
AWS Fault Injection Simulator (FIS)- a tool that allows you to implement previously known scenarios of internal system failure within AWS services. What for? - so that the teams could work out scenarios for their elimination and, in general, evaluate the behavior of their product under the proposed conditions. The system will immediately offer several templates with failure scenarios, for example, slowdown of servers, their failure, an error in accessing the database or its crash. At the same time, FIS will ensure that the experiment does not go too far and when certain parameters are reached, testing will be stopped, and the system will return to normal. The main slogan of the new product of the cloud giant is "increasing resiliency and performance using controlled chaos technology." The release of the new testing system is scheduled for 2021.
AWS also offers testing and distributed virtualized systems that are less dependent on a single host. The specificity of a failure in a distributed system is that the problem can be cyclical and have a more complex structure. The new AWS feature will allow you to search for vulnerabilities not only in the infrastructure of monoliths, but also in distributed systems and applications.
Let's see why this is important and cool.
Chaos engineering is a simulation testing process in which the main impact on the system comes from within and affects the project infrastructure. The team simulates situations in which the infrastructure part of the project is faced with technical and other problems, for example, with a point or systemic decrease in performance on instances. This can also include server crashes, API failures, and other nightmares of the backend that the team may face at any time or, even worse, on the day the next version is released.
There is no unambiguous definition of chaos engineering yet, so here are some of the most popular and, in our opinion, accurate options. Chaos engineering is: "an approach to experiment with a production system to make sure it can withstand various kinds of disturbances during operation" and "an experiment to mitigate the effects of disruption."
Why AWS Fault Injection Simulator is needed at all
The developers of the tool cite several reasons why FIS will be useful to teams when testing and preparing their systems.
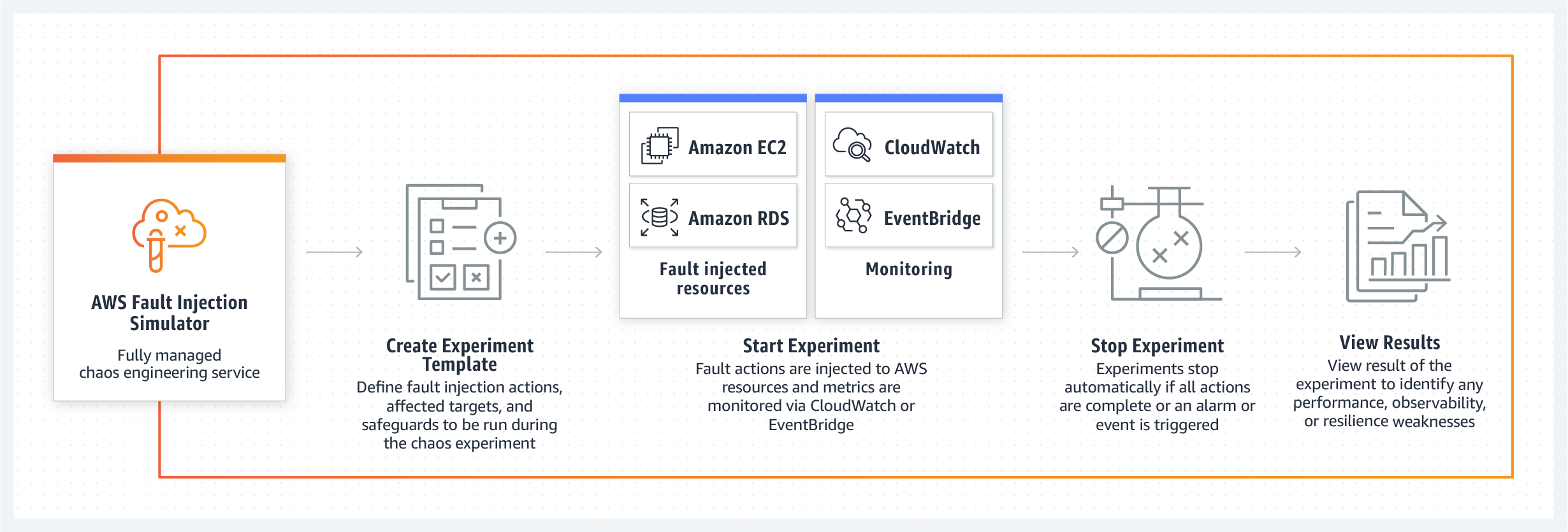
System performance, resilience and transparency are one of the core messages of the AWS FIS team.
AWS Fault Injection Simulator , , «» , .
In fact, the usual testing methods are, first of all, the simulation of the external load on the system. For example, simulating the habra effect or an external DDoS attack on a system or service. Most often, all the main monitoring systems are tied precisely to these nodes, while tracking the behavior of the internal infrastructure, often, is limited only to receiving data in the "down / down" style or the load on the CPU. At the same time, the greatest damage and the most powerful failures in recent years are associated precisely with internal failures or infrastructure errors. Suffice it to recall last year's CloudFlare crash, when, due to a number of failures and errors, developers literally forced half of the Internet to “lie down” with their own hands.
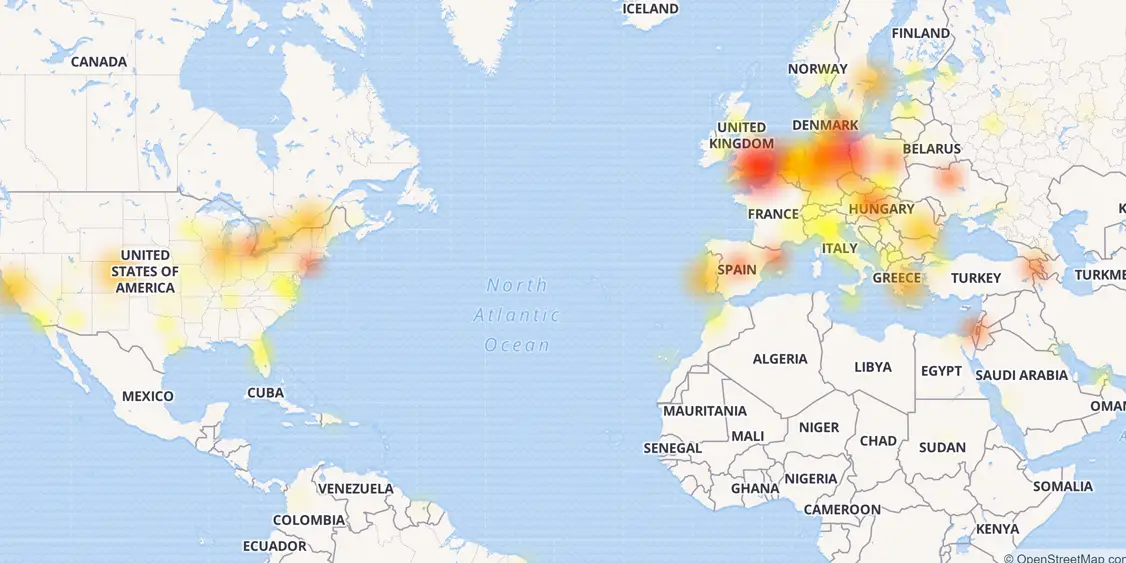
Map of that CloudFlare failure
The new tool is capable of working out both ready-made templates for scenarios of database failure, API or degradation of performance, as well as creating randomized “blind test” conditions in which problems will occur in random order on different nodes.
Another strong point of the new AWS toolkit is the controllability of the chaos created by the team in the system. Engineers assure that with the help of their control panel, developers can stop a controlled failure scenario at any time and return the system to its original working state. Fault Injection Simulator supports Amazon CloudWatch and third-party monitoring tools connected through Amazon EventBridge, so developers can use their metrics to monitor controlled chaos experiments. And, of course, after stopping the test, the administrator will receive a full report on which nodes of the system and in what sequence were affected by the failure, which in the future will help develop a set of measures and procedures for localizing and eliminating problems.
How the Lords of Chaos came to be
Obviously, such stress testing of the system is most logical to conduct in the pre-release period in order to make sure that the existing infrastructure on AWS will withstand the new patch. However, in reality, the chaos engineering technique goes back to older practices, the founder of which is one of the Amazon managers in the 2000s, Jesse Robbins. His position was officially called "Master of Disaster", which in a pathetic translation can be mistaken for "Lord of Catastrophes", and in his free language his position sounded like "Master Lomaster".
 It was Robbins, a former rescue firefighter, who
implemented GameDay into Amazon.... The goal of the Robbins initiative was very simple - to provide engineering teams with an intuitive understanding of how to deal with a disaster, much like that feeling is trained in fire brigades. It was for this that the technique of global simulation of total chaos was chosen: everything breaks down from all sides, simultaneously or sequentially, and each attempt to cope with the failure leads to new and new problems.
It was Robbins, a former rescue firefighter, who
implemented GameDay into Amazon.... The goal of the Robbins initiative was very simple - to provide engineering teams with an intuitive understanding of how to deal with a disaster, much like that feeling is trained in fire brigades. It was for this that the technique of global simulation of total chaos was chosen: everything breaks down from all sides, simultaneously or sequentially, and each attempt to cope with the failure leads to new and new problems.
When an unprepared person is faced with the riot of the elements, he, most often, falls into either a stupor or panic. Most developers and engineers are not psychologically ready for a situation where solving a problem should take three days, and the level of stress around is simply off scale.
Robbins calls the most important result of GameDay the psychological effect of such exercises: they develop the ability to accept the fact that large-scale disruptions occur . It is the acceptance of the fact that everything around is on fire and collapsing, he calls it very important for the engineer, so that he could collect his thoughts and finally begin to "extinguish the fire." An untrained person will, at best, run in circles and shout "everything is lost."
After the implementation of the GameDay practice, it turned out that such exercises perfectly identify architectural problems and bottlenecks that are not paid attention to during classical testing and verification.
Another significant difference between GameDay and our usual "training and order" exercises is that few people know the specific scenario and what will happen in general. Information about the upcoming "games" is given in a very general and vague way, so that the participants could not fully prepare for this event. Ideally - to announce only the date of the next "game day" without any clarifications at all, just so that the participants would not mistake it for a real accident. Of course, this methodology does not scale to a huge company, for example, GameDay cannot be conducted all over Yandex or Microsoft at once.
As a result, the practice was upgraded to local GameDay and was introduced in all the existing large IT companies, for example, in Google, Flickr and many others. It has its own Lords of Disasters (well, or Master-Lommasters, as you like), who are involved in organizing training failures and then analyzing the results obtained on specific projects.
The main difficulty in implementing this practice everywhere lies in two aspects: how to organize it and how to collect data so that GameDay is not in vain. That is why, in smaller companies, until recently, this technique was not used very widely (if used at all). Instead of GameDay and disaster simulation, the business focused more on different types of testing, CI / CD, and other methodologies for orderly and consistent development. That is, on what prevents catastrophe as such.
The new AWS toolkit will allow you to tackle the other side of disruption: instead of prevention, which is undoubtedly important, FIS will enable engineering teams of all sizes to effectively train in resolving global infrastructure disruptions. After all, the main thing that Robbins notes is that disasters happen anyway: they cannot be avoided.