CT scan with frosted glass areas
Patients with confirmed COVID-19 undergo a computed tomography of the lungs. If you're lucky - once, if not - several times. For the first time, you need to estimate the level of damage in percentage. Depending on the quartile of the degree of damage, the further treatment regimen is determined, and they are strikingly different. In April 2020, we learned that there are two difficulties:
- CT is a three-dimensional image, each layer of such an image is called a slice. With 300-800 lung slices on CT, doctors spend 1 to 15 minutes looking for characteristic zones to determine the extent of the lesion. One minute is "by eye", 30 minutes is the average for manual selection and counting of areas of damaged tissue. In difficult cases, the result can be processed up to an hour.
- The accuracy of diagnosing the level of coronavirus infection by experts "by eye" is high at the borders of 0-30% and 70-100%. In the range of 30–70, the error is very high, and we noticed that some of the radiologists, as a rule, systematically overestimate the percentage of damage to the eye, while others underestimate.
The task is reduced to determining the damaged tissue of the lungs and calculating the proportion of their volume to the total lungs.
At the end of April, in cooperation with clinics, we prepared a dataset of anonymized studies of patients with confirmed PCR analysis of COVID-19, gave a committee of ten excellent expert radiologists and mapped out a sample for training with a teacher.
There was beta at the end of May. In July, there was a ready-made model for various types of CT equipment used in Russia. We are a team at Sberbank's Artificial Intelligence Laboratory. In general, we publish our developments in scientific literature (MICCAI, AIME, BIOSIGNALS), and we will talk about this even on AI Journey.
Why is it important
Radiologists have already received queues at the end of April. It was important:
- Increase the throughput of points with CT examinations.
- Increase the accuracy of research secondly.
- Make it possible to accurately see the change in the level of lesion between the images of one patient (and this can be a couple of percent, it is important to understand whether it has become more or less).
Further, in the first wave, the situation became worse, because experienced radiologists got sick and left the process. Accuracy and speed dropped.
Artificial intelligence is good at classifying medical data. Correct patient prioritization saves lives, because the more accurately we determine the degree of injury, the more chances that a seriously ill person will receive the necessary drugs and (if everything went worse) mechanical ventilation on time. And that a person whose lungs are not so badly affected will not take his place in the hospital.
Assessment of the proportion of lesions is one of the most difficult and resource-intensive tasks for a person in diagnostics, because it is necessary to assess a large volume of irregular foci, divided into many sections.
The task itself
At the entrance - axial slices of a certain thickness. Usually, the settings are set from 0.5 mm to 2.5 mm. The ribcage is 300 to 800 2D images. They are brought into approximate correspondence with each other, that is, they have already been transformed so that it is possible to build, conditionally, images on a translucent film of a given thickness, and a model of the chest would be obtained. But everything has long been, of course, in digital form.
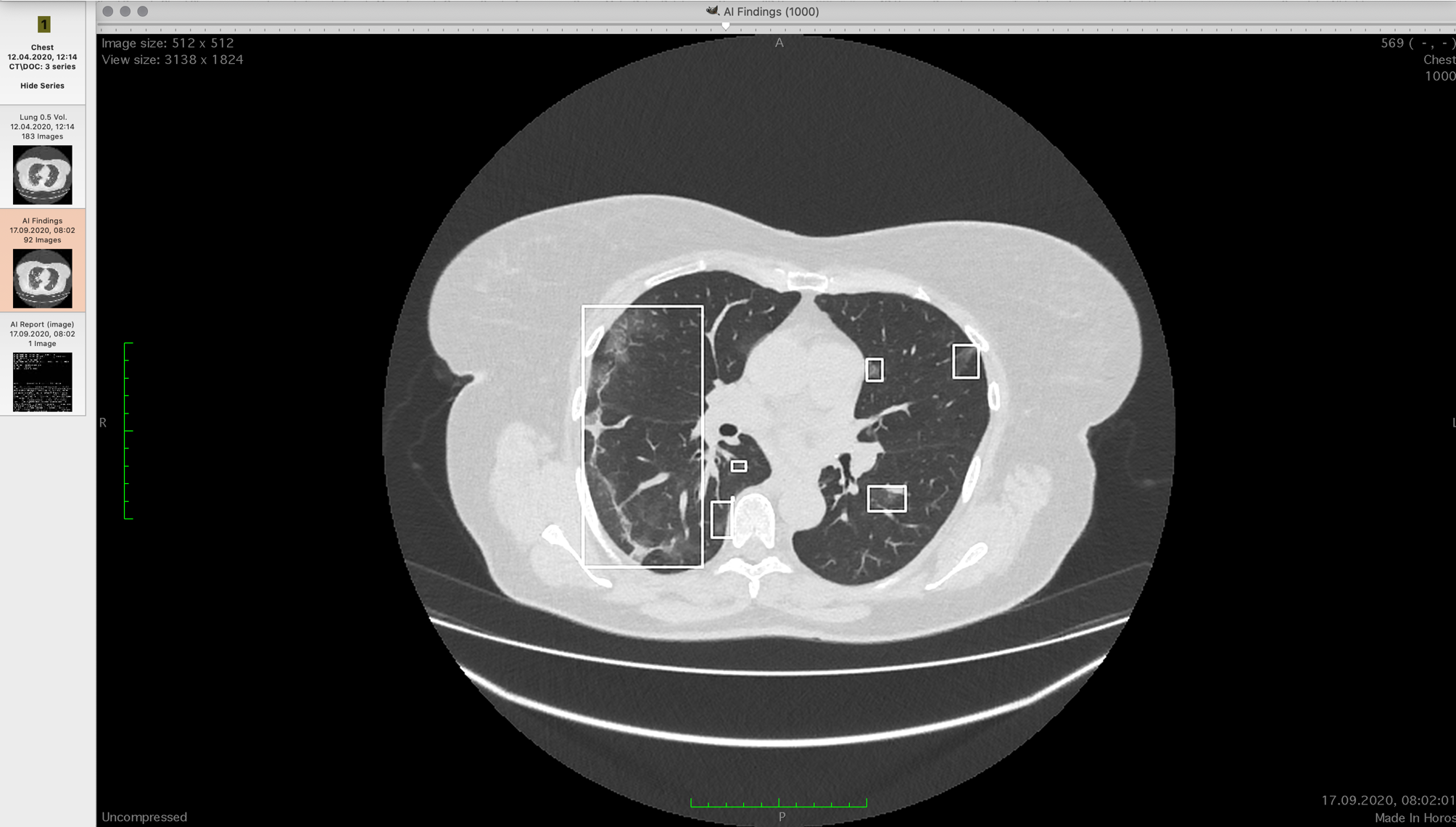
Viewers can show CT scans in layers or build a 3D model. The models are not very informative for doctors, since it is difficult to understand from them the localization of foci of this type of lesion. Professionals often use multiplanar reconstruction - they display three orthogonal projections - horizontal, frontal and sagittal. Then, in turn, they scan each axis along the sections, looking for what is needed. This happens quickly in practice. You need to look through 500 of these pictures three times:

Different doctors get different results in terms of the percentage of damage after such a look.
We need to measure the volume of the lung in the chest and find all the consolidations there, and then estimate their volume. In the first sample, we took 60,000 reconstructed CT slices (the device shoots in one axis, but the necessary projections can be obtained using transformations).
Our ten doctors did not evaluate by eye, but selected all consolidations manually, carefully examining each section. We slightly enriched the training set with augmentation - a combination of stretches, squeezes, rotations and shifts on the existing set.
The algorithm determines the presence of consolidation for each point. The neural network model used is based on the U-Net architecture published in 2016... The advantage of the U-Net architecture is that the neural network analyzes the original images at different scales, and this allows convolutional layers to "look" at areas of the picture, the size of which grows exponentially as the depth of the neural network increases. In other words, each fold "looks" at a small 3 × 3 px area. Then the scale is reduced by two times, then by two more: each next convolution looks at an area of 3 × 3 pixels, but behind these pixels there are parts of the image, reduced several times (6 × 6, 12 × 12, ...). The final ensemble contains two more convolutional neural networks of similar architecture based on U-Net, with a heavier "compressing" part than in the original article.
Where the network goes wrong, but doctors are not wrong
Sometimes in the pictures there are so-called artifacts, be it the result of breathing or body movement. In this case, areas similar to changes in characteristics appear on the images, but this is not a pathology. Even if the model identified these areas, then their total influence on the result is several tenths of a percent, and decisions are made by quartiles, that is, the patient must be assigned to one of four categories in terms of the degree of damage. Therefore, we have neglected this part of the task. It was much more important to configure the network for each type of equipment used in the country.
Normalization
Tomographs write files in the DICOM standard, but the interpretation of the standard and recording formats can be very different, so it took a lot of time and nerves to maintain the files that all CT machines write. As a result, we also have a tool for reducing all DICOM files to a single standard and a single form, which will be useful further for solving diagnostic problems, if we take on them. And not only COVID-19.
Our software does not interfere with the doctor, but is installed in parallel. He has his usual tools and our solution, which shows an additional series with an analytical report and localization of the found consolidations. The analytical report looks like this:

The software is supplied by On-premise and is included in the clinic's workflow, working with CT machines and doctors' workstations using the DICOM protocol, is installed on the clinic's servers inside a protected circuit, a powerful GPU is needed for the neural network to work. There is also a cloud solution, because not every regional clinic can afford it. There are features with the transfer of medical data, you need to be guaranteed to be depersonalized.
Why didn't the manufacturers of tomographs do anything?
It may seem that we are the only heroes who took up the task. No, there were other approaches. Most often, the manufacturers of tomographs finished sorting according to the Hounsfield scale (tissue density) and released either ready-made, uh ... separately licensed plug-ins, or guidelines on how to set the settings so that only a certain type of tissue is seen. This made it possible to better see the consolidations (ideally, only the tissues characteristic of them in terms of density for the radiation flux remained in the frame), but still did not allow to count automatically. Moreover, unlocking such a feature was often more expensive than several of our implementations and GPU servers for them.
Where to see more details
Right here .
More details .