- Research Article
- Pytorch : YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7 ( main repository - use to reproduce results)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- Darknet : YOLOv4-tiny, YOLOv4-CSP, YOLOv4x-MISH
- YOLOv4-CSP structure
Scaled YOLO v4 is the most accurate neural network ( 55.8% AP ) on the Microsoft COCO dataset of any published neural network to date. And it is also the best in terms of the ratio of speed to accuracy in the entire range of accuracy and speed from 15 FPS to 1774 FPS . At the moment it is the Top1 neural network for object detection.
Scaled YOLO v4 outperforms neural networks in accuracy:
- Google EfficientDet D7x / DetectoRS or SpineNet-190 (self-trained on extra-data)
- Amazon Cascade-RCNN ResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
We show that YOLO and Cross-Stage-Partial (CSP) Network approaches are the best in terms of both absolute accuracy and accuracy-to-speed ratio.
Graph of Accuracy (vertical axis) and Latency (horizontal axis) on GPU Tesla V100 (Volta) with batch = 1 without using TensorRT:
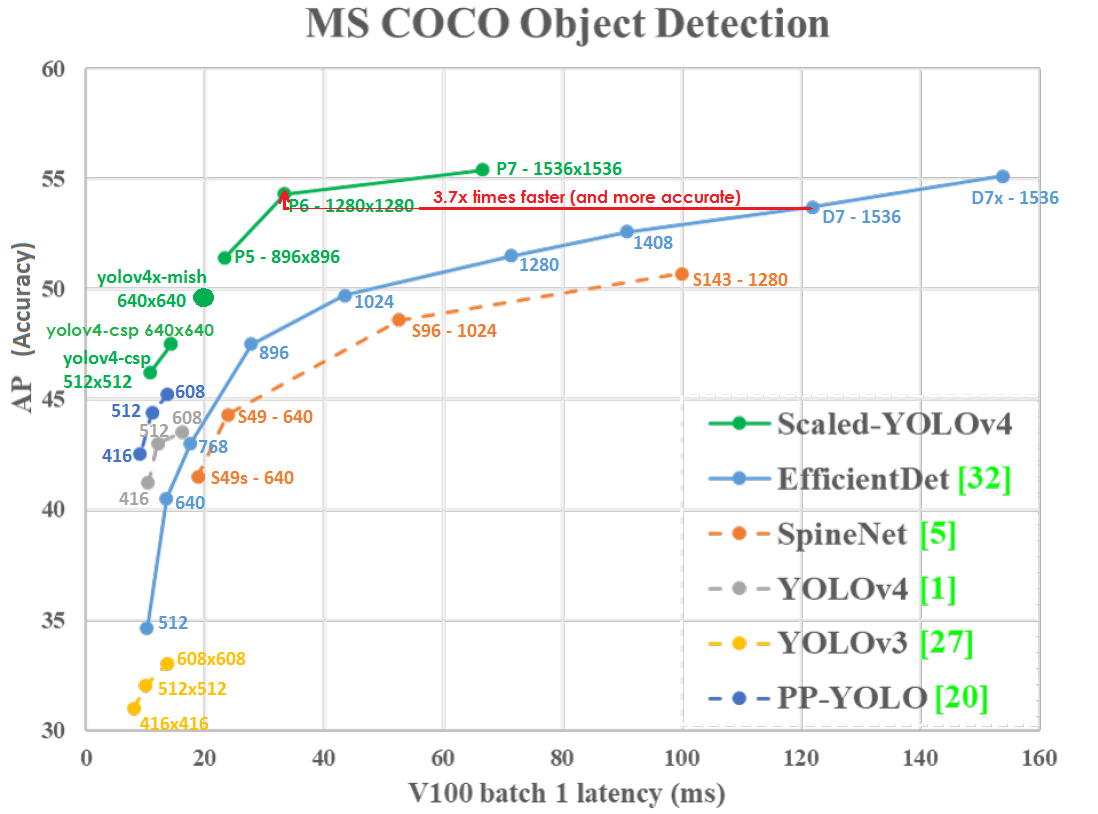
Even at a lower network resolution, Scaled-YOLOv4-P6 (1280x1280) 30 FPS is slightly more accurate and 3.7x faster than EfficientDetD7 (1536x1536) 8.2 FPS. Those. YOLOv4 makes better use of network resolution.
Scaled YOLO v4 lies on the Pareto optimality curve - no matter what other neural network you take, there is always such a YOLOv4 network, which is either more accurate at the same speed, or faster with the same accuracy, i.e. YOLOv4 is the best in terms of speed and accuracy.
Scaled YOLOv4 is more accurate and faster than neural networks:
- Google EfficientDet D0-D7x
- Google SpineNet S49s - S143
- Baidu Paddle-Paddle PP YOLO
- And many others
Scaled YOLO v4 is a series of neural networks built from the improved and scaled YOLOv4 network. Our neural network was trained from scratch without using pre-trained weights (Imagenet or any other).
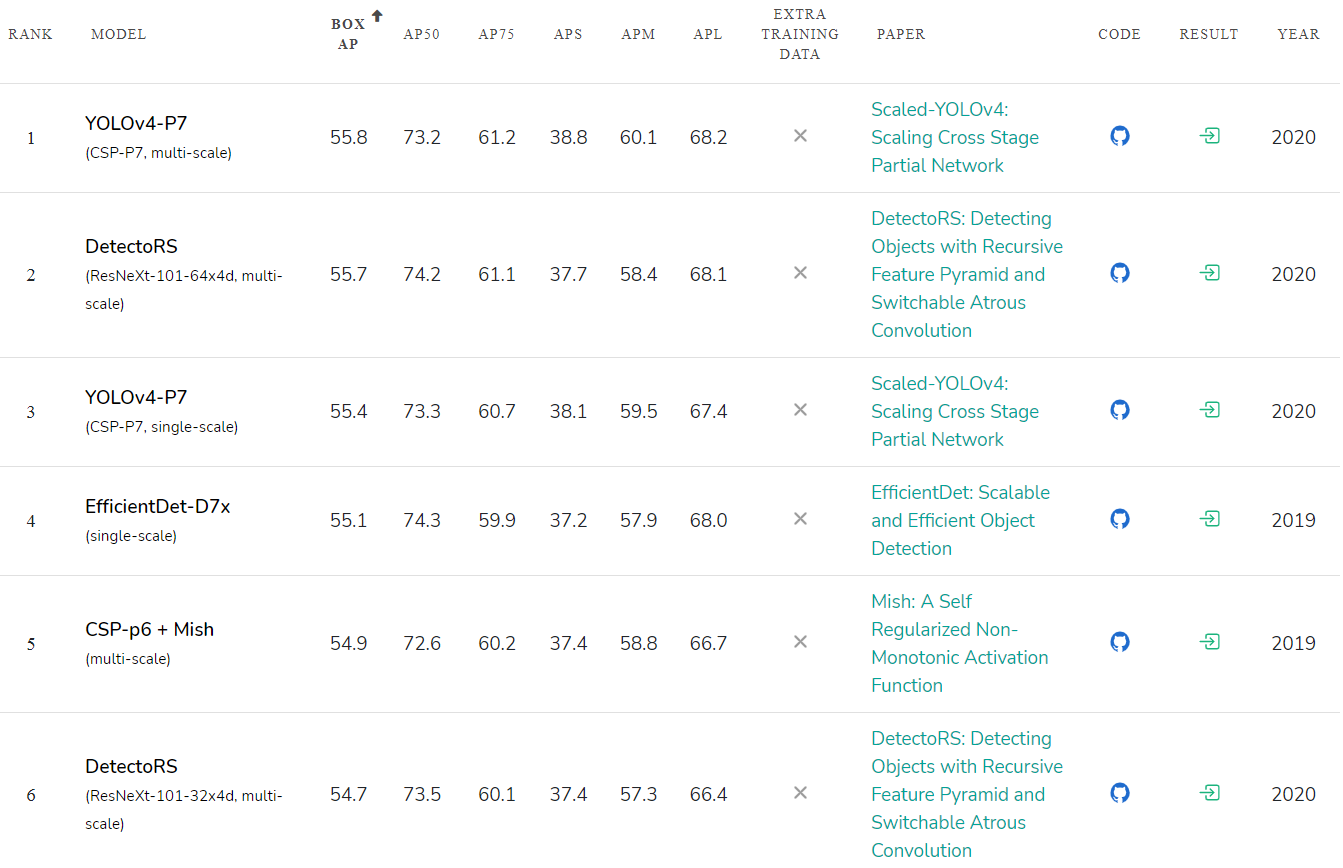
Accuracy rating of published neural networks: paperswithcode.com/sota/object-detection-on-coco :
YOLOv4-tiny neural network speed reaches 1774 FPS on a gaming GPU RTX 2080Ti using TensorRT + tkDNN (batch = 4, FP16): github. com / ceccocats / tkDNN
YOLOv4-tiny can run in real-time at 39 FPS / 25ms Latency on JetsonNano (416x416, fp16, batch = 1) tkDNN / TensorRT:

Scaled YOLOv4 uses the resources of parallel computers such as GPUs and NPUs much more efficiently. For example, GPU V100 (Volta) has performance: 14 TFLops - 112 TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
If we test both models on GPU V100 with batch = 1 , with parameters --hparams = mixed_precision = true and without --tensorrt = FP32 , then:
- YOLOv4-CSP (640x640) - 47.5% AP - 70 FPS - 120 BFlops (60 FMA)
Based on BFlops, it should be 933 FPS = (112,000 / 120), but in reality we get 70 FPS, i.e. used 7.5% GPU = (70/933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
BFlops, 2240 FPS = (112 000 / 50), 36 FPS, .. 1.6% GPU = (36 / 2240)
Those. the efficiency of computing operations on devices with massive parallel computing such as GPUs used in YOLOv4-CSP (7.5 / 1.6) = 4.7x better than the efficiency of operations used in EfficientDetD3.
Usually, neural networks are run on the CPU only in research tasks for easier debugging, and the BFlops characteristic is currently only of academic interest. In real-world tasks, real speed and accuracy are important, not performance on paper. The real speed of YOLOv4-P6 is 3.7x faster than EfficientDetD7 on GPU V100. Therefore, devices with massive parallelism GPU / NPU / TPU / DSP are almost always used with much more optimal: speed, price and heat dissipation:
- Embedded GPU (Jetson Nano / Nx)
- Mobile-GPU / NPU / DSP (Bionic-NPU / Snapdragon-DSP / Mediatek-APU / Kirin-NPU / Exynos-GPU / ...)
- TPU-Edge (Google Coral / Intel Myriad / Mobileye EyeQ5 / Tesla-motors TPU 144 TOPS-8bit)
- Cloud GPU (nVidia A100 / V100 / TitanV)
- Cloud NPU (Google-TPU, Huawei Ascend, Intel Habana, Qualcomm AI 100, ...)
Also when using neural networks On Web - usually GPU is used through the WebGL, WebAssembly, WebGPU libraries, for this case - the size of the model can matter: github.com/tensorflow/tfjs#about-this-repo
Using devices and algorithms with weak parallelism is a dead-end path of development, because it is impossible to reduce the lithograph size smaller than the size of a silicon atom to increase the processor frequency:
- The current best size for Semiconductor device fabrication is 5 nanometers.
- The crystal lattice size of silicon is 0.5 nanometers.
- The atomic radius of silicon is 0.1 nanometer.
The solution is computers with massive parallelism: on a single crystal or on several crystals connected by an interposer. Therefore, it is extremely important to create neural networks that effectively use massively parallel computing machines such as GPUs and NPUs.
Improvements in Scaled YOLOv4 over YOLOv4:
- Scaled YOLOv4 used optimal network scaling techniques to get YOLOv4-CSP -> P5 -> P6 -> P7 networks
- Improved network architecture: Backbone optimized and Neck (PAN) uses Cross-stage-partial (CSP) connections and Mish activation
- Exponential Moving Average (EMA) is used during training - this is a special case of SWA: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- For each resolution of the network, a separate neural network is trained (in YOLOv4, only one neural network was trained for all resolutions)
- Improved normalizers in [yolo] layers
- Changed activations for Width and Height, which allows faster network training
- Use the [net] letter_box = 1 parameter (preserves the aspect ratio of the input image) for high resolution networks (for all except yolov4-tiny.cfg)
Scaled-YOLOv4 neural network architecture (examples of three networks: P5, P6, P7): The

CSP connection is very efficient, simple and can be applied to any neural networks. The bottom line is that
- half of the output signal goes along the main path (generating more semantic information with a large receptive field)
- and the other half of the signal follows a detour (retaining more spatial information with a small receptive field)
The simplest example of a CSP connection (on the left is a regular network, on the right is a CSP network):

An example of a CSP connection in YOLOv4-CSP / P5 / P6 / P7
(on the left is a regular network, on the right is a CSP network):

In YOLOv4-tiny there are 2 CSP connections :

YOLOv4 is used in various fields and tasks:
- Taiwanese government: Traffic control www.taiwannews.com.tw/en/news/3957400 and youtu.be/IiU6wFmfVnk
- Amazon: Anti-Covid19 Distance-assistant github.com/amzn/distance-assistant and Amazon Neurochip / Amazon EC2 Inf1 instances: aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning- based-object-detection-with-an-aws-neuron-compiled-yolov4-model-on-aws-inferentia
- BMW Innovation Lab: github.com/BMW-InnovationLab
And in many other tasks….
There are implementations in various frameworks:
- Pytorch : github.com/WongKinYiu/ScaledYOLOv4
- Darknet : github.com/AlexeyAB/darknet
- TensorFlow : github.com/hunglc007/tensorflow-yolov4-tflite
- o pip install yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- The structure of the network can be viewed using the Netron utility - Visualizer for neural networks: github.com/lutzroeder/netron
How to compile and run Cloud Object Detection for free :
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- video: www.youtube.com/watch?v=mKAEGSxwOAY
How to compile and run Training in the Cloud for free :
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- video: youtu.be/mmj3nxGT2YQ
Also, the YOLOv4 approach can be used in other tasks, for example, when detecting 3D objects:
- Code - Complex-YOLOv4 (5-DOF): github.com/maudzung/Complex-YOLOv4-Pytorch
- Code - YOLO3D-YOLOv4 (7-DOF): github.com/maudzung/YOLO3D-YOLOv4-PyTorch
