
Today we will talk about a seemingly simple topic like relational and related data.
Despite all its simplicity, I notice that sometimes people really get confused about them - I decided to fix this by writing a short and informal explanation of what they are and why they are needed.
We will discuss what the relational model is and the related SQL and relational algebra. Then let's move on to examples of related data from Wikidat, and then RDF, SPARQL and a little talk about Datalog and logical data representation. In the end, the conclusions - when to apply the relational model, and when the connected-logical model.
The main purpose of the note is to describe when it makes sense to apply what and why. Since there are many difficult concepts that have come together in one place, of course it would be possible to write a book for each - but our task today is to give an idea of the topic and we will analyze it informally using simple examples.
If you have doubts about how one differs from the second and why you need linked data (LinkedData) at all, then welcome under cat.

Relational data
Let's start with a standard definition. A
relational database is a collection of data with predefined relationships between them. This data is organized as a set of tables consisting of columns and rows. The tables store information about the objects represented in the database.
When applied:
- Fixed domain modeling
- The data schema changes either little, or the changes affect immediately a significant group of records
- Basic queries - filtering categories by key fields of records, aggregation, generating reports and analytics based on statistical indicators, etc
In such a situation, the unit of modeling is the table and relationships between tables (such as foreign keys). In fact, a table is a predicate with fixed attributes, i.e. we always know the arity of a tabular predicate.
Let's take a foreign key as an example of constraint relationships: the key “p (_, X, _) → q (_, Y, _)”, which sets constraints in the form X \ subset Y, where X is an attribute of the p relation, and Y relationship attribute q.

More importantly, in the world of relational data, we have everything a table! And operations take a table as input and return a table, for example:

Relational Data Language: SQL and Relational Algebra
Relational algebra (Codd algebra) is essentially a set of operations on tables that return tables. That is, for you, the central element of modeling is precisely the fixed tables and their transformations.
The SQL language is a declarative superstructure and concrete implementation of the ideas of relational algebra.
An example of a simple query and the corresponding relational operators from algebra.

So far, all we've covered are the classic things we know from any database course.
Linked data and knowledge graphs
Let's just imagine what would happen if we have new properties and this happens, perhaps in real time? That is, the domain is not fixed - but flexible and extensible ?
In such a situation, of course, we can add tables and columns to tables by injecting NULL or default values. But in addition to being technically inconvenient, it is also an unsuitable tool from a modeling point of view.
Imagine that you are modeling the life of people in all its possible aspects. Even two different people will have a rather different set of key properties, and this is absolutely normal!
You do not have a fixed list of how a specific character will be described. Writer and Footballer - these are two People who have many important, but, nevertheless, different properties.
Let's start with the writer Douglas Adams - the top properties are pretty typical for anyone - here and further we use Wikidata as an example of LinkedData.
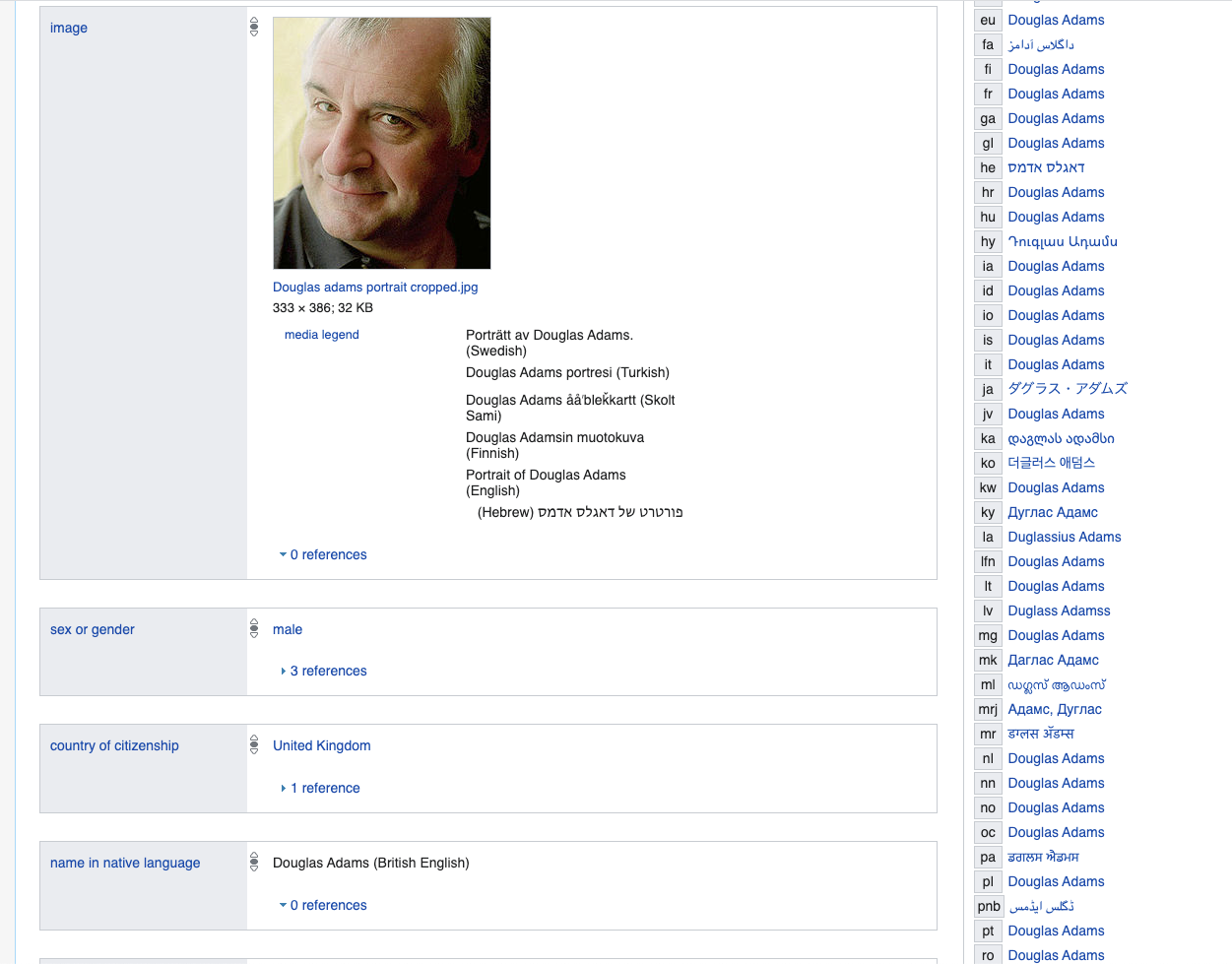
www.wikidata.org/wiki/Q42
But let's dig a little deeper and
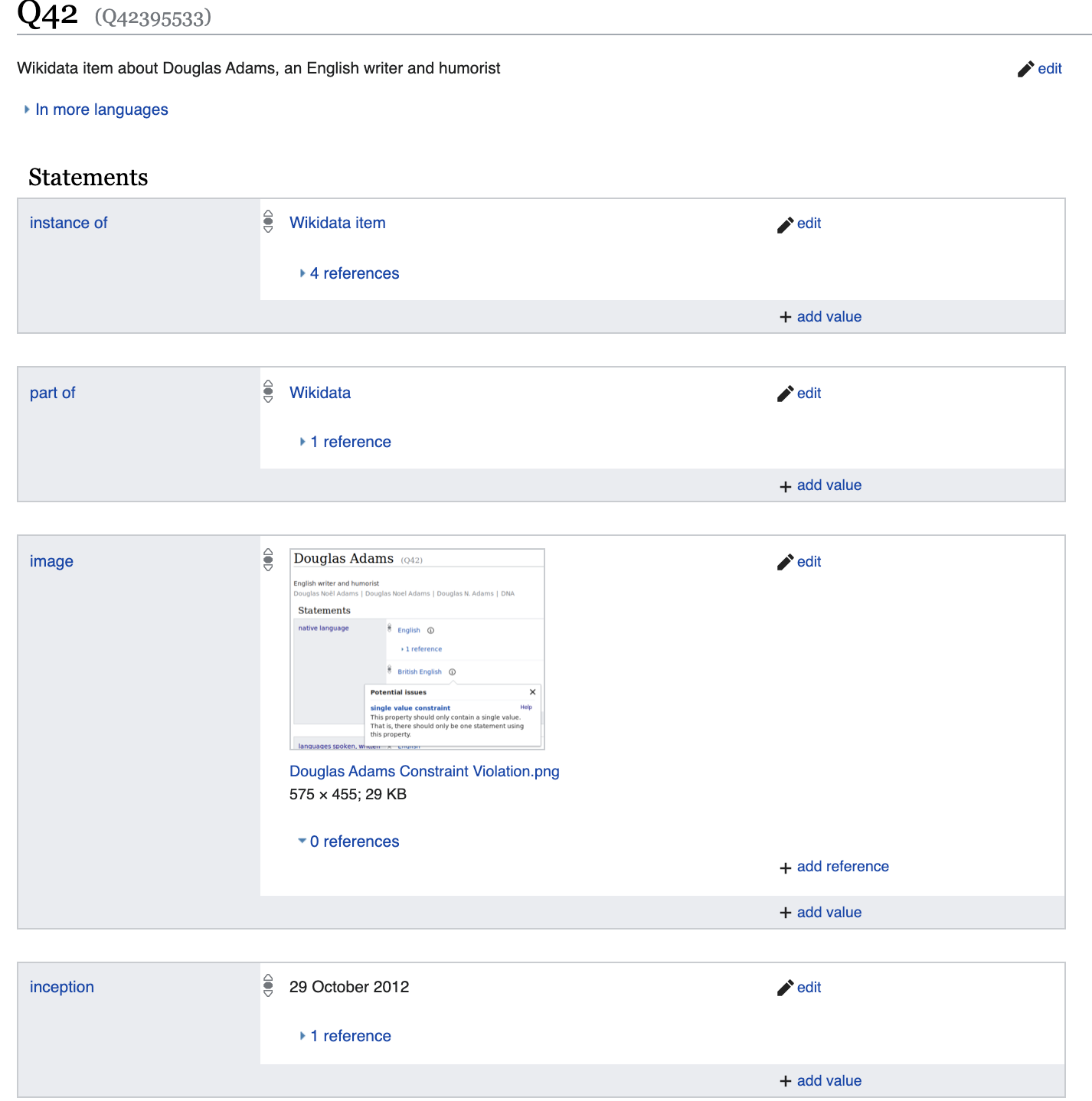
see a set of properties that will differ significantly from, for example, Diego Maradonna
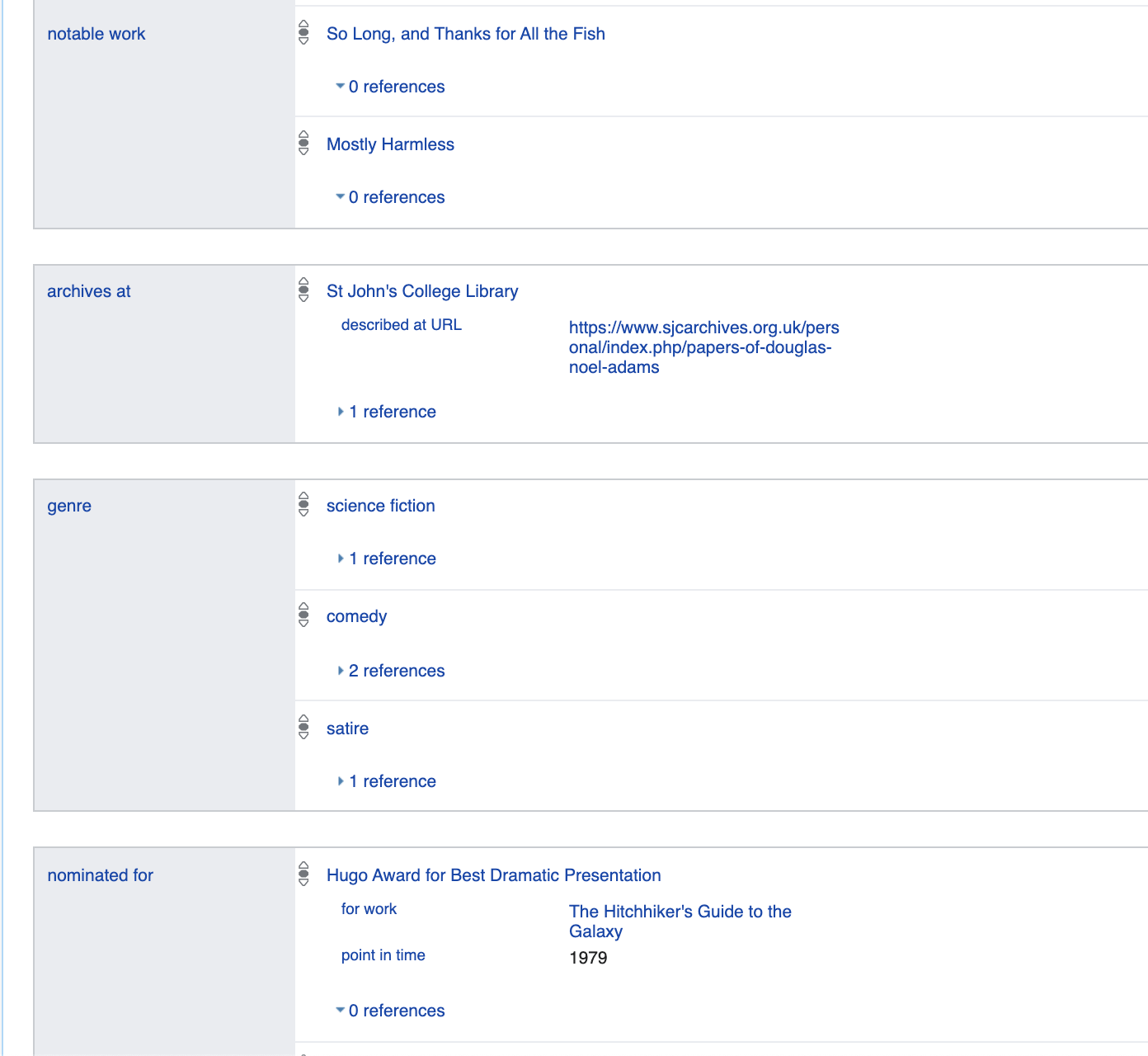
Let's talk a little more about the properties listed here. For example, gender: male is

essentially a reflection of the logical fact: p21 (Q42, Q6581097).
Where p21 → is gender_identity / 2 is a binary predicate
Q42 → Douglas Adams
Q6581097 → male
Thus, all data is presented as either unary predicates, for example is_dead (Q42), or as binary p21 (Q42, Q6581097).
In fact, this is another paradigm of the modeling paradigm - first order logic, but on unary and binary predicates.
And here it is very easy to add new data: everything that is not indicated in the form of a predicate over objects is false, in the literature this is known as the Closed-world assumption .
Moreover, this format allows for absolutely natural meta-modeling
https://www.wikidata.org/wiki/Q42395533
There are several basic storage and writing queries to such data - let's look at the popular options.
RDF and the SPARQL Query Language
RDF is a formal language for describing related data for subsequent query processing, that is, it is a machine-readable format.
In fact, for him, the key is the concept of a triplet:

And here is an example of data recording in this model (prefixes determine where the "descriptions" of these predicates lie)

This recording format allows you to graphically represent data about objects - for example, you can write information about the city of Berlin.

For the RDF format, they created the SPARQL query language: which essentially describes the constraints on logical predicates and says which variable should be extracted from the logical expression:

In fact, we want to find the value of the variable? Country such that member_of is true for member_of (? Country, q458) and q458 is the EU ID.
In real code, it might look like this:
Total: RDF is a format for representing data in the form of triples (binary predicates) and SPARQL is a logic-based query language for triples.
Datalog Query Language and Derivatives
Also, to write queries to RDF (and not only to it, more on that later), you can use Datalog - a declarative (often) language that syntactically represents a subset of Prolog (most often).
In it, queries look like this:
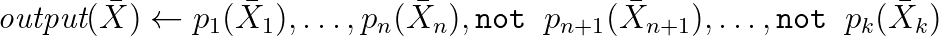
Often the syntax is extended with the help of aggregations and other practically important things. In fact, these are inference rules taken from logic, and with their help you can model the inference of new properties and write queries to RDF. The following is a real-world example working with WikiData based on one of the dialects

Another important advantage of Datalog-based logical query languages is that for them RDF is simply a format for recording facts (statements) of binary logic. They can just as well handle any other logical assertion - not necessarily binary.
conclusions
First, relational data is well suited for modeling fixed domains, where the schema either changes infrequently, or changes affect not just single records, but entire segments.
Secondly, relational languages are well suited for modeling tasks where you need to extract sub-tables, transform and combine existing ones - this is not an ideal tool when a significant part of the work goes at the level of modification and / or inference on a particular record.
Thirdly, if the modeling domain is an all-encompassing area, and even changing, where even the records of the same class are strikingly different, coherent data is well suited.
Fourth, the standard representation is RDF and it makes sense to try it first. By screwing the necessary databases to it and using SPARQ-like languages, you can extract the necessary data.
Fifth, if modeling with triplets becomes cumbersome and awkward, you can consider the logical representation of the data and Datalog as a query language.

