
There are many approaches to building application code to keep project complexity from growing over time. For example, the object-oriented approach and a lot of attached patterns allow, if not keeping the complexity of the project at the same level, then at least keeping it under control during development, and making the code available to the new programmer in the team.
How can you manage the complexity of an ETL transformation project on Spark?
It's not that simple.
What does it look like in real life? The customer offers to create an application that collects a storefront. It seems to be necessary to execute the code through Spark SQL and save the result. During development, it turns out that 20 data sources are required to build this mart, of which 15 are similar, the rest are not. These sources must be combined. Further, it turns out that for half of them, you need to write your own assembly, cleaning, and normalization procedures.
And a simple showcase, after a detailed description, begins to look something like this:
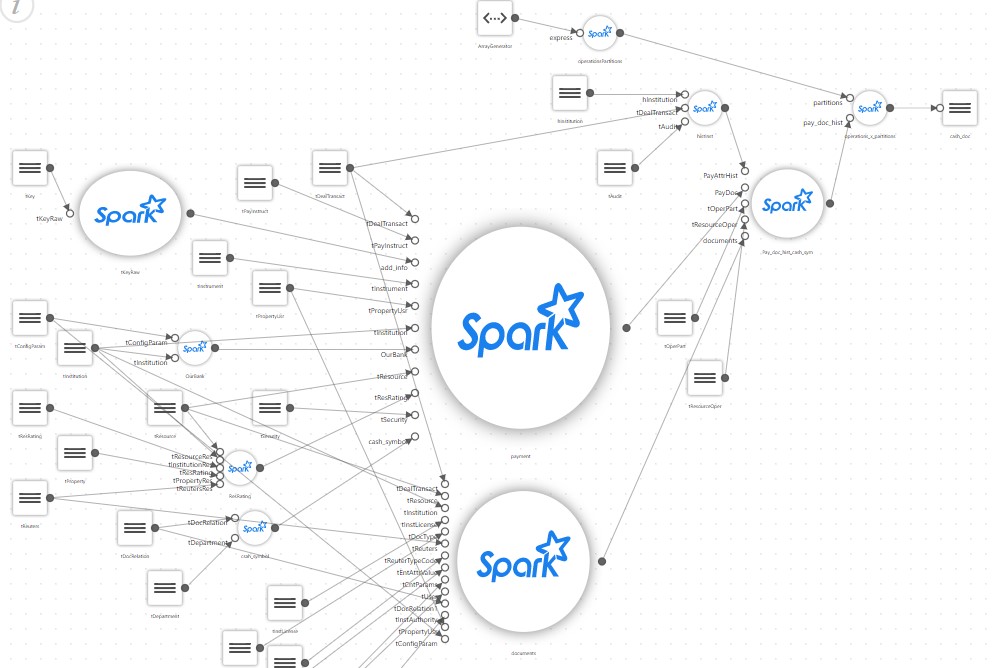
As a result, a simple project, which was only supposed to run a SQL script that collects the showcase on Spark, is overgrown with its own configurator, a block for reading a large number of configuration files, its own mapping branch, translators of some special rules etc.
By the middle of the project, it turns out that only the author can support the resulting code. And he spends most of his time in thought. Meanwhile, the customer asks to collect a couple more showcases, again based on hundreds of sources. At the same time, we must remember that Spark is generally not very suitable for creating your own frameworks.
For example, Spark is designed to make the code look something like this (pseudocode):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)
Instead, you have to do something like this:
var Source1 = readSourceProps(“source1”) var sql = readSQL(“destTable”) writeSparkData(source1, sql)
That is, to move blocks of code into separate procedures and try to write something of your own, universal, which can be customized by settings.
At the same time, the complexity of the project remains at the same level, of course, but only for the author of the project, and only for a short time. Any invited programmer will take a long time to master, and the main thing is that it will not work to attract people who know only SQL to the project.
This is unfortunate, since Spark itself is a great way to develop ETL applications for those who only know SQL.
And in the course of the development of the project, it turned out that a simple thing was turned into a complex one.
Now imagine a real project, where there are dozens, or even hundreds, of such storefronts as in the picture, and they use different technologies, for example, some of them can be based on parsing XML data, and some on streaming data.
I'd like to somehow keep the complexity of the project at an acceptable level. How can this be done?
The solution may be to use a tool and low-code approach, when the development environment decides for you, which takes all the complexity, offering some convenient approach, as, for example, described in this article .
This article describes the approaches and benefits of using the tool to solve these kinds of problems. In particular, Neoflex offers its own solution Neoflex Datagram, which is successfully used by different customers.
But it is not always possible to use such an application.
What to do?
In this case, we use an approach that is conventionally called Orc - Object Spark, or Orka, as you like.
The initial data is as follows:
There is a customer who provides a workplace where there is a standard set of tools, namely: Hue for developing Python or Scala code, Hue editors for SQL debugging through Hive or Impala, and Oozie workflow Editor. This is not much, but quite enough for solving problems. It is impossible to add something to the environment, it is impossible to install any new tools, due to various reasons.
So how do you develop ETL applications, which, as usual, will grow into a large project, in which hundreds of data source tables and dozens of target marts will participate, without drowning in complexity and not writing too much?
A number of provisions are used to solve the problem. They are not their own invention, but are entirely based on the architecture of Spark itself.
- All complex joins, calculations and transformations are done through Spark SQL. Spark SQL optimizer improves with every release and works very well. Therefore, we give all the work of calculating Spark SQL to the optimizer. That is, our code relies on the SQL chain, where step 1 prepares the data, step 2 joins, step 3 calculates, and so on.
- Spark, Spark SQL. (DataFrame) Spark SQL.
- Spark Directed Acicled Graph, , , , , 2, 2.
- Spark lazy, , , .
As a result, the entire application can be made very simple.
It is enough to make a configuration file in which to define a single-level list of data sources. This sequential list of data sources is the object that describes the logic of the entire application.
Each data source contains a link to SQL. In SQL, for the current source, you can use a source that is not in Hive, but described in the configuration file above the current one.
For example, source 2, if translated into Spark code, looks something like this (pseudocode):
var df = spark.sql(“select * from t1”); df.saveAsTempTable(“source2”);
And source 3 may already look like this:
var df = spark.sql(“select count(*) from source2”) df.saveAsTempTable(“source3”);
That is, source 3 sees everything that was calculated before it.
And for those sources that are target showcases, you must specify the parameters for saving this target showcase.
As a result, the application configuration file looks like this:
[{name: “source1”, sql: “select * from t1”}, {name: “source2”, sql: “select count(*) from source1”}, ... {name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]
And the application code looks something like this:
List = readCfg(...) For each source in List: df = spark.sql(source.sql).saveAsTempTable(source.name) If(source.target == true) { df.write(“format”, source.format).save(source.path) }
This is, in fact, the entire application. Nothing else is required except one moment.
How to debug all this?
After all, the code itself in this case is very simple, what is there to debug, but the logic of what is being done would be nice to check. Debugging is very simple - you have to go through all applications to the source being checked. To do this, you need to add a parameter to Oozie workflow that allows you to stop the application at the required data source by printing its schema and contents to the log.
We called this approach Object Spark in the sense that all application logic is decoupled from Spark code and stored in a single, fairly simple configuration file, which is the application description object.
The code remains simple, and once created, even complex storefronts can be developed using programmers who only know SQL.
The development process is very simple. In the beginning, an experienced Spark programmer is involved, who creates universal code, and then the application configuration file is edited by adding new sources there.
What this approach gives:
- You can involve SQL programmers in the development;
- Given the parameter in Oozie, debugging such an application becomes easy and simple. This is debugging any intermediate step. The application will work everything to the desired source, calculate it and stop;
- ( … ), , , , , . , Object Spark;
- , . . , , , XML JSON, -. , ;
- . , , , , .