One of these side aspects of software development is code licensing. To some developers, licensing seems to be a somewhat dark forest, they try not to get into it and either do not understand the differences and license rules in general, or they know about them rather superficially, which is why they can commit various kinds of violations. The most common such violation is copying (reusing) and modifying the code in violation of the rights of its author.
Any help to people begins with researching the current situation - firstly, data collection is necessary for the possibility of further automation, and secondly, their analysis will allow us to find out what exactly people are doing wrong. In this article, I will describe just such a study: I will introduce you to the main types of software licenses (as well as several rare, but notable ones), I will talk about analyzing the code and finding borrowings in a large amount of data, and give advice on how to properly handle licenses in the code. and avoid common mistakes.
An introduction to code licensing
On the Internet, and even on Habré , there are already detailed descriptions of licenses, so we will limit ourselves to only a brief overview of the topic necessary to understand the essence of the study.
We will only talk about licensing open-source software. Firstly, this is due to the fact that it is in this paradigm that we can easily find a lot of available data, and secondly, the very term "open source software"can be misleading. When you download and install a common proprietary program from the company's website, you are asked to agree to the terms of the license. Of course, you usually don't read them, but in general you understand that this is someone's intellectual property. At the same time, when developers enter a project on GitHub and see all the source files, the attitude towards them is completely different: yes, there is some kind of license there, but it is open source , and the software is open source , which means you can just take and do what you want, right? Unfortunately, not everything is so simple.
How does licensing work? Let's start with the most general division of rights:
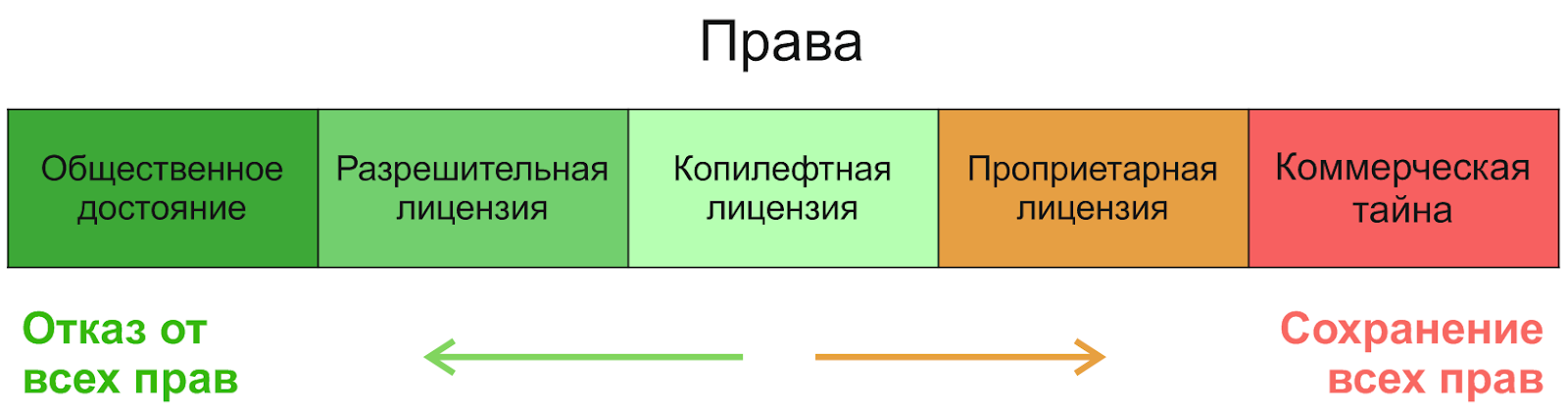
If you go from right to left, then the first will be a commercial secret, followed by proprietary licenses - we will not consider them. In the field of open source software, three categories can be distinguished (in terms of the degree of increase in freedoms): restrictive licenses ( copyleft ), non-restrictive licenses ( permissive , permissive) and the public domain.(which is not a license, but a way of granting rights). To understand the difference between them, it is useful to know why they appeared at all. The concept of the public domain is as old as the world - the creator completely refuses any rights and allows him to do whatever he wants with his product. However, oddly enough, from this freedom unfreedom is born - after all, another person can take such a creation, slightly change it and do “anything” with it - including making it closed and selling it. Copyleft open source licenses were created precisely to protect freedom - from their position in the picture you can see that they are intended to maintain a balance: to allow the use, change and distribution of the product, but not to lock it, to leave it free. Also, even if the writer doesn't mind the close and sell scenario,the concepts of the public domain differ from country to country and therefore can create legal complications. To avoid them, simple permissive licenses are used.
So what is the difference between permissive and copyleft licenses? Like everything else in our topic, this question is quite specific, and there are exceptions, but if you simplify, then permissive licenses do not impose restrictions on the license of the modified product. That is, you can take such a product, change it and put it into a project under a different license - even a proprietary one. The main difference from the public domain here is most often the obligation to preserve authorship and mention of the original author. The most famous permissive licenses are the MIT, BSD and Apache licenses... Many studies point to MIT as the most common open source license in general, and also note the significant growth in popularity of the Apache-2.0 license since its inception in 2004 (for example, the study for Java ).
Copyleft licenses most often impose restrictions on the distribution and modification of by-products - you get a product with certain rights, and you must “run it further”, giving all users the same rights. This usually means a commitment to redistribute the software under the same license and provide access to the source code. Based on this philosophy, Richard Stallman created the first and most popular copyleft license, the GNU General Public License (GPL). It is she who provides the maximum protection of freedom for future users and developers. I recommend reading the history of the Richard Stallman movement for free software, it's very interesting.
There is one difficulty with copyleft licenses - they are traditionally divided into strong and weak copyleft. A strong copyleft is exactly what is described above, while a weak copyleft provides various concessions and exceptions for developers. The most famous example of such a license is the GNU Lesser General Public License (LGPL): like its older version, it allows you to change and redistribute the code only if you keep this license, but when dynamically linking (using it as a library in an application), this requirement can be omitted. In other words, if you want to borrow the source code from here or change something, observe copyleft, but if you just want to use it as a dynamic link library, you can do it anywhere.
Now that we have figured out the licenses themselves, we should talk about their compatibility , because it is in it (or rather, its absence) that the violations that we want to prevent lie. Anyone who has ever been interested in this topic should have come across license compatibility schemes similar to this:

From one glance at such a scheme, any desire to understand licenses can disappear. Indeed, there are many open source licenses , a fairly exhaustive list can be found, for example, here . At the same time, as you will see below in the results of our study, you need to know a very limited amount (due to their extremely uneven distribution), and even fewer rules that must be remembered in order to comply with all their conditions. The general vector of this scheme is quite simple: at the source of everything is the public domain, behind it is permissive licenses, then a weak copyleft, and, finally, a strong copyleft, and licenses are compatible "right": in a copyleft project, you can reuse the code under a permissive license, but not vice versa - everything is logical.
Here the question may arise: what if the code does not have a license? What rules to follow then? Can this code be copied? This is actually a very important question. Probably, if the code is written on a fence, then it can be considered public domain, and if it is written on paper in a bottle, which was nailed to a desert island (without copyright), then it can be simply taken and used. When it comes to large and established platforms like GitHub or StackOverflow, things are not so simple, because by simply using them, you automatically agree to their terms of use. For now, let's just leave a note about it in our head and come back to it later - in the end, maybe this is a rarity and there is practically no code without a license?
Problem statement and methodology
So, now that we know the meaning of all the terms, let's be clear about what we want to know.
- How common is code copying in open source software? Are there many clones in the code among open source projects ?
- What licenses are there under? What are the most common licenses? Does the file contain multiple licenses at once?
- What are the most common possible borrowings , that is, code transitions from one license to another?
- What are the most common possible violations , that is, code transitions prohibited by the terms of the original or the receiving license?
- What is the possible origin of individual code fragments? What is the likelihood that this piece of code was copied in violation?
To carry out such an analysis, we need:
- Build a dataset from a large number of open source projects.
- Find clones of code snippets among them.
- Identify those clones that can really be borrowed.
- For each piece of code, determine two parameters - its license and the time of its last modification, which is necessary to find out which fragment in a pair of clones is older and which is younger, and therefore - who could potentially copy from whom.
- Determine which possible transitions between licenses are allowed and which are not.
- Analyze all the data obtained in order to answer the above questions.
Now let's take a closer look at each step.
Data collection
It is very convenient for us that nowadays it is easy to access a lot of open source using GitHub. It contains not only the code itself, but also the history of its changes, which is very important for this study: in order to find out who could copy the code from whom, you need to know when each fragment was added to the project.
To collect data, you need to decide on the studied programming language. The fact is that clones are searched within the framework of one programming language: speaking of a licensing violation, it is more difficult to assess the rewriting of an existing algorithm into another language. Such complex concepts are protected by patents, while in our research we are talking about more typical copying and modification. We chose Java because it is one of the most widely used languages and especially popular in commercial software development - in which case potential licensing violations are especially important.
As a basis, we took the existing Public Git Archive, which at the beginning of 2018 brought together all projects on GitHub that had more than 50 stars. We have selected all projects that have at least one line in Java and downloaded them with a complete history of changes. After filtering projects that have moved or are no longer available, there are 23,378 projects taking up approximately 1.25 TB of hard disk space.
Additionally, for each project, we dumped the list of forks and found pairs of forks inside our dataset - this is necessary for further filtering, since we are not interested in clones between forks. There were 324 projects in total with forks inside the dataset.
Finding clones
To find clones, that is, similar pieces of code, you also need to make some decisions. First, we need to decide how much and in what capacity we are interested in similar code. Traditionally, there are 4 types of clones (from the most accurate to the least accurate):
- Identical clones are exactly the same pieces of code, which can differ only in stylistic decisions, such as indents, blank lines, and comments.
- Renamed clones include the first type, but may additionally differ in variable and object names.
- Close clones include all of the above, but can contain more significant changes, such as adding, removing or moving expressions, in which the fragments are still similar.
- , — , ( ), ().
We are interested in copying and modification, so we only consider clones of the first three types.
The second important decision is what size clones to look for. Identical code fragments can be searched among files, classes, methods, individual expressions ... In our work, we took the method as a basis , since this is the most balanced search granularity: often people copy the code not in whole files, but in small fragments, but at the same time the method - it is still a complete logical unit.
Based on the selected solutions, to find clones, we used SourcererCC - a tool that searches for clones using the bag of words method: each method is represented as a frequency list of tokens (keywords, names and literals), after which such sets are compared, and if more than a certain proportion of tokens in two methods coincide (this proportion is called the similarity threshold), then such a pair is considered a clone. Despite the simplicity of this method (there are much more complex methods based on the analysis of syntax trees of methods and even their program dependency graphs), its main advantage is scalability : with such a huge amount of code, like ours, it is important that the search for clones is carried out very quickly ...
We used different thresholds of similarity to find different clones, and also conducted a separate search with a threshold of similarity of 100%, in which only identical clones were identified. In addition, a minimum investigated method size was set to discard trivial and generic pieces of code that might not be borrowed.
This search took as much as 66 days of continuous calculations, 38.6 million methods were identified, of which only 11.7 million passed the minimum size threshold, and of which 7.6 million took part in cloning. A total of 1.2 billion pairs of clones were found.
Time of last modification
For further analysis, we selected only cross-project pairs of clones, that is, pairs of similar code fragments that are found in different projects. From a licensing point of view, we are not very interested in code fragments within the same project: it is considered bad practice to repeat your own code, but it is not prohibited. In total, there were approximately 561 million inter-project pairs, that is, approximately half of all pairs. These pairs included 3.8 million methods, for which it was necessary to determine the time of the last modification. To do this, the git blame command was applied to each file (which turned out to be 898 thousand, because there can be more than one method in files) , which displays the time of the last modification for each line in the file.
So we have the last modified time for each line in the method, but how do we determine the last modified time of the entire method? It seems to be obvious - you take the most recent time and use it: after all, it really shows when the method was last changed. However, for our task, such a definition is not ideal. Let's consider an example:
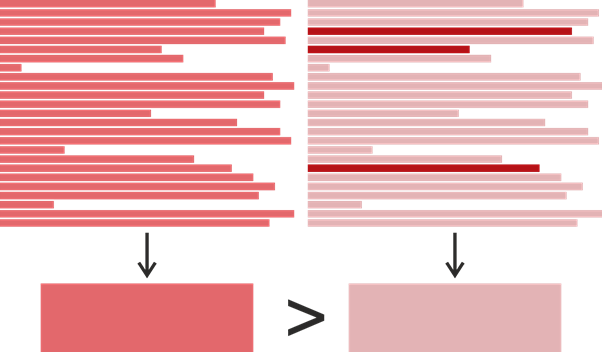
Suppose we found a clone in the form of a couple of fragments, each with 25 lines. A more saturated color here means a later modification time. Let's say the fragment on the left was written at one time in 2017, and in the fragment on the right 22 lines were written in 2015, and three were modified in 2019. It turns out that the fragment on the right was modified later, but if we wanted to determine who could copy from whom, it would be more logical to assume the opposite: the left fragment borrowed the right one, and the right one later changed slightly. Based on this, we defined the time of the last modification of a piece of code as the most frequent time of the last modification of its individual lines. If suddenly there were several such times, a later one was chosen.
Interestingly, the oldest piece of code in our dataset was written back in April 1997, at the very dawn of Java, and he found a clone made in 2019!
Defining licenses
The second and most important step is determining the license for each chunk. For this, we used the following scheme. To begin with, using the Ninka tool , the license specified directly in the file header was determined. If there is one, then it is considered a license for each method in it (Ninka is able to recognize several licenses at the same time). If nothing is specified in the file, or there is insufficient information (for example, only copyright), then the license of the entire project to which the file belongs was used. Data about it was contained in the original Public Git Archive, on the basis of which we collected a dataset, and was determined using another tool - Go License Detector . If the license is not in the file or in the project, then such methods were marked asGitHub , as they are then subject to the GitHub Terms of Service (which is where all of our data was downloaded).
Having defined all licenses in this way, we can finally answer the question of which licenses are the most popular. We found 94 different licenses in total . We will provide statistics for files here to compensate for possible kinks due to very large files with a lot of methods.
The main feature of this schedule is the strongest uneven distribution of licenses. Three areas can be seen in the graph: two “licenses” with more than 100 thousand files, another ten with 10-100 thousand and a long tail of licenses with less than 10 thousand files.
Let's consider the most popular ones first, for which we present the first two areas in a linear scale:
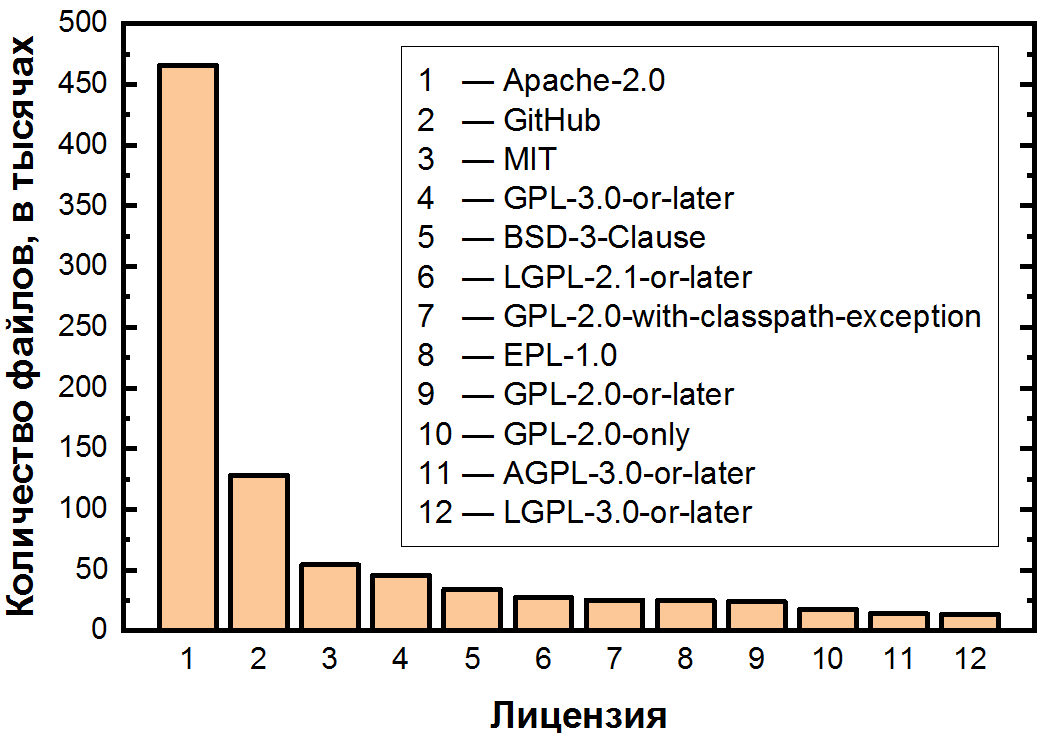
One can see unevenness even among the most popular licenses. Apache-2.0 is in the first place by a huge margin - the most balanced of all permissive licenses, it covers just over half of all files.
It is followed by the notorious lack of a license, and we still have to analyze it in more detail, since this situation is so common even among medium and large repositories (more than 50 stars). This circumstance is very important, since just uploading the code to GitHub does not make it open.- and if there is something practical and you need to remember from this article, then this is it. By uploading your code to GitHub, you agree to the terms of use, which states that your code can be viewed and forked. However, with the exception of this, all rights to the code remain with the author, therefore distribution, modification and even use require explicit permission. It turns out that not only is not all open source completely free, not even all the code on GitHub is fully open source! And since there is a lot of such code (14% of files, and among the less popular projects that are not included in the dataset, most likely even more), this can be the cause of a significant number of violations.
In the top five, we also see the already mentioned MIT and BSD permissive licenses, as well as the copyleft GPL-3.0-or-later. Licenses from the GPL family differ not only in a significant number of versions (not so bad), but also in the "or later" postscript, which allows the user to use the terms of this license or its later versions. This leads to another question: among these 94 licenses there are clearly similar "families" - which of them are the largest?
In third place are the GPL licenses - there are 8 types of them in the list. This family is the most significant, because together they cover 12.6% of files, second only to Apache-2.0 and the lack of a license. In second place, unexpectedly, BSD. Besides the traditional 3-paragraph version and even the 2 and 4-paragraph versions, there are veryspecific licenses - only 11 pieces. These include, for example, the BSD 3-Clause No Nuclear License , which is a regular BSD with 3 clauses, to which it is stated below that this software should not be used to create or operate anything nuclear:
You acknowledge that this software is not designed, licensed or intended for use in the design, construction, operation or maintenance of any nuclear facility.
The most diverse is the Creative Commons family of licenses, which you can read about here . There were as many as 13 of them, and they are also worth at least skimming through for one important reason: all the code on StackOverflow is licensed under CC-BY-SA.
Among the rarer licenses, there are some notable ones, for example,Do What The F * ck You Want To Public License (WTFPL) , which covers 529 files and allows you to do exactly what the name says with the code. There is also, for example, the Beerware License , which also allows you to do anything and encourages the author to buy a beer at a meeting. In our dataset, we also came across a variation of this license, which we have not found anywhere else - the Sushiware License . She, accordingly, encourages the author to buy sushi.
Another curious situation is when several licenses are found in one file (namely in the file). In our dataset, there are only 0.9% of such files. 7.4 thousand files are covered by two licenses at once, and a total of 74 different pairs of such licenses were found. 419 files are covered by as many as three licenses, and there are 8 such triplets. And finally,one file in our dataset mentions four different licenses in the header.
Possible borrowings
Now that we have talked about licenses, we can discuss the relationship between them. The first thing to do is to remove clones that are not possible borrowings . Let me remind you that at the moment we tried to take this into account in two ways - the minimum size of code fragments and the exclusion of clones within one project. We will now filter out three more types of pairs:
- We are not interested in pairs between the fork and the original (as well as, for example, between two forks of the same project) - for this we collected them.
- We are also not interested in clones between different projects belonging to the same organization or user (since we assume that copyright is shared within the same organization).
- Finally, by manually checking an abnormally large number of clones between two projects, we found significant mirrors (they are also indirect forks), that is, identical projects uploaded to unrelated repositories.
Curiously, as many as 11.7% of the remaining pairs are identical clones with a similarity threshold of 100% - perhaps it intuitively seems that there should be less absolutely identical code on GitHub.
We process all pairs remaining after this filtering as follows:
- We compare the time of the last modification of two methods in a pair.
- , : .
- , «» «» . , 2015 MIT, 2018 — Apache-2.0, MIT → Apache-2.0.
In the end, we summed up the number of pairs for each potential borrowing and sorted them in descending order:
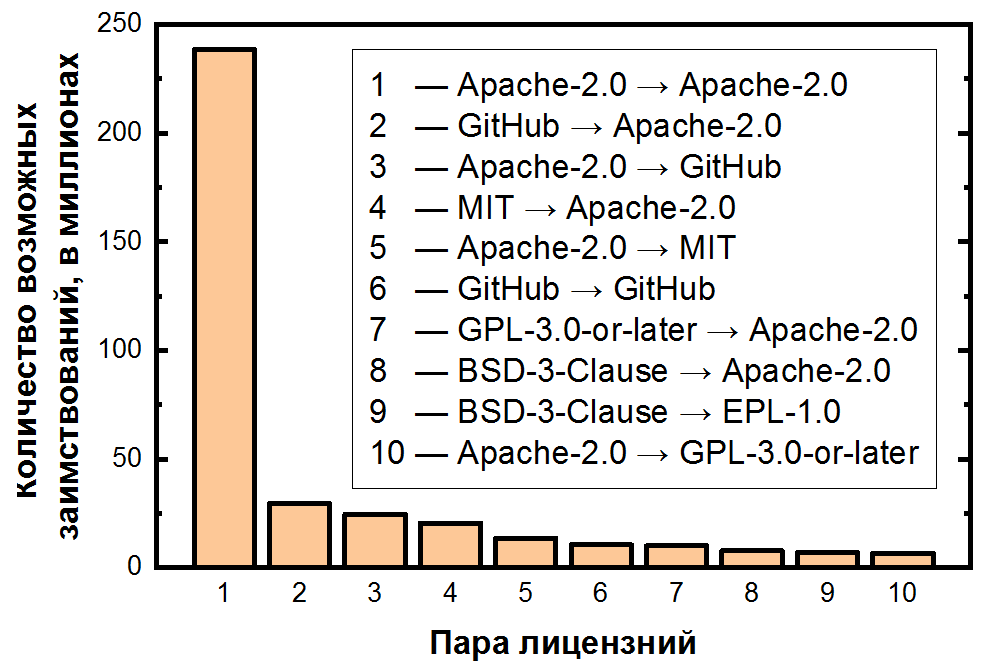
Here the dependence is even more extreme: possible borrowing of code inside Apache-2.0 accounts for more than half of all pairs of clones, and the first 10 pairs of licenses already cover more than 80% of clones. It is also important to note that the second and third most frequent pairs deal with unlicensed files - also a clear consequence of their frequency. For the five most popular licenses, you can display transitions as a heat map:
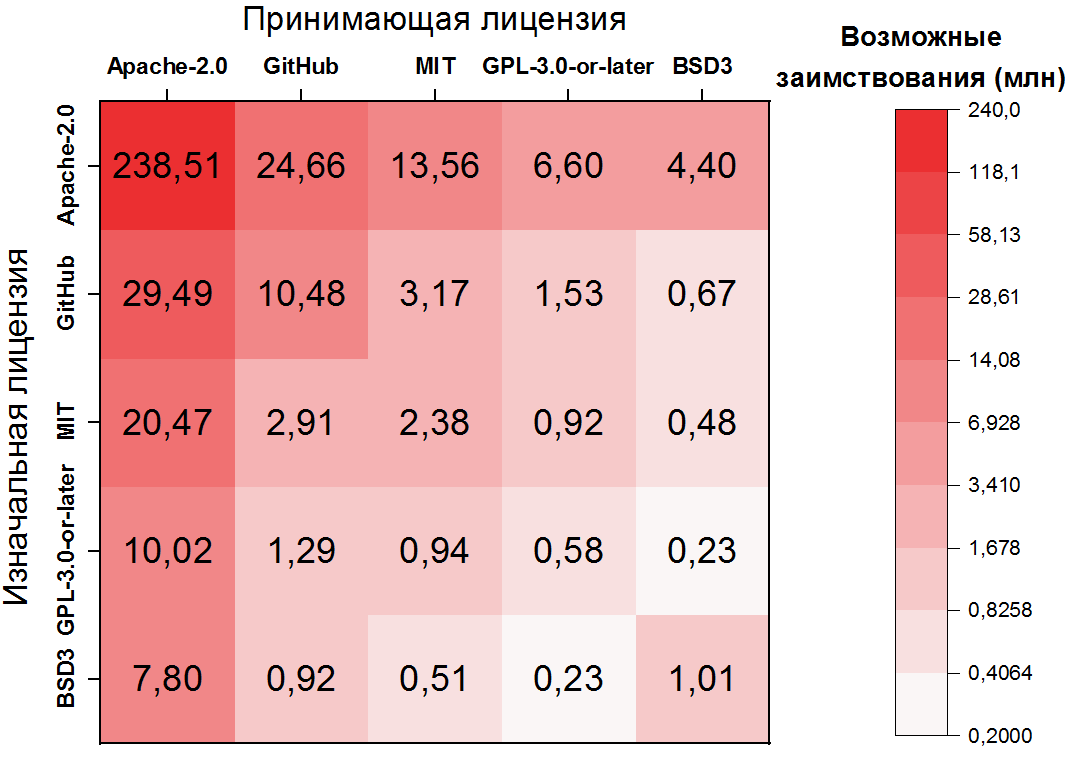
Possible licensing violations
The next step in our research is to identify pairs of clones that are potential violations , that is, borrowings that violate the terms of the original and host licenses. To do this, you need to mark the above-mentioned pairs of licenses as allowed or forbidden transitions. So, for example, the most popular transition ( Apache-2.0 → Apache-2.0 ) is, of course, allowed, but the second one ( GitHub → Apache-2.0 ) is prohibited. But there are very, very many, there are thousands of such pairs.
To deal with this, remember that the rendered first 10 pairs of licenses cover 80% of all pairs of clones. Due to this unevenness, it turned out to be enough to manually mark out only 176 pairs of licenses to cover 99% of the pairs of clones, which seemed to us quite acceptable accuracy. Among these couples, we considered four types of couples prohibited:
- Copy from files without license (GitHub). As already mentioned, such copying requires direct permission from the author of the code, and we assume that in the vast majority of cases it is not.
- Copying to files without a license is also prohibited, because this is essentially erasing, removing licenses. Permissive licenses such as Apache-2.0 or BSD allow code to be reused in other licenses (including proprietary ones), but even these require that the original license be retained in the file.
- .
- (, Apache-2.0 → GPL-2.0).
All other rare pairs of licenses covering 1% of clones were marked as permissive (so as not to blame anyone unnecessarily), except for those where code without licenses appears (which can never be copied).
As a result, after the markup, it turned out that 72.8% of borrowings are permitted borrowings, and 27.2% are prohibited. The following charts show the most violated and the most violating licenses.

On the left are the most violated licenses, that is, the sources of the largest number of possible violations. Among them, the first place is occupied by files without licenses, which is an important practical note - you need to especially closely monitor files without licenses.... One might wonder what the Apache-2.0 permissive license does in this list. However, as you can see from the above heatmap, ~ 25 million forbidden borrowings from it are borrowings to a file without a license, so this is a consequence of its popularity.
On the right are licenses that are copied with violations, and here most of all the same Apache-2.0 and GitHub are presented.
Origin of individual methods
Finally, we come to the last point of our research. All this time we talked about pairs of clones, as is customary in such studies. However, you need to understand a certain one-sidedness, incompleteness of such judgments. The fact is that if, for example, one piece of code has 20 "older" brothers (or "parents", who knows), then all 20 pairs will be considered potential borrowings. That is why we are talking about "potential" and "possible" borrowings - it is unlikely that the author of a particular method borrowed it from 20 different places. Despite this, this reasoning can be viewed as a reasoning about clones between different licenses.
To avoid such incomplete judgments, you can look at the same picture from a different angle. The cloning picture is actually a directed graph: all methods are vertices on it, which are connected by directed edges from the oldest to the youngest (if you do not take into account the methods dated the same day). In the previous two sections, we looked at this graph from the point of view of edges: we took each edge and studied its vertices (getting those very pairs of licenses). Now let's look at it from the point of view of the vertices. Each vertex (method) on the graph has ancestors ("senior" clones) and descendants ("junior" clones). The links between them can also be divided into "allowed" and "forbidden".
Based on this, each method can be attributed to one of the following categories, the graphs of which are shown in the image (here the solid lines indicate prohibited borrowing, and the dotted lines - allowed):

Two of the presented configurations may constitute a violation of the licensing conditions:
- A severe violation means that the method has ancestors and all transitions from them are forbidden. This means that if the developer actually copied the code, then he did it in violation of the licenses.
- A weak violation means that the method has ancestors, and only some of them are behind forbidden transitions. This means that the developer may have copied the code in violation of the license.
Other configurations are not violations:
- , , .
- — , — , .
- , , — , . , , — , . : , , , , ( , , ).
So how are the methods distributed in our dataset?

You can see that about a third of the methods have no clones at all, and another third have clones only in linked projects. On the other hand, 5.4% of the methods represent "mild violation" and 4% - "severe violation". Although these numbers may not seem very large, there are still hundreds of thousands of methods in more or less large projects.
TL; DR
Considering that this article contains a lot of empirical figures and graphs, let's repeat our main findings:
- There are millions of methods that have clones, and there are more than a billion pairs between them.
- , Java- 50 , 94 , : Apache-2.0 . Apache-2.0 .
- , 27,2%, .
- 35,4% , 5,4% «» , 4% «» .
?
In conclusion, I would like to talk about why all of the above is needed at all. I have at least three answers.
First, it's interesting . Licensing is as diverse as all other aspects of programming. The list of licenses itself is quite curious due to the specificity and rarity of some licenses, people write and work with them in different ways. This also undoubtedly applies to clones in the code and code similarity in general. There are methods with thousands of clones, and there are methods without a single one, while at a glance it is not always easy to notice the fundamental difference between them.
Secondly, a detailed analysis of our findings allows us to formulate several practical tips :
- - . Apache-2.0, MIT, BSD-3-Clause, GPL LGPL.
- : . - , , .
- GitHub, . . — , . : - , , , , . , .
For clear descriptions of licenses, as well as advice on choosing a license for your new project, you can turn to services such as tldrlegal or choosealicense .
Finally, the data obtained can be used to create tools . Right now, our colleagues are developing a way to quickly determine licenses using machine learning methods (for which you just need a lot of specific licenses) and an IDE plugin that will allow developers to track dependencies in their projects and notice possible incompatibilities in advance.
Hopefully, you've learned something new from this article. Compliance with the basic licensing terms is not so cumbersome, and you can do everything according to the rules with a minimum of effort. Let's educate, educate others, and move closer to the dream of the "right" open source software together!