Obsessive melody (English earworms.) - a well-known and sometimes irritating phenomenon. Once one of these gets stuck in the head, it can be difficult to get rid of it. Research has shown that so-called interaction with the original composition , whether listening to it or singing it, helps to drive away the intrusive melody. But what if you can't remember the name of the song, but can only hum the tune?
When using existing methods of comparing a sung melody with its original polyphonic studio recording, a number of difficulties arise. The sound of a live or studio recording with lyrics, backing vocals and instruments can be very different from what a person hums. In addition, by mistake or by design, our version may not have exactly the same pitch, key, tempo or rhythm. This is why so many current approaches to the query by humming system map a sung melody to a database of pre-existing melodies or other sung versions of that song, rather than identifying it directly. However, this type of approach is often based on a limited database that requires manual updating. Hum to Search
launched in Octoberis a new, fully machine-learning Google Search system that allows a person to find a song by singing or rushing it. Unlike existing methods, this approach creates an embedding from the spectrogram of the song, bypassing the intermediate representation. This allows the model to compare our melody directly to the original (polyphonic) recording without having to have a different melody or MIDI version of each track. There is also no need to use complex hand-crafted logic to extract the melody. This approach greatly simplifies the database for Hum to Search, allowing you to constantly add embeddings of original tracks from around the world, even the most recent releases, to it.
How it works
Many existing music recognition systems convert the audio sample into a spectrogram to find a more correct match before processing an audio sample. However, there is one problem with recognizing a sung melody - it often contains relatively little information, as in this example of the song "Bella Ciao" . The difference between the sung version and the same segment from the corresponding studio recording can be visualized using the spectrograms shown below:

Visualization of the sung snippet and its studio recording
Given the image on the left, the model must find the audio that matches the image on the right in a collection of more than 50 million similar images (corresponding to segments of studio recordings of other songs). To do this, the model must learn to focus on the dominant melody and ignore the backing vocals, instruments and timbre of the voice, as well as differences due to background noise or reverberation. To determine by eye the dominant melody that could be used to compare the two spectrograms, you can look for similarities in the lines at the bottom of the above images.
Previous attempts to implement music recognition, particularly music in cafes or clubs, have demonstrated how machine learning can be applied to this problem. Now Playing , released in 2017 for Pixel phones, uses a built-in deep neural network to recognize songs without the need for a server connection, while Sound Search , which later developed the technology, uses server-based recognition to quickly and accurately search over 100 million songs. We also needed to apply what we learned in these releases to recognize music from a similarly large library, but already from the sung passages.
Setting up machine learning
The first step in the evolution of Hum to Search was to change the music recognition models used in Now Playing and Sound Search to work with recordings of melodies. Basically, many similar search engines (like image recognition) work in a similar way. In the process of training, the neural network receives a pair (a melody and an original recording) as input and creates their embeddings, which will later be used to match the sung melody.

Setting up neural network training
To ensure recognition of what we are singing, the embeddings of audio pairs with the same melody must be located next to each other, even if they have different instrumental accompaniment and singing voices. Audio pairs containing different melodies should be far apart. In the process of training, the network receives such audio pairs until it learns how to create embeddings with this property.
Ultimately, the trained model will be able to generate embeddings for our tunes, similar to the embeddings of master recordings of songs. In this case, finding the right song is just a matter of searching the database for similar embeddings calculated on the basis of audio recordings of popular music.
Training data
Since training the model required pairs of songs (recorded and sung), the first challenge was to get enough data. Our original dataset consisted mostly of sung snippets (very few of them contained just a hum of a motif without words). To make the model more reliable, during training, we applied augmentation to these fragments: we changed the pitch and tempo in a random order. The resulting model worked well enough for examples where the song was sung rather than hummed or whistled.
To improve the model's performance on wordless melodies, we generated additional training data with artificial "hum" from the existing set of audio data. For this, we used SPICE , a pitch extraction model developed by our extended team as part of a projectFreddieMeter . SPICE extracts the pitch values from a given audio, which we then use to generate a melody consisting of discrete audio tones. The very first version of this system has transformed the original passage here in this .
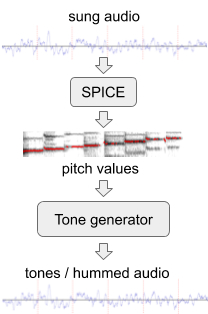
Generating "hum" from a sung audio fragment.
Later we improved the approach by replacing a simple tone generator with a neural network that generates a sound that resembles a real hum of a motif without words. For example, the above snippet can be transformed into such a hum or whistle .
In the final step, we compared the training data by mixing and matching audio snippets. When, for example, we came across similar snippets from two different artists, we aligned them with our preliminary models and therefore provided the model with an additional pair of audio snippets of the same melody.
Improving the model
When training the Hum to Search model, we started with triplet loss , which has proven itself to be excellent in various classification tasks such as classifying images and recorded music . If a pair of audio is given that matches the same melody (the R and P points in the embedding space shown below), the triplet loss function ignores certain parts of the training data derived from the other melody. This helps to improve learning behavior when the model finds another melody that is too simple and already far from R and P (see point E). And also when it is too complex for the current stage of model training and turns out to be too close to R (see point H).

Examples of audio segments rendered as points in space
We have found that we can improve the accuracy of the model by taking into account additional training data (points H and E), namely by formulating the general concept of model confidence in a series of examples: how confident is the model that all data, with whom she worked can be classified correctly? Or did she come across examples that do not correspond to her current understanding? Based on this, we have added a loss function that brings the model confidence closer to 100% in all areas of the embedding space, resulting in improved memory quality and accuracy of our model .
The aforementioned changes, specifically augmentation and training data combination, allowed the neural network model used in Google search to recognize sung tunes. The current system achieves a high level of accuracy based on a database of over half a million songs that we constantly update. This collection of tracks has room to grow, with more music from around the world to be included.
To test this feature, open the latest version of the Google app, click on the microphone icon and say "What's this song" or click on "Find a song". Now you can hum or whistle a melody! We hope Hum to Search will help you get rid of intrusive melodies or just find and listen to a track without entering its name.