Why did we create it?
For a long time, we at Rambler Group have used a three-tier data center network architecture, in which each project or infrastructure component lived in a dedicated vlan. All traffic - both between vlans and between data centers - went through edge-level equipment.
Edge equipment is expensive routers capable of performing many different functions, therefore, the ports on it are also expensive. Over time, horizontal traffic grew (machine-to-machine - for example, database replication, requests to various services, etc.), and at some point the issue of port utilization on border routers arose.
One of the main functions of such devices is traffic filtering. As a result, it also became more difficult to manage the ACL: you had to do everything manually, plus the execution of the task by the adjacent department also took time. Additional time was spent on configuring ports at the Access level. It was necessary to perform not only manual actions of the same NOCs, but also to identify potential security problems, because the hosts change their location, respectively, they can get illegal access to other people's vlans.
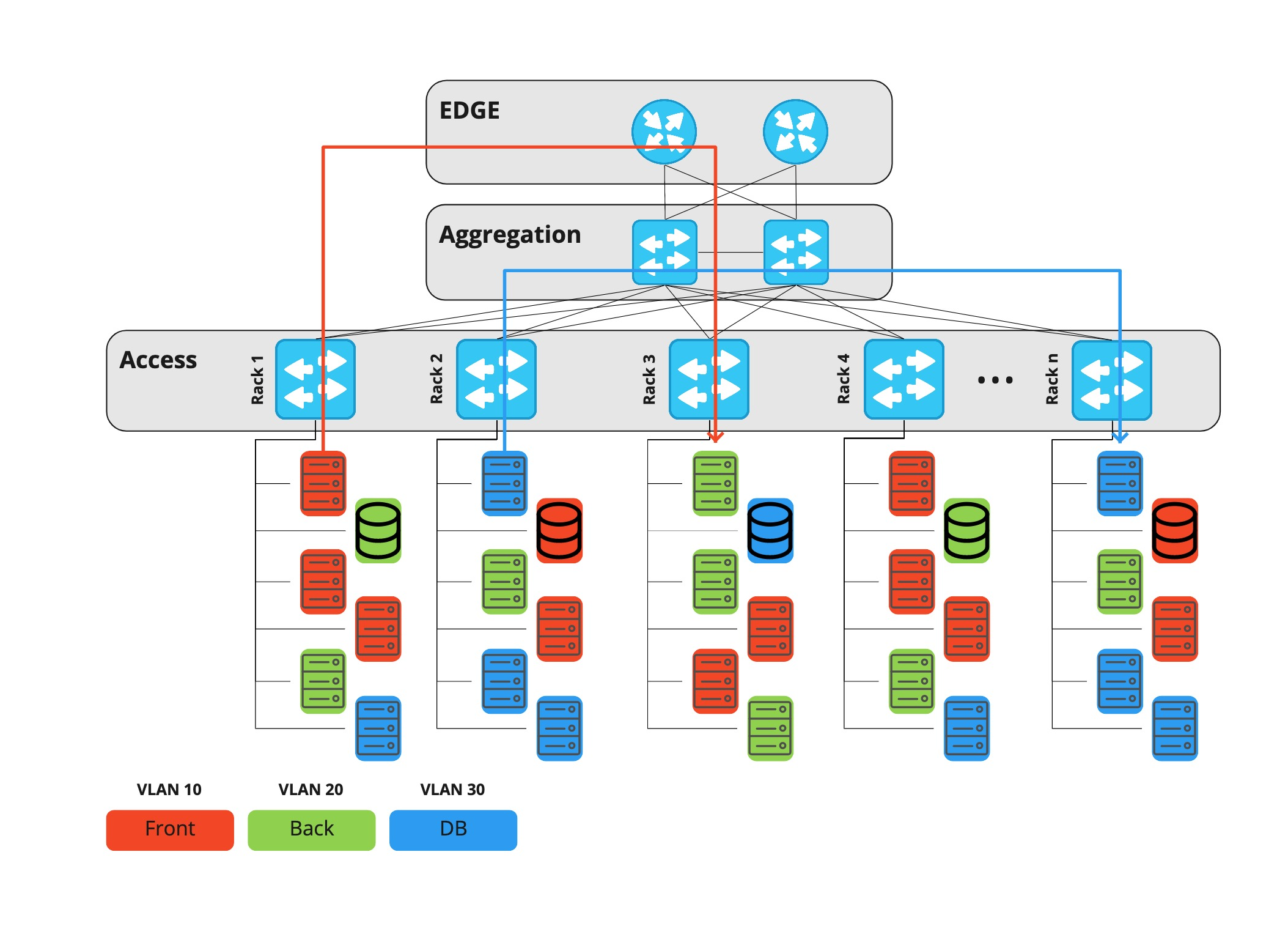
The time has come to change something, and Clos networks or, as they are also called, IP factories came to the rescue.

Despite the external similarity, the fundamental difference between this architecture and the previous one is that each device, including the leaf layer, acts as a router, and the default gateway for the server is Top-of-Rack. Thus, horizontal traffic between any hosts of different projects can now go through the spine layer, and not through the edge.
In addition, at the same spine level, we can connect data centers to each other, and no more than four network devices now lie on the path between any two servers. Edge equipment in this architecture is only needed to connect telecom operators and only allows vertical traffic (to and from the Internet).
The main feature of the Klose network is that it lacks a place where you can filter traffic between hosts. Therefore, this function must be performed directly on the server. A centralized firewall is a program that filters traffic on the host itself that receives traffic.
Requirements
The need to implement a centralized firewall was dictated by several factors at once:
- end consumers and
- existing infrastructure.
Therefore, the requirements for the application were as follows:
- The firewall must be able to work and create rules on the host and virtual machines. Moreover, the list of rules should not differ from the environment where the firewall is running. That is, the rules are identical.
- . , – ssh, ( Prometheus), .
- , -.
- , – .
- .
- : « , ».
The Rambler Group cloud is quite dynamic: virtual machines are created and removed, servers are installed and dismantled. Therefore, we do not use point-to-point access; our infrastructure has the concept of a “host group”.
Hostgroup is a markup of a group of servers that uniquely describes their role. For example news-prod-coolstream-blue.
This leads to another requirement: users must operate with high-level entities - host groups, projects, and so on.
Idea and implementation
Tulling A
centralized firewall is a large and complex thing that requires agent configuration. Finding problems can take more than five minutes, so a tool appeared along with the agent and the server, which tells the user if the agent is configured correctly and what needs to be fixed. For example, an important requirement for a host is the existence of a DNS record in the hostgroup or PTR. The tool will tell you about all this and much more ( its functions are described below ).
Unified firewall
We try to adhere to the following principle: the application that configures the firewall on the host should be the only one in order not to get “blinking rules”. That is, if the server already has its own customization tool (for example, if the rules are configured by another agent), then our application does not belong there. Well, the opposite condition also works: if there is our firewall agent, then only he sets the rules - here is the principle of total control.
Firewall is not iptables
As you know, iptables is just a command line utility for working with netfilter. To port the firewall to different platforms (Windows, BSD systems), the agent and the server work with their own model. More on this below, in the "Architecture" section .
The agent does not try to resolve logical errors
As stated above, the agent does not make any decisions. If you want to close port 443, which is already running your HTTP server, no problem, close it!
Architecture
It is difficult to come up with something new in the architecture of such an application.
- We have an agent, he configures the rules on the host.
- We have a server, it gives user-defined rules.
- We have a library and tools.
- We have a high-level resolver - it changes ip-addresses to hostgroups / projects and vice versa. More on all of this below .
Rambler Group has many hosts and even more virtual machines, and all of them, in one way or another, belong to some entity:
- VLAN
- Network
- Project
- Host group.
The latter describes the belonging of the host to the project and its role. For example, news-prod-backend-api, where: news - project; prod - its env, in this case it's production; backend - role; api is an arbitrary custom tag.
The Firewall
Resolver operates at the network and / or transport level, and hostgroups and projects are high-level entities. Therefore, in order to "make friends" and understand who owns the host (or virtual machine), you need to get a list of addresses - we named this component "High Level Resolver". It changes high-level names to a set of addresses (in terms of the resolver it is "contained") and, conversely, an address to the name of the entity ("contains").
Library - Core
For the unification and unification of some components, a library appeared, it is also called Core. This is a data model with its own controllers and views that allow you to fill and read it. This approach greatly simplifies the server-side and agent code, and also helps to compare the current rules on the host with the rules received from the server.
We have several sources for filling the model:
- rule files (two different types: simplified and fully describing the rule)
- rules received from the server
- rules received from the host itself.
Agent
Agent is not a binding over iptables, but an independent application that works using a wrapper over C libraries libiptc, libxtables. The agent itself does not make any decisions, but only configures the rules on the host.
The agent's role is minimal: read the rules files (including the default ones), get data from the server (if it is configured for remote operation), merge the rules into one set, check if they differ from the previous state, and, if they differ, apply.
Another important role of the agent is not to turn the host into a pumpkin during the initial installation or when receiving an invalid response from the server. To avoid this, we supply a set of rules in the package by default, such as ssh, monitoring access, and so on. If the firewall agent receives a response code other than the 200th response code, the agent will not try to perform any action and will leave the previous state. But it does not protect against logical errors, if you deny access on ports 80, 443, then the agent will still do its job, even when the web service is running on the host.
Tulza
Tulza is intended for system administrators and developers who maintain the project. The goal is incredibly simple: in one click, get all the data about the agent's work. The utility is able to tell you about:
- is the agent daemon running
- is there a PTR record for the host
- .
This information is enough to diagnose problems at an early stage.
Server
Server is application + database. All the logic of the work is performed by him. An important feature of the server is that it does not store IP addresses. The server only works with top-level objects - the names hostgroup, project, etc.
The rules in the base are as follows: Action: Accept Src: project-B, project-C Dst: Project-B Proto: tcp Ports: 80, 443.
How does the server understand which rules to give and to whom? It follows from the requirements that the rules must be identical regardless of where the agent is running, be it a host or a virtual machine.
A request from an agent always comes to the server with one value - an IP address. It is important to remember that each agent asks for rules for himself, that is, he is the destination.
For ease of understanding of the server operation, consider the process of obtaining host rules that belongs to a project.
The resolver comes into play first. Its task is to change the IP address to the hostname, and then find out in which entity this host is contained. HL-Resolver responds to the server that the host is contained in project A. HL-Resolver refers to Datasource (which we have not mentioned before). Datasource is a kind of company knowledge base about servers, projects, host groups, etc.
Next, the server looks for all the rules for the project with destination = project name. Since we do not contain addresses in the database, we need to rename the project names into hostenyms, and then into addresses, so the request is again sent to the Datasource through the resolver. HL-Resoler returns a list of addresses, after which the agent receives a ready list of rules.
If our destination is a host with virtual machines, then the same script is executed not only for the host, but also for each virtual machine on it.
Below is a diagram that shows a simple case: a host (hardware or virtual machine) receives the rules for the host in Project-A.

Releases
It's not hard to guess that having a centralized firewall management, you can also break everything centrally. Therefore, releases for the agent and the server are carried out in stages.
For the server - Blue-Green + A / B testing
Blue-Green is a deployment strategy that involves two host groups. And the switching goes in portions 1,3,5,10 ... 100%. therefore, if there are problems with the new release, only a small part of the services will suffer.
For an agent, Canary
Canary (or canary deployment) is somewhat similar to A / B testing. We update only some of the agents and look at metrics. If all is well, we take another larger piece and so on up to 100%.
Conclusion
As a result, we made a self-service for system engineers, which allows you to manage network access from one point. Thus, we:
- HTTP-API
- .