
A little about myself: I am also a beginner developer, I am taking the course "Python developer". This material was not compiled as a result of remote sensing, but as a self-development. My code may be quite naive, and therefore please feel free to leave your comments in the comments. If I haven't scared you yet, please, under the cut :)
We will analyze a practical example of normalizing a flat table containing duplicate data to the state of 3NF ( third normal form ).
From this table:
Data table

let's make such a database:
DB connection diagram
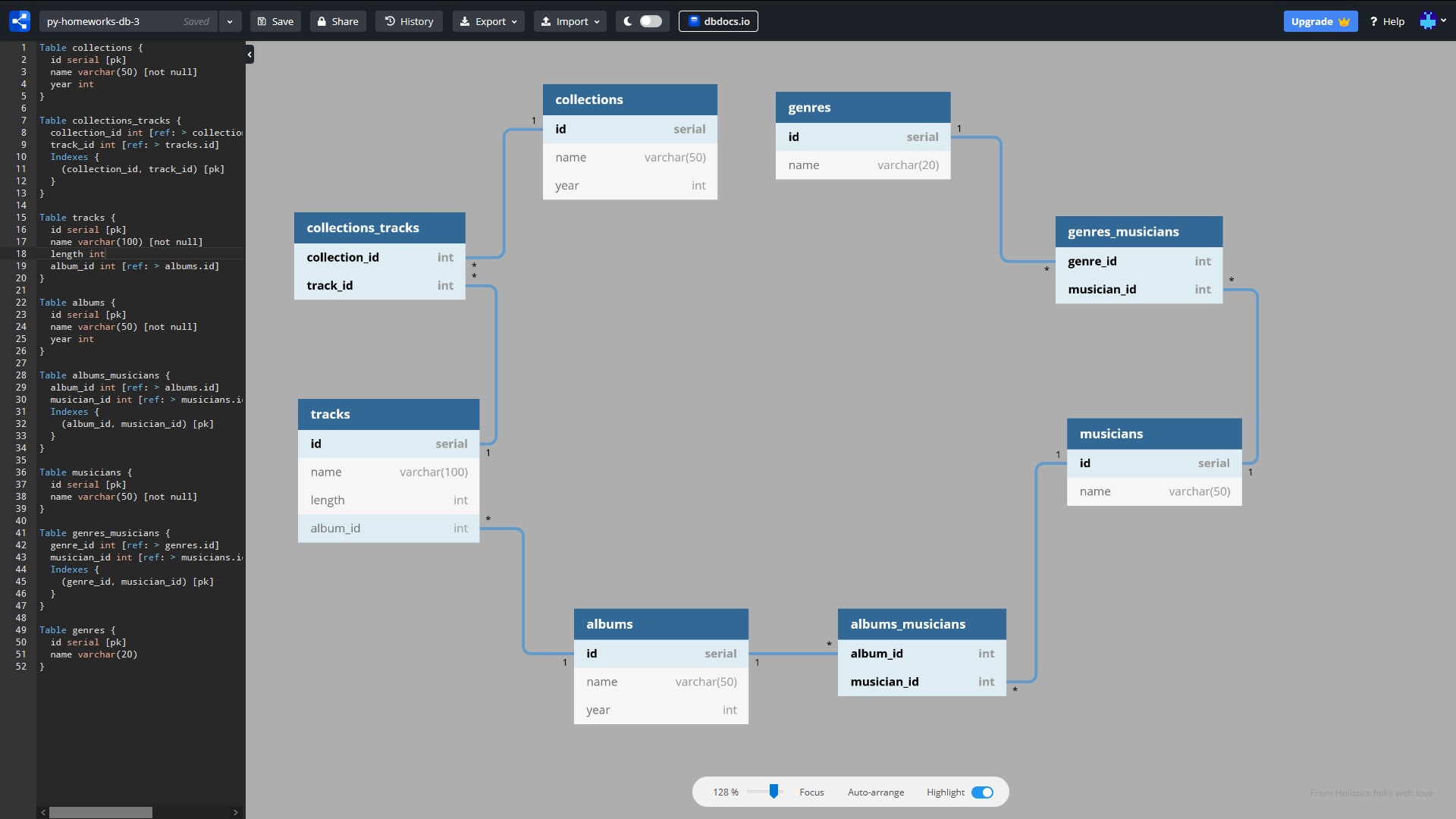
For the impatient: the code ready to run is in this repository . The interactive database schema is here . A cheat sheet for writing ORM queries is at the end of the article.
Let's agree that in the text of the article we will use the word “Table” instead of “Relationship”, and the word “Field” instead of “Attribute”. On assignment, we need to place a table with music files in the database, while eliminating data redundancy. The original table (CSV format) contains the following fields (track, genre, musician, album, length, album_year, collection, collection_year). The connections between them are as follows:
- each musician can sing in several genres, as well as several musicians can perform in one genre (many to many relationship)
- one or several musicians can participate in the creation of an album (many-to-many relationship)
- a track belongs to only one album (one to many relationship)
- tracks can be included in several collections (many-to-many relationship)
- the track may not be included in any collection.
For simplicity, let's say genre names, artist names, album and collection names are not repeated. Track names can be repeated. We have designed 8 tables in the database:
- genres (genres)
- genres_musicians (staging table)
- musicians (musicians)
- albums_musicians (intermediate table)
- albums (albums)
- tracks
- collections_tracks (staging table)
- collections (collections)
* this scheme is test, taken from one of the DZ, it has some drawbacks - for example, there is no connection between the tracks and the musician, as well as the track with the genre. But this is not essential for learning, and we will omit this disadvantage.
For the test, I created two databases on the local Postgres: "TestSQL" and "TestORM", access to them: login and password test. Let's finally write some code!
Create connections and tables
Create connections to the database
* read_data clear_db .
DSN_SQL = 'postgresql://test:test@localhost:5432/TestSQL'
DSN_ORM = 'postgresql://test:test@localhost:5432/TestORM'
# CSV .
DATA = read_data('data/demo-data.csv')
print('Connecting to DB\'s...')
# , .
engine_orm = sa.create_engine(DSN_ORM)
Session_ORM = sessionmaker(bind=engine_orm)
session_orm = Session_ORM()
engine_sql = sa.create_engine(DSN_SQL)
Session_SQL = sessionmaker(bind=engine_sql)
session_sql = Session_SQL()
print('Clearing the bases...')
# . .
clear_db(sa, engine_sql)
clear_db(sa, engine_orm)
We create tables in the classical way using SQL
* read_query . .
print('\nPreparing data for SQL job...')
print('Creating empty tables...')
session_sql.execute(read_query('queries/create-tables.sql'))
session_sql.commit()
print('\nAdding musicians...')
query = read_query('queries/insert-musicians.sql')
res = session_sql.execute(query.format(','.join({f"('{x['musician']}')" for x in DATA})))
print(f'Inserted {res.rowcount} musicians.')
print('\nAdding genres...')
query = read_query('queries/insert-genres.sql')
res = session_sql.execute(query.format(','.join({f"('{x['genre']}')" for x in DATA})))
print(f'Inserted {res.rowcount} genres.')
print('\nLinking musicians with genres...')
# assume that musician + genre has to be unique
genres_musicians = {x['musician'] + x['genre']: [x['musician'], x['genre']] for x in DATA}
query = read_query('queries/insert-genre-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, value in genres_musicians.items():
res += session_sql.execute(query.format(value[1], value[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding albums...')
# assume that albums has to be unique
albums = {x['album']: x['album_year'] for x in DATA}
query = read_query('queries/insert-albums.sql')
res = session_sql.execute(query.format(','.join({f"('{x}', '{y}')" for x, y in albums.items()})))
print(f'Inserted {res.rowcount} albums.')
print('\nLinking musicians with albums...')
# assume that musicians + album has to be unique
albums_musicians = {x['musician'] + x['album']: [x['musician'], x['album']] for x in DATA}
query = read_query('queries/insert-album-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, values in albums_musicians.items():
res += session_sql.execute(query.format(values[1], values[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding tracks...')
query = read_query('queries/insert-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['track'], item['length'], item['album'])).rowcount
print(f'Inserted {res} tracks.')
print('\nAdding collections...')
query = read_query('queries/insert-collections.sql')
res = session_sql.execute(query.format(','.join({f"('{x['collection']}', {x['collection_year']})" for x in DATA if x['collection'] and x['collection_year']})))
print(f'Inserted {res.rowcount} collections.')
print('\nLinking collections with tracks...')
query = read_query('queries/insert-collection-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['collection'], item['track'])).rowcount
print(f'Inserted {res} connections.')
session_sql.commit()
In fact, we create directories in packages (genres, musicians, albums, collections), and then in a loop we link the rest of the data and manually build intermediate tables. Run the code and see that the database has been created. The main thing is not to forget to call commit () on the session.
Now we are trying to do the same, but using the ORM approach. In order to work with ORM, we need to describe data classes. For this, we will create 8 classes (one for each table).
List of DB classes
.
Base = declarative_base()
class Genre(Base):
__tablename__ = 'genres'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(20), unique=True)
# Musician genres_musicians
musicians = relationship("Musician", secondary='genres_musicians')
class Musician(Base):
__tablename__ = 'musicians'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
# Genre genres_musicians
genres = relationship("Genre", secondary='genres_musicians')
# Album albums_musicians
albums = relationship("Album", secondary='albums_musicians')
class GenreMusician(Base):
__tablename__ = 'genres_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('genre_id', 'musician_id'),)
#
genre_id = sa.Column(sa.Integer, sa.ForeignKey('genres.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Album(Base):
__tablename__ = 'albums'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
year = sa.Column(sa.Integer)
# Musician albums_musicians
musicians = relationship("Musician", secondary='albums_musicians')
class AlbumMusician(Base):
__tablename__ = 'albums_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('album_id', 'musician_id'),)
#
album_id = sa.Column(sa.Integer, sa.ForeignKey('albums.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Track(Base):
__tablename__ = 'tracks'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(100))
length = sa.Column(sa.Integer)
# album_id ,
album_id = sa.Column(sa.Integer, ForeignKey('albums.id'))
# Collection collections_tracks
collections = relationship("Collection", secondary='collections_tracks')
class Collection(Base):
__tablename__ = 'collections'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50))
year = sa.Column(sa.Integer)
# Track collections_tracks
tracks = relationship("Track", secondary='collections_tracks')
class CollectionTrack(Base):
__tablename__ = 'collections_tracks'
# ,
__table_args__ = (PrimaryKeyConstraint('collection_id', 'track_id'),)
#
collection_id = sa.Column(sa.Integer, sa.ForeignKey('collections.id'))
track_id = sa.Column(sa.Integer, sa.ForeignKey('tracks.id'))
We just need to create a base class Base for the declarative style of describing tables and inherit from it. All the magic of table relationships lies in the correct use of relationship and ForeignKey. The code indicates in which case we create which relationship. The main thing is not to forget to register the relationship on both sides of the many-to-many relationship.
Directly creating tables using the ORM approach is done by calling:
Base.metadata.create_all(engine_orm)
And this is where the magic comes in, literally all classes declared in the code through inheritance from Base become tables. Immediately, I did not see how to specify the instances of which classes should be created now, and which ones should be postponed for creation later (for example, in another database). Surely there is such a way, but in our code all classes inheriting from Base are instantiated at once, keep this in mind.
Filling tables using the ORM approach looks like this:
Populating tables with data via ORM
print('\nPreparing data for ORM job...')
for item in DATA:
#
genre = session_orm.query(Genre).filter_by(name=item['genre']).scalar()
if not genre:
genre = Genre(name=item['genre'])
session_orm.add(genre)
#
musician = session_orm.query(Musician).filter_by(name=item['musician']).scalar()
if not musician:
musician = Musician(name=item['musician'])
musician.genres.append(genre)
session_orm.add(musician)
#
album = session_orm.query(Album).filter_by(name=item['album']).scalar()
if not album:
album = Album(name=item['album'], year=item['album_year'])
album.musicians.append(musician)
session_orm.add(album)
#
# ,
#
track = session_orm.query(Track).join(Album).filter(and_(Track.name == item['track'],
Album.name == item['album'])).scalar()
if not track:
track = Track(name=item['track'], length=item['length'])
track.album_id = album.id
session_orm.add(track)
# ,
if item['collection']:
collection = session_orm.query(Collection).filter_by(name=item['collection']).scalar()
if not collection:
collection = Collection(name=item['collection'], year=item['collection_year'])
collection.tracks.append(track)
session_orm.add(collection)
session_orm.commit()
You have to fill out each reference book (genres, musicians, albums, collections) by the piece. In the case of SQL queries, it was possible to generate batch data additions. But intermediate tables do not need to be explicitly created, the internal mechanisms of SQLAlchemy are responsible for this.
Database queries
On assignment, we need to write 15 queries using both SQL and ORM techniques. Here is a list of the questions posed in order of increasing difficulty:
- title and release year of albums released in 2018;
- title and duration of the longest track;
- the name of the tracks, the duration of which is at least 3.5 minutes;
- titles of collections published in the period from 2018 to 2020 inclusive;
- performers whose name consists of 1 word;
- the name of the tracks that contain the word "me".
- the number of performers in each genre;
- the number of tracks included in the 2019-2020 albums;
- average track length for each album;
- all artists who have not released albums in 2020;
- titles of collections in which a specific artist is present;
- the name of the albums in which there are performers of more than 1 genre;
- the name of the tracks that are not included in the collections;
- the artist (s) who wrote the shortest track (theoretically there can be several such tracks);
- the name of the albums containing the smallest number of tracks.
As you can see, the above questions imply both simple selection and joining tables, as well as the use of aggregate functions.
Below are solutions for each of the 15 queries in two options (using SQL and ORM). In the code, the requests come in pairs to show that the results are identical on the console output.
Requests and their brief description
print('\n1. All albums from 2018:')
query = read_query('queries/select-album-by-year.sql').format(2018)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).filter_by(year=2018):
print(item.name)
print('\n2. Longest track:')
query = read_query('queries/select-longest-track.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1):
print(f'{item.name}, {item.length}')
print('\n3. Tracks with length not less 3.5min:')
query = read_query('queries/select-tracks-over-length.sql').format(310)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc()):
print(f'{item.name}, {item.length}')
print('\n4. Collections between 2018 and 2020 years (inclusive):')
query = read_query('queries/select-collections-by-year.sql').format(2018, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).filter(2018 <= Collection.year,
Collection.year <= 2020):
print(item.name)
print('\n5. Musicians with name that contains not more 1 word:')
query = read_query('queries/select-musicians-by-name.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Musician).filter(Musician.name.notlike('%% %%')):
print(item.name)
print('\n6. Tracks that contains word "me" in name:')
query = read_query('queries/select-tracks-by-name.sql').format('me')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(Track.name.like('%%me%%')):
print(item.name)
print('Ok, let\'s start serious work')
print('\n7. How many musicians plays in each genres:')
query = read_query('queries/count-musicians-by-genres.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(
Genre.id):
print(f'{item.name}, {len(item.musicians)}')
print('\n8. How many tracks in all albums 2019-2020:')
query = read_query('queries/count-tracks-in-albums-by-year.sql').format(2019, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020):
print(f'{item[0].name}, {item[1].year}')
print('\n9. Average track length in each album:')
query = read_query('queries/count-average-tracks-by-album.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(
Album.id):
print(f'{item[0].name}, {item[1]}')
print('\n10. All musicians that have no albums in 2020:')
query = read_query('queries/select-musicians-by-album-year.sql').format(2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
for item in session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(
Musician.name.asc()):
print(f'{item}')
print('\n11. All collections with musician Steve:')
query = read_query('queries/select-collection-by-musician.sql').format('Steve')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(
Musician.name == 'Steve').order_by(Collection.name):
print(f'{item.name}')
print('\n12. Albums with musicians that play in more than 1 genre:')
query = read_query('queries/select-albums-by-genres.sql').format(1)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(
Genre.name)) > 1).group_by(Album.id).order_by(Album.name):
print(f'{item.name}')
print('\n13. Tracks that not included in any collections:')
query = read_query('queries/select-absence-tracks-in-collections.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
# Important! Despite the warning, following expression does not work: "Collection.id is None"
for item in session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None):
print(f'{item.name}')
print('\n14. Musicians with shortest track length:')
query = read_query('queries/select-musicians-min-track-length.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(func.min(Track.length))
for item in session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(
Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name):
print(f'{item[0].name}, {item[1]}')
print('\n15. Albums with minimum number of tracks:')
query = read_query('queries/select-albums-with-minimum-tracks.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
for item in session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name):
print(f'{item.name}')
For those who do not want to dive into reading the code, I will try to show how "raw" SQL and its alternative looks like in an ORM expression, let's go!
Cheat sheet for matching SQL queries and ORM expressions
1.title and release year of 2018 albums:
SQL
select name
from albums
where year=2018
ORM
session_orm.query(Album).filter_by(year=2018)
2. title and duration of the longest track:
SQL
select name, length
from tracks
order by length DESC
limit 1
ORM
session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1)
3.the name of the tracks, the duration of which is not less than 3.5 minutes:
SQL
select name, length
from tracks
where length >= 310
order by length DESC
ORM
session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc())
4.the names of the collections published in the period from 2018 to 2020 inclusive:
SQL
select name
from collections
where (year >= 2018) and (year <= 2020)
ORM
session_orm.query(Collection).filter(2018 <= Collection.year, Collection.year <= 2020)
* note that hereinafter, filtering is specified using filter, and not using filter_by.
5.executors whose name consists of 1 word:
SQL
select name
from musicians
where not name like '%% %%'
ORM
session_orm.query(Musician).filter(Musician.name.notlike('%% %%'))
6. the name of the tracks that contain the word "me":
SQL
select name
from tracks
where name like '%%me%%'
ORM
session_orm.query(Track).filter(Track.name.like('%%me%%'))
7.number of performers in each genre:
SQL
select g.name, count(m.name)
from genres as g
left join genres_musicians as gm on g.id = gm.genre_id
left join musicians as m on gm.musician_id = m.id
group by g.name
order by count(m.id) DESC
ORM
session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(Genre.id)
8.number of tracks included in albums 2019-2020:
SQL
select t.name, a.year
from albums as a
left join tracks as t on t.album_id = a.id
where (a.year >= 2019) and (a.year <= 2020)
ORM
session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020)
9.average track length for each album:
SQL
select a.name, AVG(t.length)
from albums as a
left join tracks as t on t.album_id = a.id
group by a.name
order by AVG(t.length)
ORM
session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(Album.id)
10.all artists who haven't released albums in 2020:
SQL
select distinct m.name
from musicians as m
where m.name not in (
select distinct m.name
from musicians as m
left join albums_musicians as am on m.id = am.musician_id
left join albums as a on a.id = am.album_id
where a.year = 2020
)
order by m.name
ORM
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(Musician.name.asc())
11.the names of the compilations in which a specific artist (Steve) is present:
SQL
select distinct c.name
from collections as c
left join collections_tracks as ct on c.id = ct.collection_id
left join tracks as t on t.id = ct.track_id
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
where m.name like '%%Steve%%'
order by c.name
ORM
session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(Musician.name == 'Steve').order_by(Collection.name)
12.the name of albums in which artists from more than 1 genre are present:
SQL
select a.name
from albums as a
left join albums_musicians as am on a.id = am.album_id
left join musicians as m on m.id = am.musician_id
left join genres_musicians as gm on m.id = gm.musician_id
left join genres as g on g.id = gm.genre_id
group by a.name
having count(distinct g.name) > 1
order by a.name
ORM
session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(Genre.name)) > 1).group_by(Album.id).order_by(Album.name)
13.Name of tracks that are not included in collections:
SQL
select t.name
from tracks as t
left join collections_tracks as ct on t.id = ct.track_id
where ct.track_id is null
ORM
session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None)
* note that despite the warning in PyCharm, you need to compose the filtering condition this way, if you write it as suggested by the IDE ("Collection.id is None"), then it will not work.
14. artist (s) who wrote the shortest track in length (theoretically there could be several such tracks):
SQL
select m.name, t.length
from tracks as t
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
group by m.name, t.length
having t.length = (select min(length) from tracks)
order by m.name
ORM
subquery = session_orm.query(func.min(Track.length)) session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name)
15.the name of the albums containing the least number of tracks:
SQL
select distinct a.name
from albums as a
left join tracks as t on t.album_id = a.id
where t.album_id in (
select album_id
from tracks
group by album_id
having count(id) = (
select count(id)
from tracks
group by album_id
order by count
limit 1
)
)
order by a.name
ORM
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name)
As you can see, the above questions imply both simple selection and joining tables, as well as the use of aggregate functions and subqueries. All this can be done with SQLAlchemy in both SQL and ORM modes. The variety of operators and methods allows you to execute a query of any complexity.
I hope this material will help beginners quickly and efficiently start writing queries.