We continue the topic of information security and publish the translation of the article by Coussement Bruno.
Add noise to existing data, add noise only to data manipulation results, or generate synthetic data? Let's trust our intuition?

Companies are growing and their cybersecurity regulations are becoming stricter, senior architects are embracing trends ... All of this leads to the fact that the need (or obligation) to reduce the risks associated with privacy and information leakage only intensifies for data subjects.
In this case, methods of anonymizing or tokenizing data are widely used, although they also allow for the possibility of disclosing private information (see this article to understand why this happens).
Generating synthetic data
Synthetic data have a fundamental difference. The goal is to create a data generator that shows the same global statistics as the original data. Distinguishing the original from the result should be difficult for a model or person.
Let's illustrate the above by generating synthetic data on the Covertype dataset using the TGAN model .

After training the model on this table, I generated 5000 rows and plotted a histogram of the Elevation column of the original and generated set. It seems that both lines visually coincide.
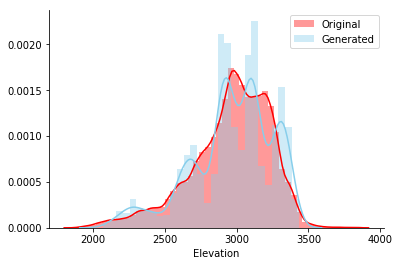
To check the relationship between pairs of bars, a paired graph of all continuous bars is shown. The shape that the blue-green dots form (generated) should visually match the shape of the red dots (original). And so it happened, cool!

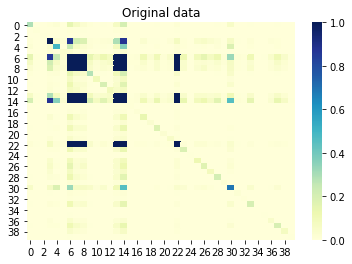
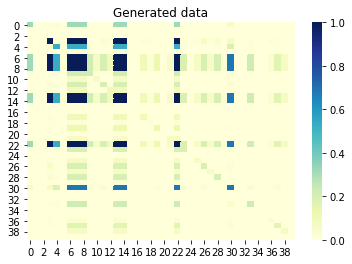
If we now look at the mutual information (also known as unsigned correlation) between columns, then the columns that are correlated with each other should also be correlated in the generated set. Conversely, non-correlated columns in the original set should not be correlated in the generated set. A value close to 0 means no correlation, and a value close to 1 means perfect correlation. Great, it is!
Mutual information between columns original set:
Mutual information between columns generated set:
As a final test, I wanted to train the nonlinear dimensionality reduction ( UMAP ) method on the original set and project the origin points into 2D space. I enter the generated set into the same projector. The orange crosses (generated) should be in the blue point clouds of the original dataset. And there is! Excellent!
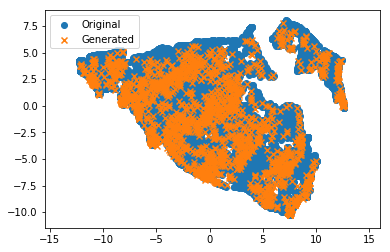
OK, experimenting with data is fun!
For more serious cases, there are 2 main approaches:
- : , . , . .
It is worth paying attention to such initiatives as Synthetic data vault , Gretel.AI , Mostly.ai , MDClone , Hazy .
Today you can write a proof-of-concept using synthetic data to solve one of the following common problems faced by IT organizations:
- No payload in development environment
Let's say you are working on a data product (it can be anything) where the data you are interested in is in a production environment with a very strict access policy. Unfortunately, you only have access to the development environment without interesting data.
- God Mode - Access Rights for Engineers and Data Scientists
Let's say you're a data scientist and suddenly an information security officer has limited your much-needed privileges to access production data. How can you continue to do a good job in such a tough, limited environment?
- Transfer of sensitive data to an untrusted external partner
You are part of Company X. Organization Y would like to showcase their latest cool data product (it could be anything).
They ask you to extract data to show the product to you.
How does synthetic data relate to differential privacy?
The main property of synthetic data generation is that, regardless of post-processing or adding third-party information, no one will ever be able to know whether an object is contained in the original set, and also will not be able to get the properties of this object. This property is part of a broader concept called "differential privacy" (DP).
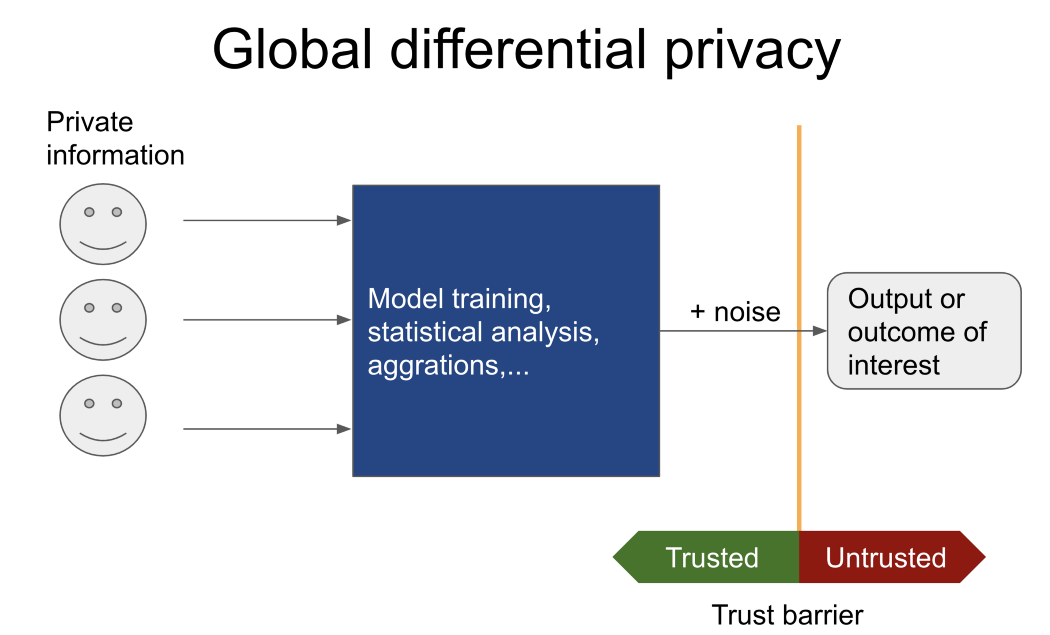
Global and local differential privacy
DP is divided into 2 types.
Often, only the result of a specific task is of interest (for example, training a model based on undisclosed data of patients from different hospitals, calculating the average number of people who have ever committed a crime, etc.), then attention should be paid to global differential privacy.
In this case, an untrusted user will never see confidential data. Instead, he or she tells a trusted curator (with global differential privacy mechanisms) who has access to sensitive data what operations to perform.
Only the result is reported to the untrusted user. I recommend Pysyftand OpenDP if you need more information on similar tools.
In contrast, if data is to be transferred to an untrusted party, the principles of local differential confidentiality come into play. Traditionally, this is accomplished by adding noise to every row in a table or database. The amount of added noise depends on:
- the required level of confidentiality (the famous epsilon in the DP literature),
- the size of the dataset (a larger dataset requires less noise to achieve the same level of confidentiality),
- column data type (quantitative, categorical, ordinal).

In theory, for an equal level of confidentiality, the global DP mechanism (adding noise to the result) will provide more accurate results than the local mechanism (line-level noise).
Thus, synthetic data generation methods can be thought of as a form of local DP.
For more information on these topics, I advise you to consult the following sources:
- www.udacity.com/course/secure-and-private-ai--ud185
- medium.com/@arbidha1412/local-and-global-differential-privacy-249aaa3571
- www.openmined.org
Recommendation
Let's now look at a more specific example. You want to share a spreadsheet containing personal information with an untrusted party.
Right now, you can either add noise to existing data lines (local DP), set up and use a robust system (global DP), or generate synthetic data based on the original.
Noise should be added to existing data lines if
- you do not know what operation will be performed on the data after publication,
- you need to periodically share an update to the original data (= have this workflow as part of a stable batch process),
- you and the data owners trust the person / team / organization to add noise to the original data.
Here I recommend starting with the OpenDP tools .
The most famous case of differential privacy is in the United States Census (see databricks.com/session_na20/using-apache-spark-and-differential-privacy-for-protecting-the-privacy-of-the-2020-census-respondents ).
This data is recalculated and updated every three years. It is mostly numerical data that is aggregated and published at multiple levels (county, state, national level).
Install and use a trusted system if
- the system you specified supports the tasks and operations that will be performed on it,
- basic data is stored in different places and cannot leave them (for example, in different hospitals),
- you and the data owners actually trust the current system and the person / team / organization that is setting it up.
As a user of sensitive data, you will get more accurate results than the first approach.
Many frameworks do not currently have all the necessary features to deploy this beast in a secure, scalable, and auditable way. There is still a lot of engineering work required here.
But as their adoption grows, DP can be a good alternative for large organizations and businesses.
I recommend starting here with OpenMined .
It is possible to generate synthetic data if
- (<1 , <100 ),
- ad-hoc ( ),
- / / , .
As with the little experiment described above, the results are promising. It also does not require excellent knowledge of DP systems. You can start today, if you need to, let it train overnight and, so to speak, prepare the shared synthetic set for tomorrow morning.
The biggest drawback is that these complex models can become expensive to train and maintain if the amount of data increases. Each table also requires its own complete model training (portable training will not work here). You won't be able to scale to hundreds of tables, even with a significant computational budget.
Otherwise, you're out of luck.
Conclusion
Since data privacy is more important now than ever, we have excellent methods for generating synthetic data or for adding noise to existing data. However, they all still have their limitations. Apart from a few niche cases, a scalable and flexible enterprise-grade tool has not yet been created that would allow data containing personal information to be transferred to untrusted parties.
Data owners still need to trust established methods or systems, which requires a lot of trust from them. This is the biggest problem!
In the meantime, if you want to give it a try (proof of concept, just test it out), open any of the links above.