For thirteen years, we have been looking for ways to scale development so that everything works reliably as it grows and, at the same time, new features are released quickly. Once it seemed important to easily rename columns in a database. Now - I had to change the entire architecture on the go.
This is the third annual development post for Black Friday, the peak week. Why do we finally think that we are great; what they did for this; why we encountered difficulties and what we plan to do next.
Summary: two years work for good reason
For the fifth consecutive year, the load on Mindbox roughly doubles annually. In November 2020, we processed 8.75 billion API requests, compared to 4.48 billion a year earlier. The peak is 400 thousand requests per minute. Sent 1.64 billion emails and 440 million mobile notifications. A year ago, there were 1.1 billion emails, but there were almost no push messages.
Dynamics of the number of mailings per week of Black Friday:
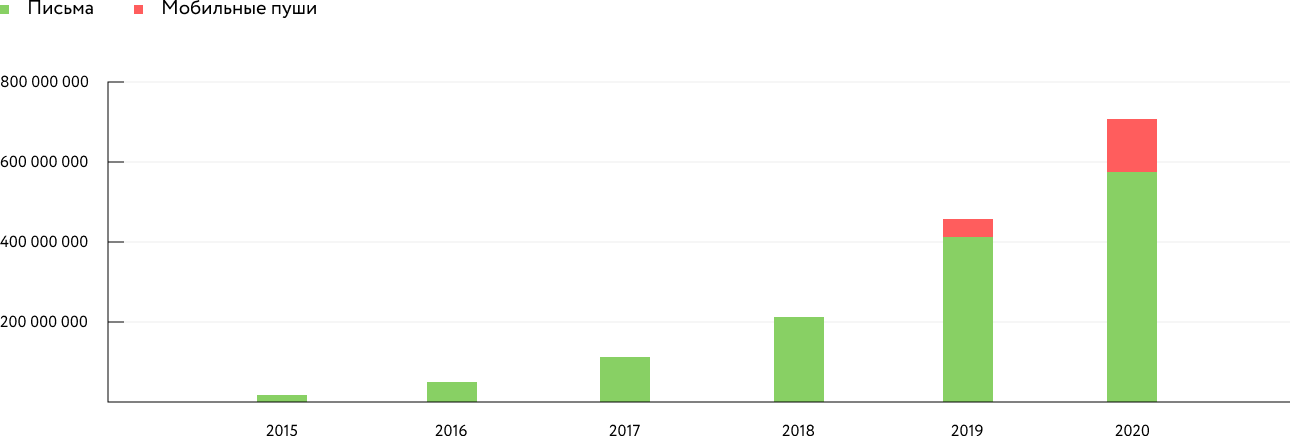
According to our data, this is comparable to hh.ru level of load on API requests, in terms of load on databases - with Avito. About a third of Yandex-taxi on requests per minute.
In 2018 and 2019Over the years we have dealt with this poorly: customers have suffered from rejections. At the end of 2018, I hoped for quick improvements and expected a business roadmap, which has so far been only half completed. In 2019, I decided to keep silent about the roadmap, as reliability deteriorated, the failures began in September, and on Black Friday they repeated, despite the large amount of work done.
Today we can conclude: we have learned to cope with growth. Black Friday 2020 passed without incident affecting more than one customer. There were two short-term partial failures due to external infrastructure that did not violate the SLA. Unfortunately, there were complaints from several of the largest clients, but these are single stories that we understand, and we are working on them.
Moreover, the data and subjective user reviews show a long-term trend of increasing development quality. Defects — critical errors, failures, and poor performance — are reduced.
The graph shows violations of the internal SLA (stricter than the external one), which we additionally made even stricter this year:

Number of internal SLA violations by an average client
We managed to completely "reinvent" the development in two years, continuing to grow at an average rate of 40% of revenue per year (in 2019 - 431 million, in 2020 - 618 million) and releasing new features. Feelings - about how to change the engine of a car at full speed.
What have been done in two years:
- (LESS) , , .
- 50% , ( ) .
- SRE. SRE .
- , , .
- SLA .
- «-», .
This is far from all planned. We continue to increase the amount of resources allocated for quality. We expect further quality improvements and faster release of new features in 2021 and beyond.
By the way, we regularly write about product updates and maintain a status page with a history of incidents .
The origins of the difficulties: 2008-2018
Mindbox is a product with complex business logic, since 2008 we have been developing as a service for large businesses, with a share of development costs of over 30%. From an architectural point of view, it was a traditional monolithic application, but very high quality: every day we released and are still releasing several monolith updates.
In 2014, the market made us turn towards a more mass segment, including e-commerce and retail. This required an investment in customer service, sales and marketing.
The company has never attracted external investments, it has always developed on its own profit. In addition, in 2017, six months after I became CEO, we faced a shortage of money, I got scared and increased my profitability excessively. All this led to a reduction in development costs to 24% of revenue in 2018-2019.
At the same time, it was necessary to release a lot of functions needed by new clients - with a rapid increase in the load and the number of clients. We coped with the backlog of the original product and architecture, as well as decentralization - the formation of autonomous product teams.
Unfortunately, the technical expertise of such teams did not keep pace with the growth of the company, which was further compounded by the limits of the possible in monolithic architecture. Technical debt was accumulating, the technology used was outdated, and salaries were below market. Hiring engineers has become increasingly difficult, despite the challenging challenges and unique culture of the company. By 2018, the number of customers had grown 10 times, the success of the product became obvious, as well as the problems in reliability and development in general.
What measures have we taken
Processes and resources
The first hypothesis was centralization: in 2019, LESS was introduced - this is when several teams are working on one project at the same time. We began to jointly design epics and work with reliability, we managed to increase predictability and find useful design practices. However, after a year, the ineffectiveness of the process became obvious: demotivation and reduced responsibility of teams due to the lack of a sense of "their" features, high management costs, which no one liked to do.
Over a year of collaborative design, a vision of a decentralized architecture emerged that would allow each team to be responsible for isolated microservices while continuing to deliver a single product to customers. Together with the vision, backlogs of tasks appeared and it became clear that it was necessary to work on the infrastructure with dedicated specialists, without interrupting it with a business roadmap.
We agreed to allocate 30% of the resource for technical debt on an ongoing basis. The first infrastructure team was formed, and autonomous teams began to be allocated again. At the same time, a number of centralized collaboration processes have been preserved, primarily aimed at maintaining quality:
- design,
- defect analysis,
- modeling the load on iron,
- demo and sync statuses.
We took the responsibility of architects and teams for reliability metrics and server cost projections. Additionally, we allocated 30% in each team for technical debt and bugs, while waiting for business continuity.
In 2020, the processes settled down: we formed a second infrastructure team, and the delivery was adjusted. The share of resources for business tasks began to grow slowly from a low point of about 50%, and the share of bugs began to decrease:

Allocation of development resources by tasks. The graph is not very informative, since a reliable metric was established relatively recently, but is supported by impressions from the
field.During this time, we learned how to hire and onboard SREs, separated them from DevOps and office IT, formed duty processes and described the role.
The shortage of engineers was reduced in two ways:
- We created a development school that graduates 8-12 junior developers a year. These are developers who have experience with our stack, in whose abilities we are confident. Today, the school has 2 teams of 4 trainees.
- We systematically increased the payroll for development, since the business results allowed it. The average salary in development has grown from 120 thousand rubles in 2015 to 170+ at the end of 2020 and continues to grow. This allowed us to hire several new strong seniors and tech leads. The share of development costs rose to 28%, and the number of people increased from 27 to 64.
Metrics, metrics and automatic metrics
In our culture, it is customary to manage by data, not personal opinion. Effective metrics are perhaps one of the difficult questions to which modern development management methodologies do not give a direct answer.
We started by automating four metrics from the Accelerate book and accelerating the delivery pipeline. This had no immediate obvious effects. But the exchange of experience with hh.ru and Yandex-cloud led us to the automation of the SLA violation metric and the automatic establishment of defects. Here we clearly felt the benefit and connection with the efforts being made. The graph of this metric with a trend is at the beginning of the post.
Discreet, but I think we are one of the few companies in the world that has an API for clients that allows you to get a metric of the availability of platform components in real time.
The metric described above for the share of bugs and technical debt in the team also seems useful. Additionally, we consider how the teams fulfill the promises given for the sprint, and the developers meet the deadlines for daily and weekly tasks.
Finally, anonymous quarterly polls (the texts have improved since then, but the essence of the poll has not changed) and a high rating on Habr-Karer show a decrease in development misfortune. This concerns the assessment of its income in relation to the market, refineries and eNPS (data for only two quarters so far).
Developer Income
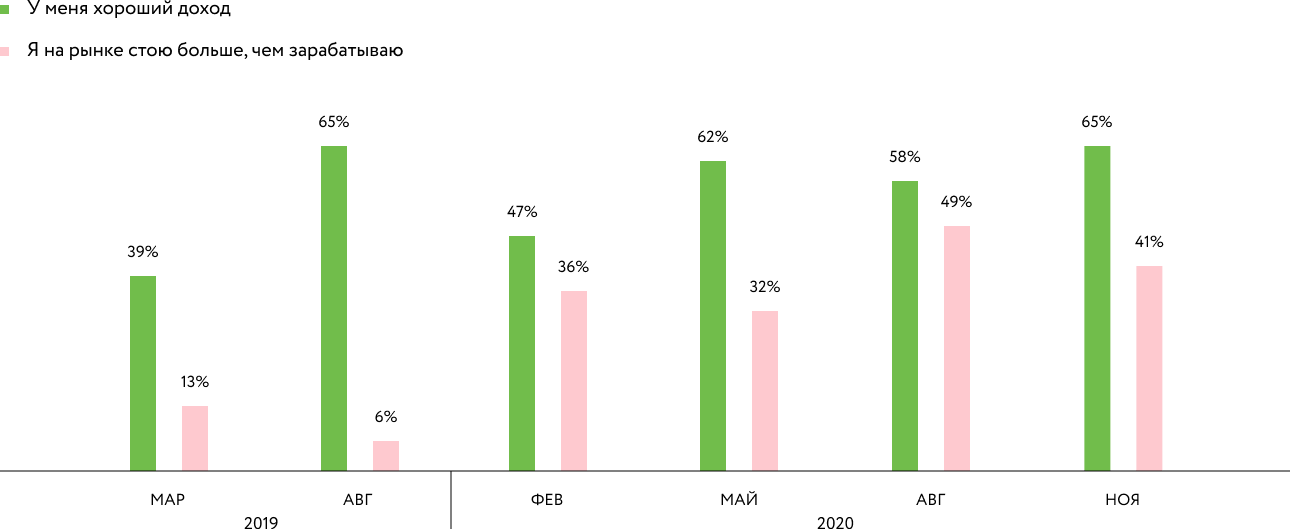
Survey:

Developer Overhaul Survey : eNPS Developers:

On a scale of 1 to 10, how likely is it that you recommend Mindbox as a place to work?
Last but not least, technology
All this made it possible to organize the rewriting of a monolithic product - more than 2 million lines of code on IIS + ASP.NET + NLB / Windows Service / MS SQL - simultaneously in all directions:
- Microservice API and backend, when one client request to API Gateway is transparently processed by multiple microservices, including synchronous requests (saga pattern).
- Microfront-end, where the interface sections are separate from the backend SPA applications that can be hosted in their own repositories, with their own layout pipeline.
- Transfer of multi-tenant microservices from MS SQL to distributed scalable storages: Cassandra, lickhouse. Kafka instead of RabbitMQ.
- Transfer of the application to .NET Core, linux and partial transfer to Managed Kubernetes "Yandex-clouds". Immediately implementation of modern SRE and DevOps technologies: OctopusDeploy + Helm, Prometheus, Grafana, Graylog + Sentry, Amixr.IO.
Perhaps we are one of the most loaded clients of Yandex Cloud, so Nikita Prudnikov spoke about our implementation and joint CTO overcoming difficulties with Yandex at Yandex Scale 2020 .
In our Black Friday article, you can read about our main scaling approaches using the example of a mailing list component that did not break last year and did not break this one.
Further development plans
Despite the results achieved, I must say that less than half of what was planned has been done. Ahead:
- Continue increasing developer income and hiring the best senior and tech leads
- The third team of the development school, which will allow hiring up to 12 developers per year
- Continued translation of the application to .NET, k8s and Yandex-cloud, auto-scaling, blue-green layout with instant rollback
- Moving towards the automatic establishment of incidents on the status page, getting rid of false SLA positives
- Migrating to .NET 5, EF.Core and PostgreSQL (and developers to new MacBooks)
- Selecting a few more large-scale pieces from the monolith
Motivated urge to grow .NET-developers tehlidov and SRE-specialists to respond to our our job to hh.ru . It will be interesting, you can gain experience unique on the market and do things.
Roadmap platforms in 2021
We felt a solid foundation under our feet, which gives us hope that we can again deliver on the promises on the business roadmap. We are trying the processes of decentralized planning for a year for the first time, but I will recklessly allow myself to form public expectations.
This year we will add to the platform:
- Scenario constructor .
- Storing and reporting anonymous orders
- More quick reports in the interface ( as in our course )
- Integration with BI
- New mobile push notifications module, including a new SDK
- The ability to quickly delete any entities, taking into account dependencies from each other
- More ML algorithms and many quality improvements to existing ones
- More pages in a new design with improved interface responsiveness
- Simplified customization of standard integrations and mechanics
The plans for 2022 are more ambitious, but I hope to write about them in a year, if the optimism is justified.
Thank you
Like client success stories, this one is the merit of specific people to whom I express my gratitude:
Nikita Prudnikov, CTO, for the vision, consistency and systematic squeezing.
Roman Ivonin, Lead Architect, for patience, team building, broad responsibility, informal leadership and sleepless nights.
Igor Kudrin, CIO, for the foundation of SRE expertise, vision and salvation of everything when no one knows how.
Rostislav, Leonid, Dmitry, Mitya, Ilya, two Artyom, Alexey, Sergey, Nikolay, Ivan, Slava, Zhenya and other caring developers, products, tech leads and SRE who made all this a reality. Sorry if I didn't mention anyone.
Special thanks to the clients who endured, despite the fact that we failed, and gave the opportunity to improve. We will make every effort to continue to get better.