 + ascii('a'))::integer)
END
, '') str
FROM
generate_series(1, len)
) Y;
Naive approach # 1: gist + btree
Let's try to roll the index both for FTS and for sorting by date - what if they help:
CREATE INDEX ON corpus(dt);
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
We will search for all documents containing words starting with
'abc...'
. And, first, let's check that there are few such documents, and the FTS index is used normally:
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
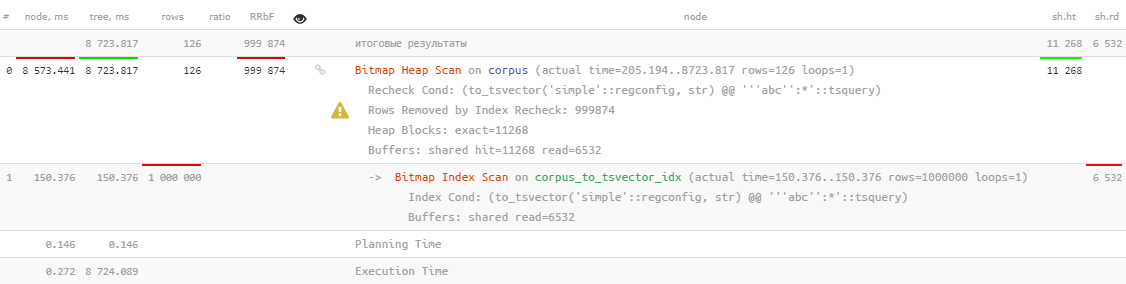
Well ... it is, of course, used, but it takes more than 8 seconds , which is clearly not what we would like to spend searching for 126 records.
Maybe if you add sorting by date and search only the last 10 records - it gets better?
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt DESC
LIMIT 10;

But no, just sorting was added on top.
Naive approach # 2: btree_gist
But there is an excellent extension
btree_gist
that allows you to "slip" a scalar value into a GiST index, which should enable us to immediately use index sorting using the distance operator
<->
, which can be used for kNN searches :
CREATE EXTENSION btree_gist;
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt <-> '2100-01-01'::date DESC -- ""
LIMIT 10;
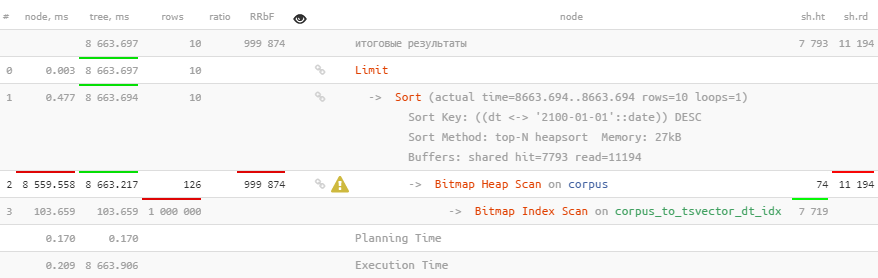
Alas, this does not help at all.
Geometry to the rescue!
But it's too early to despair! Let's take a look at the list of built-in GiST operator classes - the distance operator
<->
is only available for "geometric"
circle_ops, point_ops, poly_ops
, and since PostgreSQL 13 - for
box_ops
.
So let's try to translate our problem "into the plane" - we assign the coordinates of some points to our pairs
(, )
used for search so that the "prefix" words and not far away dates are as close as possible:

We break the text into words
Of course, our search will not be completely full-text, in the sense that you cannot set a condition for several words at the same time. But it will definitely be prefix!
Let's form an auxiliary dictionary table:
CREATE TABLE corpus_kw AS
SELECT
id
, dt
, kw
FROM
corpus
, LATERAL (
SELECT
kw
FROM
regexp_split_to_table(lower(str), E'[^\\-a-z-0-9]+', 'i') kw
WHERE
length(kw) > 1
) T;
In our example, there were 4.8M “words” per 1M “texts”.
Putting down the words
To translate a word into its "coordinate", let's imagine that this is a number written in base notation
2^16
(after all, we also want to support UNICODE characters). We will only write it down starting from the fixed 47th position:
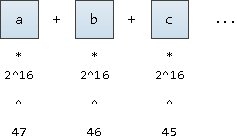
We could start from the 63rd position, this will give us the values slightly less than the
1E+308
limit values for
double precision
, but then an overflow will occur when building the index.
It turns out that on the coordinate axis all words will be ordered:

ALTER TABLE corpus_kw ADD COLUMN p point;
UPDATE
corpus_kw
SET
p = point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
);
CREATE INDEX ON corpus_kw USING gist(p);
We form a search query
WITH src AS (
SELECT
point(
( --
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
SELECT
*
, src.ps <-> kw.p d
FROM
corpus_kw kw
, src
ORDER BY
d
LIMIT 10;

Now we have the
id
documents we were looking for, sorted in the right order - and it took less than 2ms, 4000 times faster !
A small fly in the ointment
The operator
<->
does not know anything about our ordering along two axes, so our required data is located only in one of the right quarters, depending on the required sorting by date:

Well, we still wanted to select the texts-documents themselves, and not their keywords, so we'll need a long-forgotten index:
CREATE UNIQUE INDEX ON corpus(id);
Let's finalize the request:
WITH src AS (
SELECT
point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
, dc AS (
SELECT
(
SELECT
dc
FROM
corpus dc
WHERE
id = kw.id
)
FROM
corpus_kw kw
, src
WHERE
p[0] >= ps[0] AND -- kw >= ...
p[1] <= ps[1] -- dt DESC
ORDER BY
src.ps <-> kw.p
LIMIT 10
)
SELECT
(dc).*
FROM
dc;

They added a little to us
InitPlan
with the calculation of constant x / y, but still we kept within the same 2 ms !
Fly in the ointment # 2
Nothing is free:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- corpus_id_idx | 21 MB -- PK corpus_kw | 705 MB -- corpus_kw_p_idx | 403 MB -- GiST-
242 MB of "texts" became 1.1GB of "search index".
But after all,
corpus_kw
the date and the word itself lie in , which we have not used in the very search, so let's delete them:
ALTER TABLE corpus_kw
DROP COLUMN kw
, DROP COLUMN dt;
VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- id point
A trifle - but nice. It didn't help too much, but still 10% of the volume was won back.