Among the frameworks we are considering for complex data processing in Java is Apache Flink. We would like to offer you a translation of a good article from the Analytics Vidhya blog on the Medium portal in order to assess the reader's interest. Feel free to vote!

In this article, we'll take a bottom-up look at how to streamline with Flink; in cloud services and on other platforms, streaming solutions are provided (some of which have Flink integrated under the hood). If you wanted to understand this topic from scratch, then you found exactly what you were looking for.
Our monolithic solution could not cope with the increasing volumes of incoming data; therefore, it needed to be developed. It is time to move on to a new generation in the evolution of our product. It was decided to use streaming processing. This is a new paradigm of data absorption that is superior to traditional batch processing.
Apache Flink at a glance
Apache Flink is a scalable distributed threading framework designed for operations on continuous streams of data. Within this framework, concepts such as sources, stream transformations, parallel processing, scheduling, resource assignment are used. A variety of data destinations are supported. Specifically, Apache Flink can connect to HDFS, Kafka, Amazon Kinesis, RabbitMQ, and Cassandra.
Flink is known for its high throughput and low latency, supports consistent, strictly once-only processing (all data is processed once, no duplication), and high availability. Like any other successful open source product, Flink has a large community that cultivates and expands the capabilities of this framework.
Flink can handle data streams (stream size is undefined) or datasets (dataset size is specific). This article deals specifically with thread processing (handling objects
DataStream
).
Streaming and its Inherent Challenges
Today, with the ubiquity of IoT devices and other sensors, data is continuously flowing from multiple sources. This endless stream of data requires the adaptation of traditional batch computing to new conditions.
- Streaming data unlimited; they have no beginning or end.
- New data arrives in an unpredictable manner, at irregular intervals.
- Data can arrive in a disordered manner, with different time stamps.
With such unique characteristics, data processing and querying tasks are not trivial to perform. Results can change rapidly, and it is almost impossible to draw definite conclusions; computations can sometimes block when trying to get valid results. Moreover, the results are not reproducible, since the data continues to change during the calculations. Finally, delays are another factor affecting the accuracy of the results.
Apache Flink allows you to cope with such processing problems, because it focuses on the timestamps with which the incoming data is supplied back at the source. Flink has a mechanism for accumulating events based on time stamps, put on them -– and only after accumulating the system proceeds to processing. In this case, it is possible to do without the use of micro-packages, and also in this case, the accuracy of the results is increased.
Flink implements consistent, strictly one-shot processing, which guarantees the accuracy of calculations, and the developer does not need to program anything special for this.
What Flink packages are made of
Typically, Flink absorbs streams of data from different sources. The base object is
DataStream<T>
a stream of elements of the same type. The element type in such a stream is determined at compile time by setting a generic type
T
(you can read more about this here ).
The object
DataStream
contains many useful methods for transforming, separating, and filtering data. For a start it will be useful to have an idea of what they are doing
map
,
reduce
and
filter
; these are the main transforming methods:
Map
: gets an objectT
and as a result returns an object of typeR
;MapFunction
strictly once applied to each element of the objectDataStream
.
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce
: gets two consecutive values and returns one object, combining them into an object of the same type; this method runs over all values in the group until only one of them remains.
T reduce(T value1, T value2)
Filter
: gets an objectT
and returns a stream of objectsT
; this method iterates over all elementsDataStream
, but returns only those for which the function returnstrue
.
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
Data drain
One of the main goals of Flink, along with data transformation, is to control flows and direct them to certain destinations. These places are called "drains". Flink has built-in strings (text, CSV, socket), as well as out-of-the-box mechanisms for connecting to other systems, for example, Apache Kafka .
Flink Event Tags
When processing data streams, the time factor is extremely important. There are three ways to determine the timestamp:
- ( ): , ; , . - . , .
, , . , , , ; , .
// Processing Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- : , , , Flink. , , Flink .
Flink , , , ; « » (watermark). ; Flink.
// Event Time streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream<String> dataStream = streamEnv.readFile(auditFormat, dataDir, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000). assignTimestampsAndWatermarks( new TimestampExtractor());// ... ... // public class TimestampExtractor implements AssignerWithPeriodicWatermarks<String>{ @Override public Watermark getCurrentWatermark() { return new Watermark(System.currentTimeMillis()-maxTimeFrame); } @Override public long extractTimestamp(String str, long l) { return InputData.getDataObject(str).timestamp; } }
- Absorption time: this is the point in time at which the event enters Flink; assigned when the event is in the source and therefore is considered more stable than the processing time assigned when the process starts running.
The absorption time is not suitable for handling out-of-order events or late data because the time stamp is when the absorption begins; this differs from the event time, which provides the ability to detect pending events and process them, relying on the watermark mechanism.
// Ingestion Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
You can read more about timestamps and how they affect streaming at the following link .
Window breakdown
The stream is by definition endless; hence, the processing mechanism is associated with the definition of fragments (for example, periods-windows). Thus, the stream is split into batches that are convenient for aggregation and analysis. A window definition is an operation on a DataStream object or something else that inherits from it.
There are several types of time-dependent windows:
Tumbling window (default configuration):
The stream is divided into windows of equivalent size that do not overlap with each other. As the stream flows, Flink continuously computes the data based on such a time-fixed storyboard.

Tumbling window
Implementation in code:
// ,
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// ,
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
Sliding window
Such windows can overlap with each other, and the properties of the sliding window are determined by the size of this window and the margin (when to start the next window). In this case, events related to more than one window can be processed at a given time.

Sliding window
And this is how it looks in the code:
// 1 30
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
Session Window
Includes all events within one session. The session ends if there is no activity, or if no events are recorded after a certain time period. This period can be fixed or dynamic, depending on the events being processed. In theory, if the interval between sessions is less than the window size, then the session may never end.
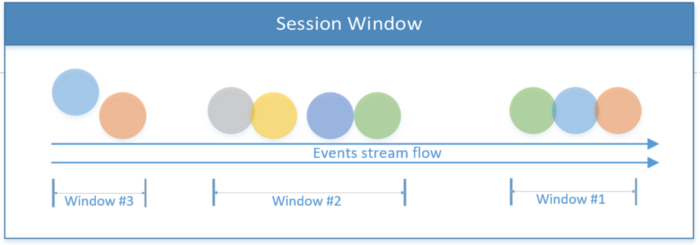
Session Window
The first code snippet below shows a session with a fixed time value (2 seconds). The second example implements a dynamic session window based on thread events.
// 2
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// ,
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// ,
}))
Global Window
The entire system is treated as a single window.

The
Flink global window also allows you to implement your own windows, the logic of which is defined by the user.
In addition to time-dependent windows, there are others, for example, the Account window, where the limit for the number of incoming events is set; when threshold X is reached, Flink processes X events.

Counting window for three events
After a theoretical introduction, let's discuss in more detail what a data flow is from a practical point of view. For more information on Apache Flink and threading, see the official website .
Stream description
As a summary of the theoretical part, the following block diagram shows the main data flows implemented in the code snippets from this article. The stream below starts from the source (files are written to the directory) and continues while processing events that are turned into objects.
The implementation depicted below has two processing paths. The one shown at the top splits one stream into two side streams, and then combines them, getting a stream of the third type. The script shown at the bottom of the diagram describes the processing of the stream, after which the results of the work are transferred to the sink.

Next, we will try to feel with our hands the practical implementation of the above theory; all the source code discussed below is posted on GitHub .
Basic Stream Processing (Example # 1)
It will be easier to grasp the concepts of Flink if you start with the simplest application. In this application, the producer writes files to a directory, thus simulating the flow of information. Flink reads files from this directory and writes summary information about them to the destination directory; this is the stock.
Next, let's take a close look at what happens during processing:
Converting raw data into an object:
// InputData;
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
The below code snippet
InputData
converts a stream object ( ) to a string and integer tuple. It extracts only certain fields from the stream of objects, grouping them by one field in two-second quanta.
//
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // KeyedStream<T, Tuple> ( 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // timeWindowAll
.timeWindow(Time.seconds(2)) // WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
Creating a destination for a stream (implementing a data sink):
//
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) //
.reduce((x,y) -> // ,
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
//
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// DataStream; inputCountSummary countSink
inputCountSummary.addSink(countSink);
Sample code for creating a data sink.
Splitting streams (example # 2)
This example demonstrates how to split the main stream using side output streams. Flink provides multiple side streams from the main stream
DataStream
. The type of data located on each side of the stream can be different from the data type of the main stream, as well as the data type of each of the side streams.
So, using a side output stream, you can kill two birds with one stone: split the stream and convert the data type of the stream to many data types (they can be unique for each side output stream).
The below code snippet is called
ProcessFunction
splitting the stream into two side ones, depending on the input property. To get the same result, we would have to use the function repeatedly
filter
.
Function
ProcessFunction
collects certain objects (based on the criterion) and sends them to the main outlet manifold (lies in
SingleOutputStreamOperator
), and the rest of the events are transmitted to the side outputs. The stream
DataStream
splits vertically and publishes different formats for each side stream.
Note that the definition of a sidestream output is based on a unique output tag (object
OutputTag
).
//
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
//
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// InputData .
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// ;
// playerTag, (" ")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// InputData
collInputData.collect(inputData);
break;
}
}
});
Sample code demonstrating how to split a stream
Combining streams (example # 3)
The last operation that will be covered in this article is thread concatenation. The idea is to combine two different streams, the data formats of which may differ, from which to collect one stream with a unified data structure. Unlike the join operation from SQL, where data is merged horizontally, streams are merged vertically, since the flow of events continues and is not limited in time.
Concatenating streams is done by calling the connect method, and then defining a display operation for each item in each individual stream. The result is a merged stream.
//
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // 1
Tuple2<String, String>, // 2
Tuple4<String, String, String, Integer> //
>() {
@Override
public Tuple4<String, String, String, Integer> // 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
Listing showing how to get a merged stream
Creating a working project
So, to recap: the demo project is uploaded to GitHub. It describes how to build and compile it. This is a good starting point to practice with Flink.
conclusions
This article describes the basic operations to create a working Flink-based threading application. The purpose of the application is to provide an overview of the critical calls inherent in streaming and to lay the foundation for the subsequent creation of a fully functional Flink application.
Because streaming has many facets and many complexities, many of the issues in this article remain unsolved; in particular, Flink execution and task management, watermarking when setting the time for streaming events, injecting state into stream events, executing stream iterations, executing SQL-like queries on streams, and much more.
We hope this article was enough to make you want to try Flink.