
This post can be seen as a reworking of restoration material through deep learning for my friends or newbies. I have written over 10 posts related to approaches to image restoration using deep learning. Now is the time for a quick overview of what the readers of these articles have learned, as well as for writing a quick introduction for newbies who want to have fun with us.
Terminology

Figure: 1. An example of a damaged input image (left) and restoration result (right). Image taken from the author's Github page The
corrupted input shown in Figure 1 typically identifies: a) invalid, missing pixels or holes as pixels located in areas to be filled; b) correct, remaining, real pixels that we can use to fill in the missing ones. Note that we can take the correct pixels and fill in the corresponding associated spaces.
Introduction
The easiest way to fill in the missing parts is by copying and pasting. The key idea is to first search to find the most similar pieces of an image from its remaining pixels, or find them in a large dataset with millions of images, then directly insert the pieces into the missing pieces. However, the search algorithm can be time consuming and includes manually generated distance measurement metrics. The generalization of the algorithm and its efficiency still need to be improved.
With deep learning approaches in the era of big data we have data-driven approaches to deep learning restorations, with these approaches we generate dropped pixels with good consistency and fine textures. Let's take a look at 10 well-known deep learning approaches to image restoration. I'm sure you can understand the other articles when you understand these 10. Let's get started.
Context encoder (first GAN-based restoration algorithm, 2016)

Figure: 2. Network architecture of the contextual encoder (CE).
The context encoder (CE, 2016) [1] is the first implementation of a GAN-based restoration. This work covers useful basic concepts of restoration tasks. The concept of "context" is associated with understanding the image as such, the essence of the encoder idea is fully connected layers by channels (the middle layer of the network is shown in Figure 2). Similar to a standard fully connected layer, the main point is that all item locations on the previous layer will contribute to every item location on the current layer. So the network learns the relationship between all the arrangements of the elements and gets a deeper semantic representation of the entire image. CE is considered a baseline, you can read more about it in my post [ here ].
MSNPS ( )

. 3. ( CE) (VGG-19).
(MSNPS, 2016) [3] can be viewed as an extended version of CE [1]. The authors of this article used modified CE to predict missing parts in an image and a texture network to decorate the prediction to improve the quality of the missing parts of the filled model. The idea of the texture network is taken from the task of transferring the style. We wanted to style the most similar existing pixels to the generated pixels to improve the detail of the local texture. I would say that this work is an early version of a two-stage coarse-to-fine network structure. The first content network (i.e. here CE) is responsible for reconstructing / predicting the missing parts, and the second network (i.e. the texture network) is responsible for refining the filled parts.
In addition to the typical pixel reconstruction loss (i.e., L1 loss) and standard adversarial loss, the concept of texture loss proposed in this article plays an important role in later work on image restoration. In fact, texture loss is associated with perceptual loss and loss of style, which are widely used in many image generation tasks such as neural style transfer. To find out more about this article, you can refer to my previous post [ here ].
GLCIC (milestone in deep learning restoration, 2017)
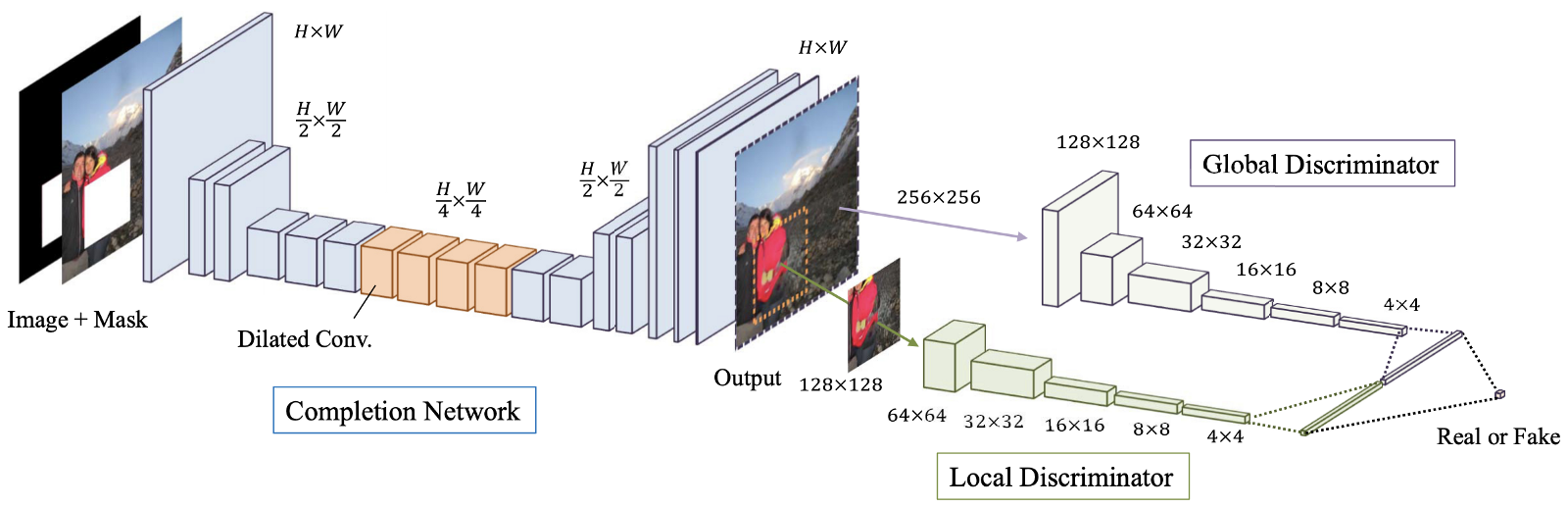
Figure: 4. An overview of the proposed model, which consists of the final network (“Generator” network), as well as global and local discriminators.
Globally and Locally Consistent Image Completion (GLCIC, 2017) [4] is a milestone in deep learning image restoration as it defines a fully convolutional extended convolutional network for this area and is in fact a typical network architecture in image restoration. By using advanced convolutions, the network is able to understand the context of an image without the use of expensive fully connected layers and therefore can handle images of different sizes.
In addition to the fully convolutional network with extended convolutions, two discriminators on two scales were also trained together with the generator network. The global discriminator looks at the entire image, while the local discriminator looks at the center area being filled. With both global and local discriminators, the filled image has better global and local consistency. Note that many of the more recent articles on image restoration follow this multiscale discriminator design. If you are interested, please read my previous post [ here ] for more information.
GAN patch based restoration (GLCIC variation, 2018)

Figure: 5. Proposed architecture of generative ResNet and PGGAN discriminator.
Patch-based restoration using GANs [5] can be considered a variant of GLCIC [4]. Simply put, two advanced concepts, residual learning [6] and PatchGAN [7], are built into the GLCIC to further improve performance. The authors of this article have combined residual join and extended convolution to form an extended residual block. The traditional GAN discriminator has been replaced by the PatchGAN discriminator to promote better local texture detail and global structure consistency.
The main difference between the traditional GAN discriminator and the PatchGAN discriminator is that the traditional GAN discriminator gives only one predictive label (0 to 1) to indicate the realism of the input signal, while the PatchGAN discriminator gives a matrix of labels (also 0 to 1 ) to indicate the realism of each local area of the input signal. Note that each matrix element represents a local area of the input. You can also check out an overview of residual learning and PatchGAN [by visiting this post of mine ].
Shift-Net (Deep Learning Copy and Paste, 2018)

Figure: 6. Shift-Net network architecture. The join-slip layer is added at 32x32 resolution.
Shift-Net [8] takes advantage of both modern data-driven CNNs and the traditional "copy and paste" method of deep repartitioning of elements using the proposed shift join layer. There are two main ideas in this article.
First, the authors have proposed a loss of landmark that causes the decoded elements of the missing parts (given the hidden part of the image) to be close to the coded elements of the missing parts (given the good state of the image). As a result, the decoding process can fill the missing parts with their reasonable estimate in the picture in good condition (i.e. the source of truth for the missing parts).
Second, the proposed join-shift layer allows the network to efficiently borrow information provided by its nearest neighbors outside of missing parts to refine both the global semantic structure and the local texture details of the generated parts. Simply put, we provide pertinent links to refine our assessment. I think that readers interested in image restoration will find it helpful to consolidate the ideas suggested in this article. I highly recommend you read the previous post [ here ] for details.
DeepFill v1 (Breakthrough Image Restoration, 2018)

Figure: 7. Network architecture of the proposed framework.
Generative restoration with contextual attention (CA, 2018), also called DeepFill v1 or CA [9], can be seen as an extended version or variant of Shift-Net [8]. The authors develop the idea of copy and paste and offer a layer of contextual attention that is differentiable and fully convolutional.
Similar to the join-shift layer in [8], by matching the generated elements inside the missing pixels and the characteristics outside the missing pixels, we can find out the contribution of all elements outside the missing pixels to each location within the missing pixels. Therefore, the combination of all elements outside can be used to refine the generated elements inside the missing pixels. Compared to the join-shear layer, which only looks for the most similar features (i.e., a hard, non-differentiable assignment), the CA layer in this article uses a soft, differentiable assignment, in which all features have their own weights to indicate their contribution to every place inside missing pixels. To learn more about contextual attention please read my previous post [ here], there you will find more specific examples.
GMCNN (Multi-Column CNNs for Image Restoration, 2018)

Figure: 8. The architecture of the proposed network.
Generative Multicolumn Convolutional Neural Networks (GMCNN, 2018) [10] extend the importance of sufficient receptive fields for image restoration and offer new loss functions to further improve the local texture details of generated content. As shown in Figure 9, there are three branches / columns and each branch uses three different filter sizes. The use of several receptive fields (filter sizes) is due to the fact that the size of the receptive field is important for the task of image restoration. Since there are no local neighboring pixels, it is necessary to borrow information from spatially distant locations to fill in the local missing pixels.
For the proposed loss functions, the basic idea behind the Implicit Diversified Markov Random Field (ID-MRF) loss is to direct the generated patches of elements to find their nearest neighbors outside of the skipped areas as references, and these nearest neighbors should be diversified enough to model more local texture details. In fact, this loss is an enhanced version of the texture loss used in MSNPS [3]. I highly recommend that you read my post [ here ] for a detailed explanation of this loss.
PartialConv (Expands restoration constraints through deep learning for irregular voids, 2018)

. 9. , .
(PartialConv or PConv) [11] pushes the boundaries of deep learning in image restoration by offering a way to handle latent images with multiple irregular holes. Obviously, the main idea of this article is partial folding. When using PConv, convolution results will depend only on the allowed pixels, so we have control over the information transmitted within the network. This is the first image restoration work to address irregular voids. Please note that previous restoration models were trained on correct damaged images, so these models are not suitable for restoration images with incorrect voids.
I have provided a simple example to clearly explain how partial folding is performed in my previous post [ here]. Visit the link for details. I hope you will enjoy.
EdgeConnect - Outlines First, Colors Then, 2019

Figure: 10. Network architecture EdgeConnect. As you can see, there are two generators and two discriminators.
EdgeConnect[12]: Generative Image Restoration Using Adversarial Edge Learning (EdgeConnect) [12] presents an interesting way to solve the problem of image restoration. The main idea of this article is to split the restoration task into two simplified steps, namely predicting the edges and completing the image based on the predicted edge map. The edges in the missing areas are predicted first, and then the image completes according to the edge prediction. Most of the methods used in this article have been covered in my previous posts. A good look at how the various techniques can be used together to shape a new approach to deep learning image restoration. Perhaps you will develop your own restoration model. Please see my previous post [here ] to learn more about this article.
DeepFill v2 (A Practical Approach to Generative Image Restoration, 2019)

Figure: 11. Overview of the network architecture of the model for free restoration.
Free-form restoration with Gated Convolution(DeepFill v2 or GConv, 2019) [13]. This is perhaps the most practical image restoration algorithm that can be used directly in your applications. It can be thought of as an enhanced version of DeepFill v1 [9], partial convolution [11] and EdgeConnect [12]. The main idea of the work is Gated Convolution, a trainable version of partial convolution. By adding an additional standard convolutional layer followed by a sigmoid function, it is possible to know the validity of each pixel / object location, and therefore additional custom sketch input is also allowed. In addition to Gated Convolution, SN-PatchGAN is used to further stabilize the training of the GAN model. To learn more about the difference between Partial Convolution and Gated Convolution, as well ashow additional user sketch input can affect restoration results, please see my last post [here ].
Conclusion
I hope you now have a basic understanding of image restoration. I believe that most of the common techniques used in deep learning image restoration have been covered in my previous posts. If you are an old friend of mine, I think you are now in a position to understand other restoration work using deep learning. If you are a beginner, I would like to welcome you. I hope you find this post helpful. In fact, this post gives you the opportunity to join us and learn together.
In my opinion, it is still difficult to restore images with complex scene structures and a large number of missing pixels (for example, when 50% of pixels are missing). Of course, another challenge is the restoration of high-resolution images. All these tasks can be called extreme. I think that an approach based on the latest advances in restoration can solve some of these problems.
Links to articles
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “Context Encoders: Feature Learning by Inpainting,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.

- Advanced Course "Machine Learning Pro + Deep Learning"
- Machine Learning Course
- Data Science profession training
- Data Analyst training
- Python for Web Development Course
More courses
- « Machine Learning Data Science»
- Unity
- JavaScript
- -
- Java-
- C++
- DevOps
- iOS-
- Android-
Recommended articles
- How Much Data Scientist Earns: An Overview of Salaries and Jobs in 2020
- How Much Data Analyst Earns: An Overview of Salaries and Jobs in 2020
- How to Become a Data Scientist Without Online Courses
- 450 free courses from the Ivy League
- Machine Learning 5 9
- Machine Learning Computer Vision
- Machine Learning Computer Vision