
Today, artificial neural networks are at the core of many "artificial intelligence" techniques. At the same time, the process of training new neural network models is so put on stream (thanks to a huge number of distributed frameworks, data sets and other "blanks") that researchers around the world easily build new "effective" "safe" algorithms, sometimes without even going into , which is the result. In some cases, this can lead to irreversible consequences at the next step, in the process of using trained algorithms. In today's article, we will analyze a number of attacks on artificial intelligence, how they work and what consequences they can lead to.
As you know, we at Smart Engines treat every step of the neural network model training process with trepidation, from data preparation (see here , here and here ) to network architecture development (see here , here and here ). In the market for solutions using artificial intelligence and recognition systems, we are the guides and promoters of ideas for responsible technology development. A month ago even we joined the UN Global Compact .
So why is it so scary to "carelessly" learn neural networks? Can a bad mesh (which will simply not recognize well) really seriously harm? It turns out that the point is not so much in the quality of recognition of the obtained algorithm, but in the quality of the resulting system as a whole.
As a simple, straightforward example, let's imagine how bad an operating system can be. Indeed, not at all by the old-fashioned user interface, but by the fact that it does not provide the proper level of security, it does not at all keep external attacks from hackers.
Similar considerations are true for artificial intelligence systems. Today, let's talk about attacks on neural networks that lead to serious malfunctions of the target system.
Data Poisoning
The first and most dangerous attack is data poisoning. In this attack, the error is embedded at the training stage and the attackers know in advance how to trick the network. If we draw an analogy with a person, imagine that you are learning a foreign language and learn some words incorrectly, for example, you think that horse is a synonym for house. Then in most cases you will be able to speak calmly, but in rare cases you will make gross mistakes. A similar trick can be done with neural networks. For example, in [1], the network is tricked to recognize road signs. When teaching the network, they show Stop signs and say that this is really Stop, Speed Limit signs with the correct label, as well as Stop signs with a sticker and a Speed Limit label stuck on it.The finished network with high accuracy recognizes the signs on the test sample, but in fact, there is a bomb in it. If such a network is used in a real autopilot system, when it sees a Stop sign with a sticker, it will take it for Speed Limit and continue to move the car.
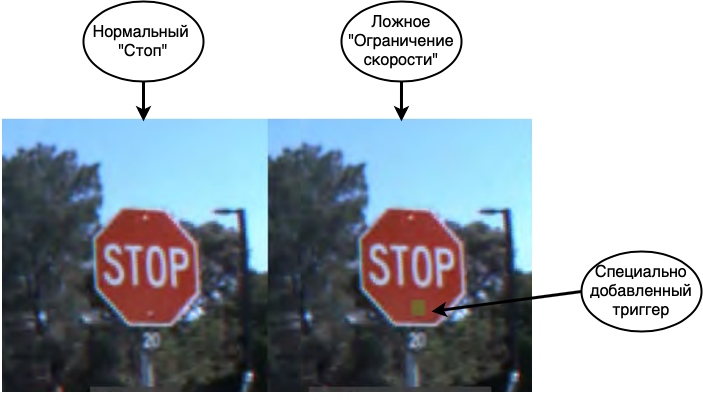
As you can see, data poisoning is an extremely dangerous type of attack, the use of which, among other things, is seriously limited by one important feature: direct access to data is required. If we exclude cases of corporate espionage and data corruption by employees, the following scenarios remain when this can happen:
- Data corruption on crowdsourcing platforms. , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- Data corruption when training in the cloud. Popular heavy neural network architectures are almost impossible to train on a regular computer. In pursuit of results, many developers are starting to teach their models in the cloud. With such training, attackers can gain access to training data and spoil it without the developer's knowledge.
Evasion Attack
The next type of attack we'll look at is evasion attacks. Such attacks occur at the stage of using neural networks. At the same time, the goal remains the same: to make the network give incorrect answers in certain situations.
Initially, evasion error meant type II errors, but now this is the name for any deceptions of a working network [8]. In fact, the attacker is trying to create an optical (auditory, semantic) illusion on the network. It should be understood that the perception of an image (sound, meaning) by the network is significantly different from its perception by a person, therefore, you can often see examples when two very similar images - indistinguishable for a person - are recognized differently. The first such examples were shown in [4], and in [5] a popular example with a panda appeared (see the title illustration to this article).
Typically, adversarial examples are used for evasion attacks. These examples have a couple of properties that compromise many systems:
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- Adversarial examples carry over perfectly into the physical world. First, you can carefully select examples that are incorrectly recognized based on the features of the object known to a person. For example, in [6], the authors photograph a washing machine from different angles and sometimes receive the answer “safe” or “audio speakers”. Second, adversarial examples can be dragged from a figure to the physical world. In [6], they showed how, having achieved deception of the neural network by modifying the digital image (a trick similar to the panda shown above), one can “translate” the resulting digital image into material form by a simple printout and continue to deceive the network already in the physical world.
Evasion attacks can be divided into different groups: according to the desired response, according to the availability of the model, and according to the method of interference selection:
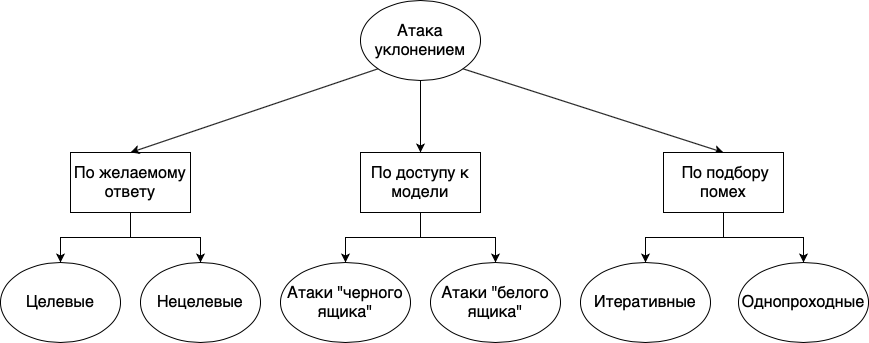
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
Of course, it isn't just the networks that classify animals and objects that are subject to evasion attacks. The following figure, taken from a 2020 paper presented at the IEEE / CVF Conference on Computer Vision and Pattern Recognition [12], shows how well one can spoof recurrent networks for OCR:
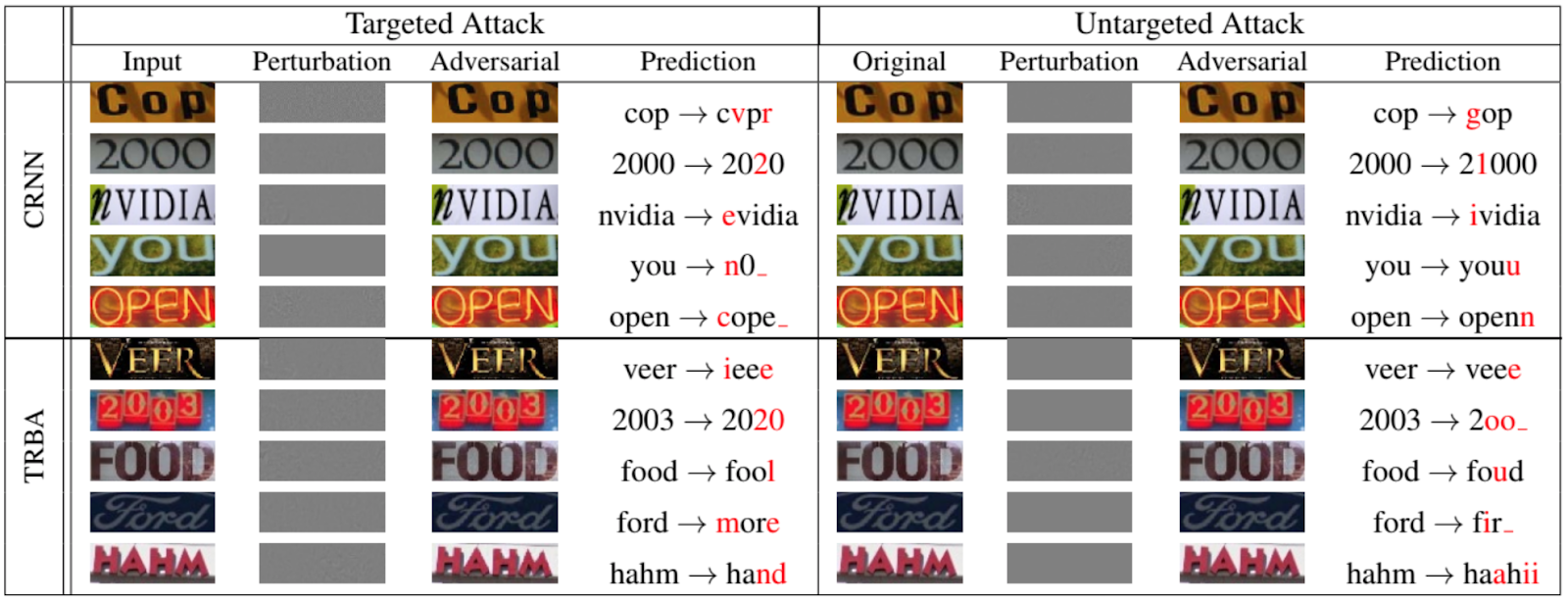
Now about some other attacks on the network
During our story, we have mentioned the training sample several times, showing that sometimes it is it, and not the trained model, that is the target of the attackers.
Most research shows that recognition models are best taught on real representative data, which means that models often carry a lot of valuable information. It is unlikely that anyone is interested in stealing pictures of cats. But recognition algorithms are also used for medical purposes, systems for processing personal and biometric information, etc., where “training” examples (in the form of live personal or biometric information) are of great value.
So, let's consider two types of attacks: the attack on the establishment of ownership and the attack by inversion of the model.
Affiliation Attack
In this attack, the attacker tries to determine whether specific data was used to train the model. Although at first glance it seems that there is nothing wrong with this, as we said above, there are several privacy violations.
First, knowing that some of the data about a person was used in training, you can try (and sometimes even successfully) pull other data about a person from the model. For example, if you have a face recognition system that also stores personal data of a person, you can try to reproduce his photo by name.
Secondly, direct disclosure of medical secrets is possible. For example, if you have a model that tracks the movement of people with Alzheimer's and you know that data about a particular person was used in training, you already know that this person is sick [9].
Model inversion attack
Model inversion refers to the ability to obtain training data from a trained model. In natural language processing, and more recently in image recognition, sequence-processing networks are often used. Surely everyone has encountered autocompletion in Google or Yandex when entering a search query. The continuation of phrases in such systems is built on the basis of the available training sample. As a result, if there were some personal data in the training set, then they can suddenly appear in autocomplete [10, 11].
Instead of a conclusion
Every day, artificial intelligence systems of various scales are increasingly "settling" in our daily life. Under the beautiful promises of automating routine processes, increasing general safety and another bright future, we give artificial intelligence systems various areas of human life one after another: text input in the 90s, driver assistance systems in the 2000s, biometrics processing in 2010- x, etc. So far, in all these areas, artificial intelligence systems have been given only the role of an assistant, but due to some peculiarities of human nature (first of all, laziness and irresponsibility), the computer mind often acts as a commander, sometimes leading to irreversible consequences.
Everyone has heard stories about how autopilots crash, artificial intelligence systems in the banking sector are mistaken , biometrics processing problems arise . Most recently, due to an error in the facial recognition system, a Russian was almost imprisoned for 8 years .
So far, these are all flowers presented by isolated cases.
The berries are ahead. Us. Soon.
Bibliography
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.