
“Leave me alone, please, I am a creator! Let me create! ”- the programmer Gennady for the third time this evening recites this mantra in his head. Nevertheless, he has not yet written a single line of code, because another pull request has arrived in the library he is trying to develop. And, according to the company's policy, code reviews should take place with minimal delays. Now Gennady is thinking about what to do: without looking to accept the changes, also without looking to reject them, or still spend precious time to understand their essence. After all, who but him? He wrote this code, he will follow it. And all changes are possible only through his personal consent, because this is the Doomsday Library.
Meanwhile, literally behind the wall, a team called “Cedar Beavers” redistributes requests among themselves so that the load on viewing them falls more or less evenly. Yes, they do not deal with the Doomsday Library, but they do other tasks that require quick code changes and faster processes.
There is no one-size-fits-all solution for all cases: for some, the streamlining and speed of processes is important, somewhere a firm hand and total control may well be necessary. Moreover, at different stages of the development of the same product, different approaches may be needed to replace each other. Each of them has its own pros and cons, and based on them, we came to where we are now.
So where did we go in Wrike?
What options did we choose our own way of owning the code?
Strictly personal. We have not even considered this. Now, if Gennady forbids creating pull requests to his library, and he does all the changes personally, then you get a strictly personal approach. Surely Gennady started this way.
One of the obvious disadvantages of this approach is simply totalitarianism in the development world. Gennady is without exaggeration the only person on Earth who thoroughly knows the code, has (or not) plans for its development and can change it. The same bus, which is the "bass factor", has already left the corner. If Gennady catches a cold, then, most likely, the project will fall down with him. Another developer will have to fork, there will be a lot of them, and complete chaos will ensue.
This approach has one plus - a completely consolidated approach to development. One person makes all decisions on architecture, code style and personally solves any issue. No communication overhead.
Conditionally personal. This is exactly what Gennady does not want to do: watch all MRs, give the opportunity to change the code of his library to other people, but have full control over the changes and have the right to veto. The pros and cons are the same as in the previous paragraph, but now they are a little smoothed out by the ability to send a pull request to third-party developers directly to the repository, and not draw up a technical specification for the implementation of some features.
Collectivelike Cedar Beavers. In this case, the entire team is responsible for the code, and its members themselves decide who will watch which request.
Among the advantages, one can note the high speed of reviewing the review, the distribution of expertise between the team members and a decrease in the bus factor. Of course, there are also disadvantages. In discussions on the Internet, many mention the lack of responsibility if it is "spread" between several people. But it depends on the structure of the team and the culture of the developers: the Senior Developer or the team lead can be responsible for the team, then he will be the entry point for questions. And MR and writing new features can be divided according to the level of developer training. After all, it would be wrong to give a newbie who is just starting to understand the architecture of the application to refactor the code.
At Wrike, we take a collaborative approach to code ownership, with the team leader as the primary responsibility. This person has the most expertise in the code, knows which developer is competent in the review of a particular complexity, and bears full responsibility for the quality of the team's code.
But the path to the technical implementation of this solution was not the easiest one. Yes, in words everything sounds pretty easy: here's a feature, here's a command. The team knows what it is responsible for, which means it will monitor it.
Such agreements can work as a verbal contract if the number of commands is less than the number of fingers on a hand. And in our case, it is more than thirty commands and millions of lines of code. Moreover, often the boundaries of a feature cannot be designated by a repository: there are quite close integrations of some features into others.
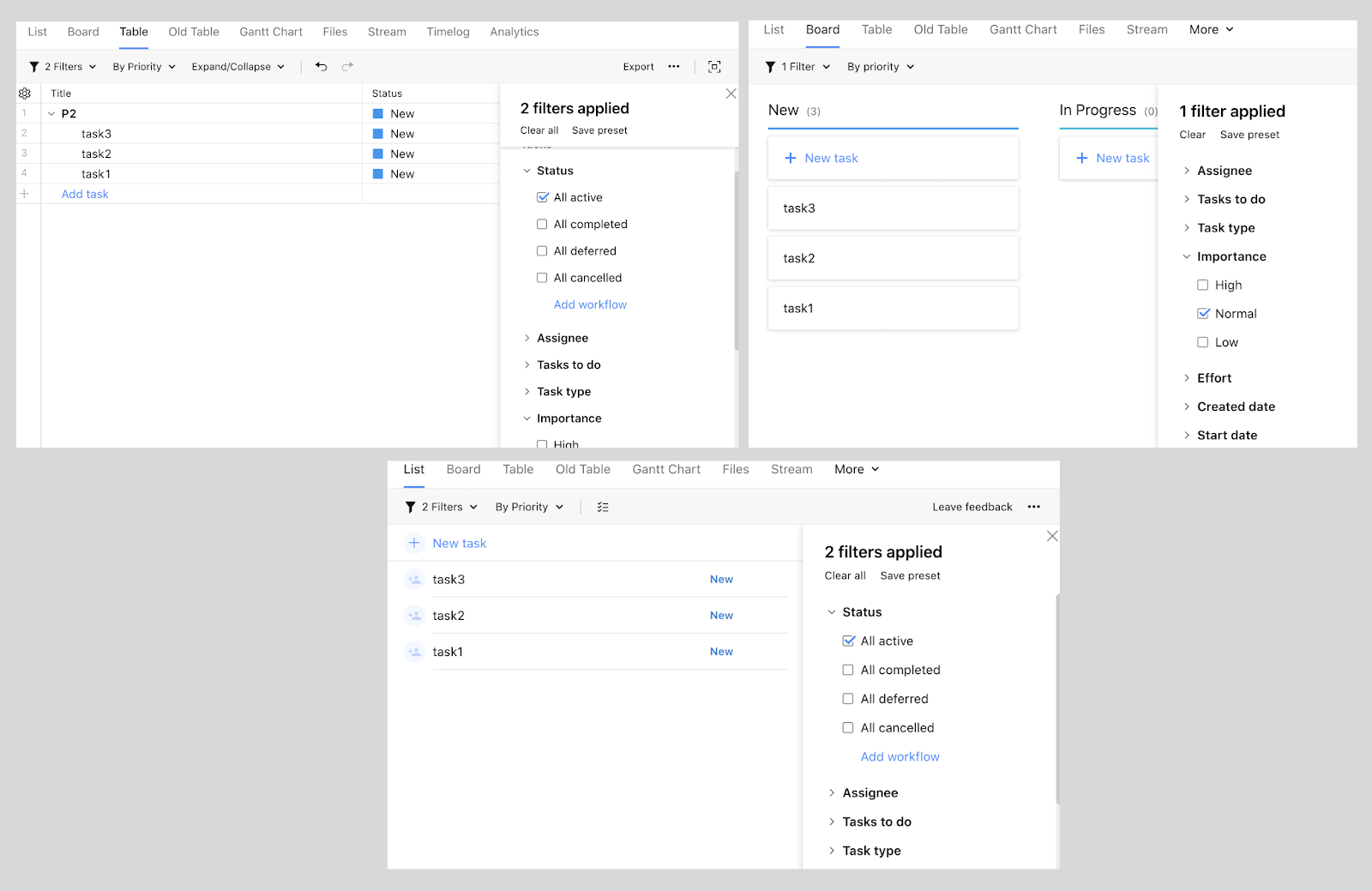 The filter panel on the right is the same for all views. This is a feature of the "A" team. Moreover, all views are features of the other three teams.
The filter panel on the right is the same for all views. This is a feature of the "A" team. Moreover, all views are features of the other three teams.
The most obvious example is filters. They look and behave the same in all possible views, while the views themselves may differ in functionality. This means that the view belongs to one team, and the single filter panel belongs to another. And so dozens of repositories, thousands of files of different code. Who should you go to with a review if you need to make changes to a specific file?
At first we tried to solve this problem with a simple JSON file that was in the root of the repository. There was a description of the functionality and the names of the responsible people. They could be contacted to get a review for their pull request.
It's a bit like a conditional personal code ownership model. The only exception is that not one person is listed as responsible, but two or three. But this approach never worked for us: people switched to other teams, got sick, went on vacation, quit, and each time we had to first look for someone who replaces the specified owner, and then tell the owners to manually change the name and push the changes.
Later, they moved from specific people to specifying commands.However, everything is in the same JSON file. It didn't get much better, because now it was necessary to find team members to whom the code could be submitted for review. And we have hundreds (a little cunning, almost 70) front-end developers, and it was not easy to find all the participants at that time. The ownership system has already become collective, but finding the right people was sometimes no easier than looking for a deputy owner from the previous version. Plus the problem with the code, in which several features could intersect, still could not be solved.
Therefore, it was critically important to solve two questions: how to assign certain features to a certain team within the repository of another team and how to make information simple and accessible for all teams that may own the code.
Why the ready-made tools didn't fit us. There are tools on the market for assigning people to reviews and associating specific individuals with a code. When using them, you do not need to resort to creating files with the names of people to whom you need to run in case of reviews, bugs, complex refactorings.
At Azure DevOps Services has functionality - Automatically include code reviewer. The name speaks for itself, and one former colleague of mine says that they use this tool in their company and very successfully. We do not work with Azure, so it would be great to hear from readers how things are going with the autoreviewer.
We use GitLab, so it would be logical to look towards GitLab Code Owners. But the principle of operation of this tool did not suit us: the functionality of GitLab is a bunch of paths in the repository (files and folders) and people through their accounts in GitLab. This bundle is written to a special file - codeowners.md. We needed a bunch of path and feature. Moreover, our features are contained in a special dictionary, where they are assigned to the command. This allows you to mark up complex features that may exist in more than one repository, be developed by several teams, and, again, not be tied to specific names. Plus, we had plans to use this information to create a convenient directory of teams, related features and all team members.
As a result, we decided to create our own code ownership control system. The implementation of the first version of our system was based on the capabilities of the Dart SDK , because at first it was launched for the front-end department repositories and only for Dart files. We used our own meta tags (fortunately, this is supported at the language level), then we ran through all the source files with a static analyzer and made something like a table: File / Feature - Owner command. You can mark both separate files and entire paths with several folders.
After some time, markup with features became available for code in Dart, JS and Java, and this is the entire code base: both the frontend and the backend. In order to obtain information about the owners, a static analyzer is used. But, of course, not the same as in the first version and worked only with Dart code. For example, for Java files, the javaparser library is used . These analyzers run on schedule and collect all relevant information in a single registry.
In addition to binding certain code to the owner teams, we built an integration with the service for collecting errors in production and posted all the useful information about teams and features on an internal resource. Now any employee can see who to run to if they suddenly have questions in a particular view. And we also made it automatic to create tasks for those responsible in case of some global changes, such as moving to a new version of Dart or Angular.
 By clicking on the command, you can see all the features, all team members, which features are purely technical, and which are product
By clicking on the command, you can see all the features, all team members, which features are purely technical, and which are product
As a result, we got not only a rather flexible system for linking features with teams, but also a full-fledged infrastructure that helps, starting from the code, to find a feature associated with it, a team with all participants, a product owner of a feature, and bug reports.
Among the disadvantages are the need to closely monitor the markup of features when refactoring and transferring code from one place to another, and the need for additional power to collect all the information about the markup.
How do you solve the problem of owning your code? And are there any related problems and, most importantly, their solution?