
For example, you have a SharePoint document library. When you add a file to this library, you often additionally supply the file with certain metadata. Create several fields and write some information into them in order to classify the files in this library. But this is done manually and for each file you need to enter data over and over again. SharePoint Syntex is designed to automate this process by extracting key data from a file according to a customized model and saving this data to library fields. That sounds good. Let's see how it works?
How do I activate SharePoint Syntex?
Since SharePoint Syntex comes under a separate license, we need to obtain this license. Go to the Microsoft website, find the SharePoint Syntex product and click "Free Trial".

After entering your Microsoft 365 account and confirming the activation of the trial license, go to the Microsoft 365 admin center. Next, go to the "Setup" section in the left menu and select the Automate Content Understanding item. In the case of the Russian locale, like mine, it will sound like “Content comprehension automation”.
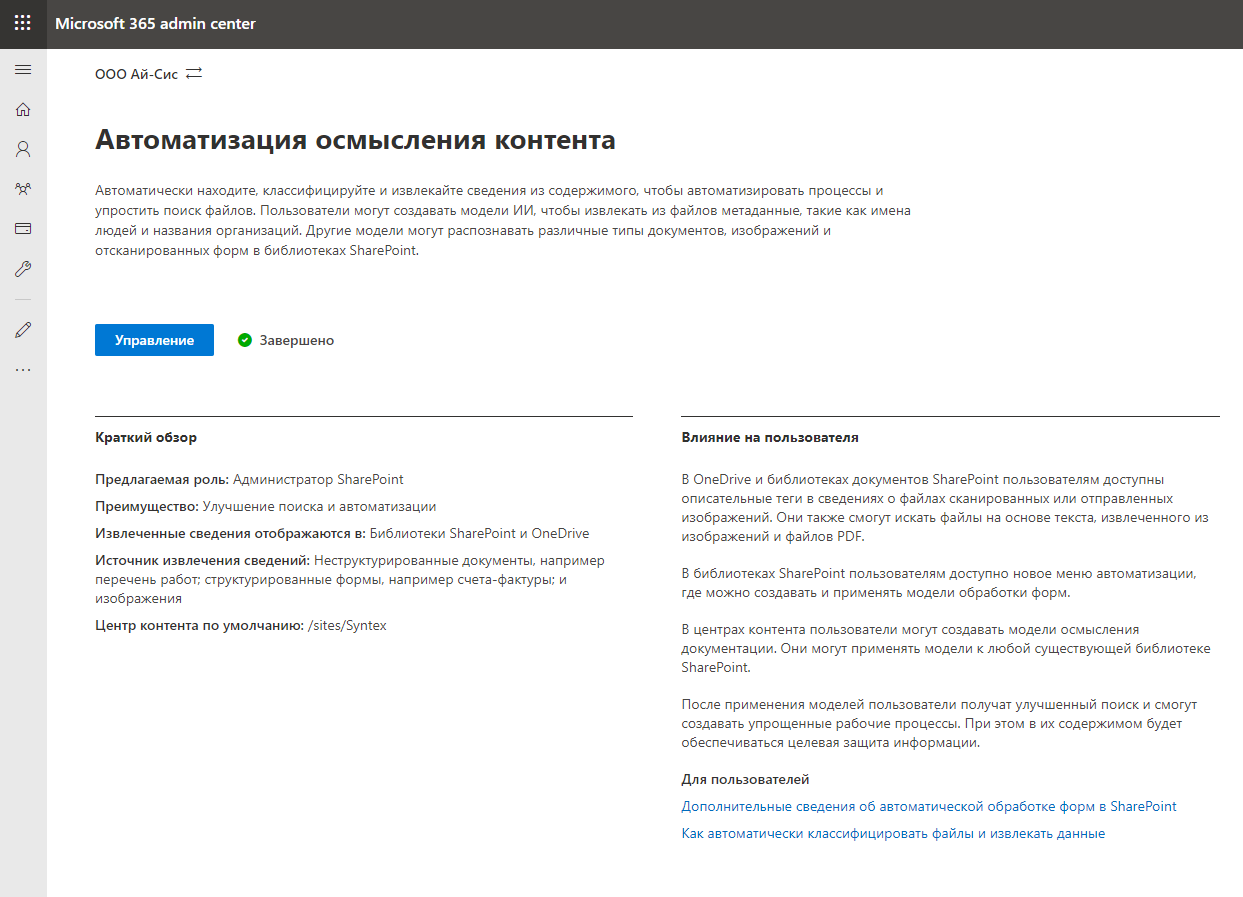
We go to "Management" and proceed to setting up the service. First of all, it is necessary to indicate which libraries will support the capabilities of SharePoint Syntex. You can select specific libraries or allow for all libraries. Let's go for broke.
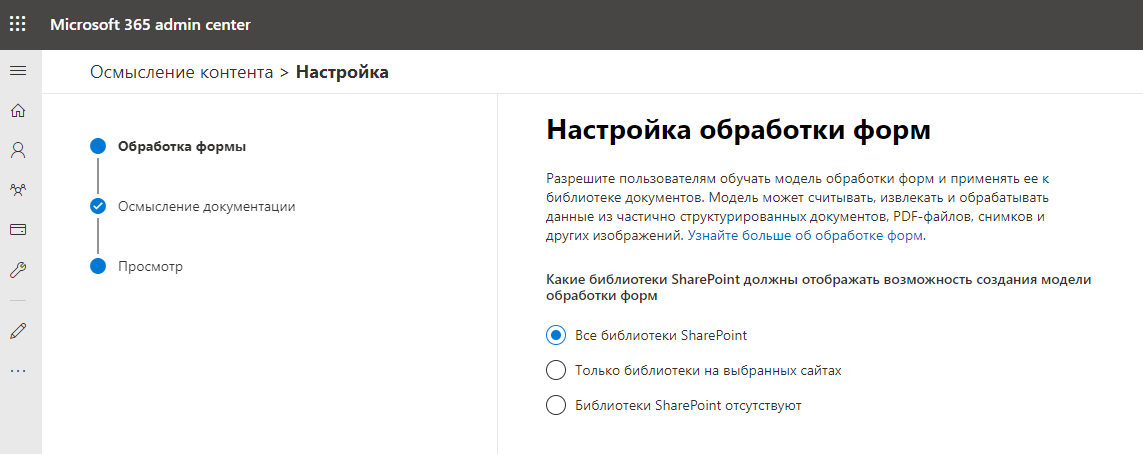
Next, we indicate the name and address of the site, which will be the content center and store the trained data models. It looks like a new SharePoint Online collection site is being created. However, this is exactly what is happening.
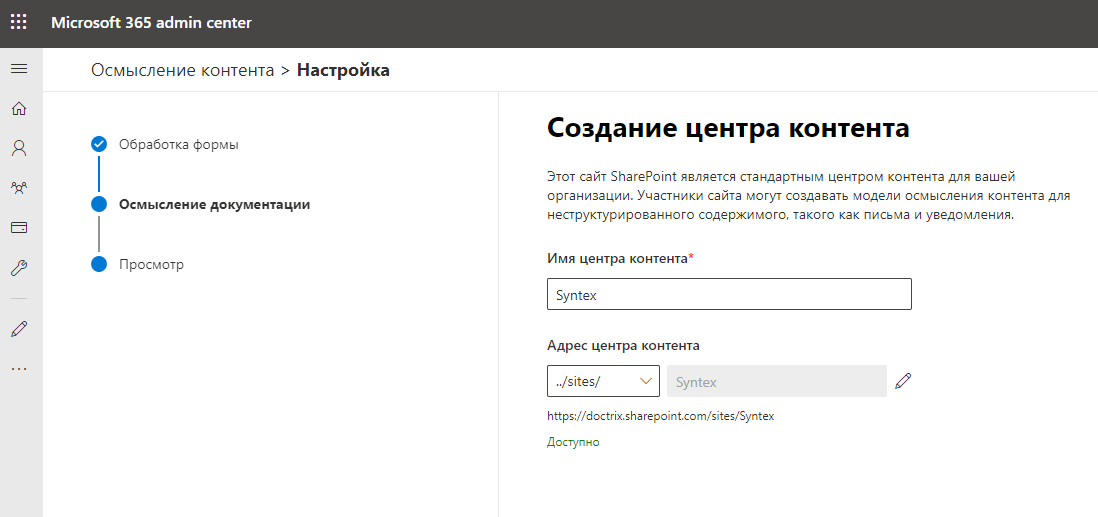
It takes a few minutes to create a content center site. It took me about 5 minutes, I just managed to pour myself some tea. I come, and here the comprehension of the content has already been activated, well, wow.
Configuring SharePoint Syntex
Go to the SharePoint Syntex site. Outwardly, it looks like a regular SharePoint Online site, but this is only at first glance. On this site, we will set up and train data processing and analysis models.
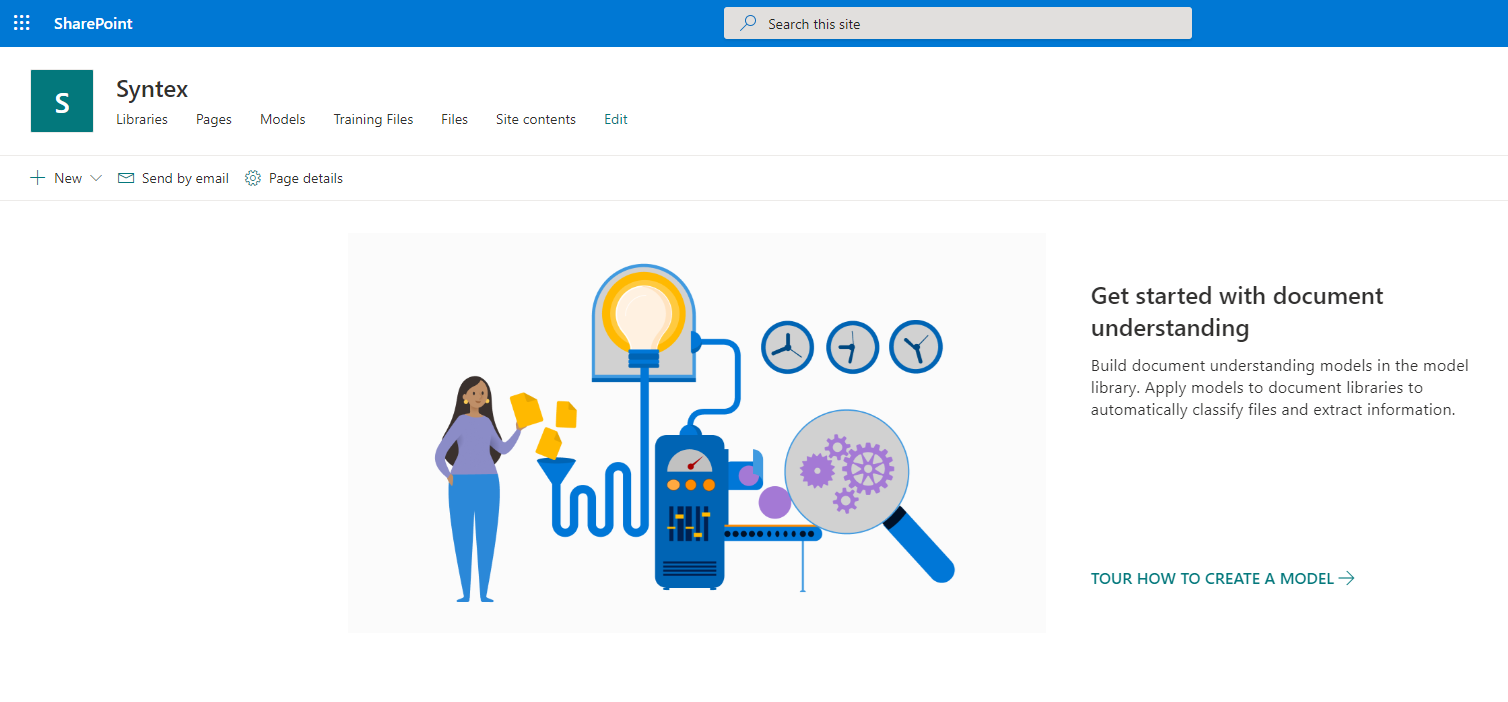
It's time to start tuning the model. Click "New" and select the item "Document Understanding Model".
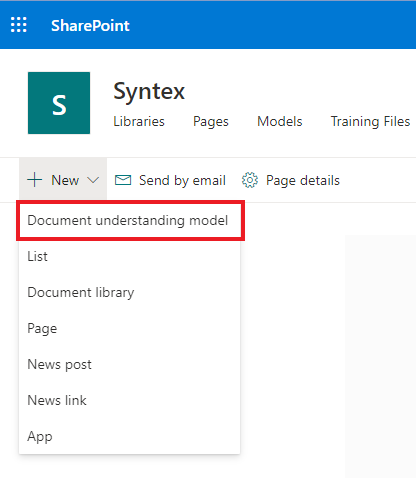
We write the name of our future model and indicate the need to create a new type of content for it. I have already chosen the case, which is probably familiar to you from previous articles, with the application for technical support. Do not disappear the same set of templates for such appeals.
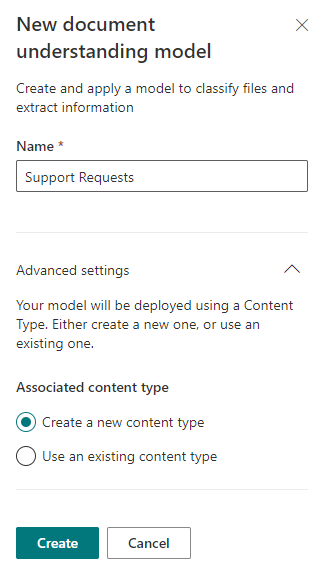
Next, we are greeted by a page with Step-By-Step instructions describing what we need to do to make the future model work, and ideally work correctly. So, first you need to upload several (at least 5 is recommended) files, help SharePoint Syntex classify them as needed, and configure the so-called "Extractors" - templates for extracting data from files. Once you've gone all the way, you can apply this model to the required SharePoint libraries.
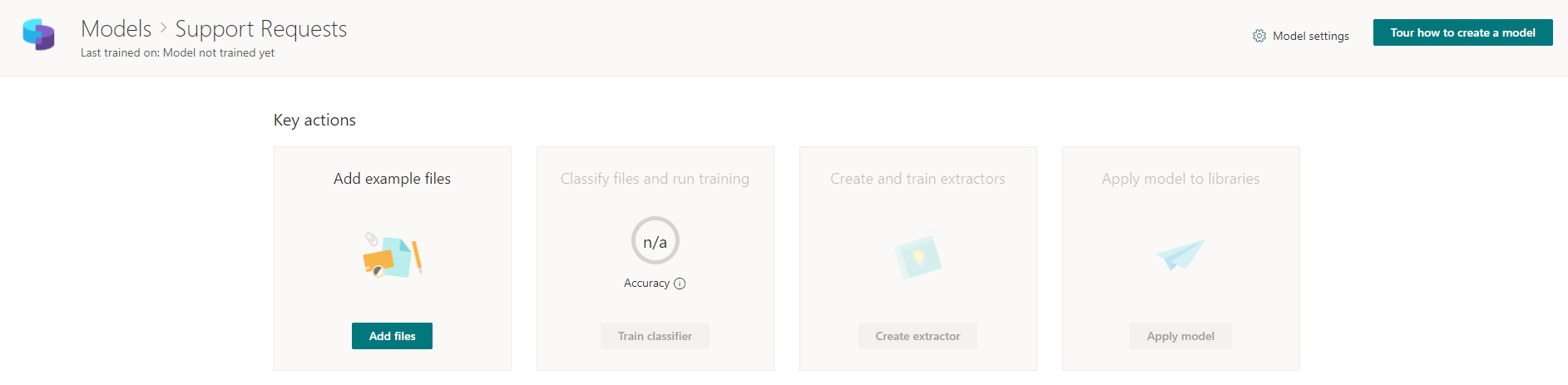
Add prepared template files that will be used to classify future real files.
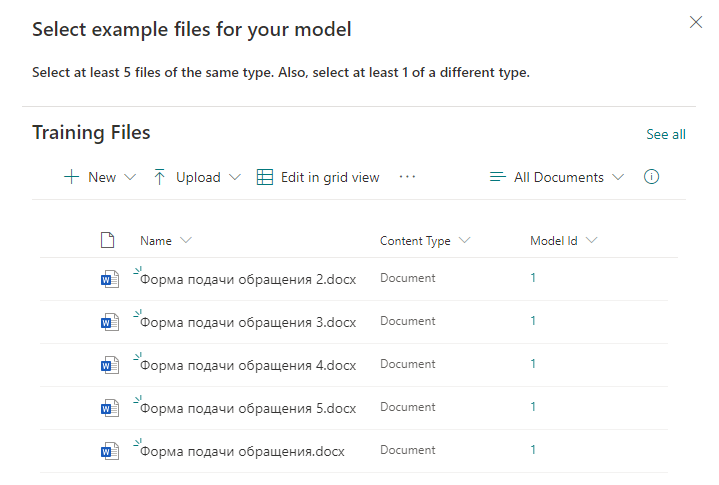
Then we indicate the keywords by which the search for information in the document will be carried out. In each line, we indicate a new word or phrase that will be used for the search.
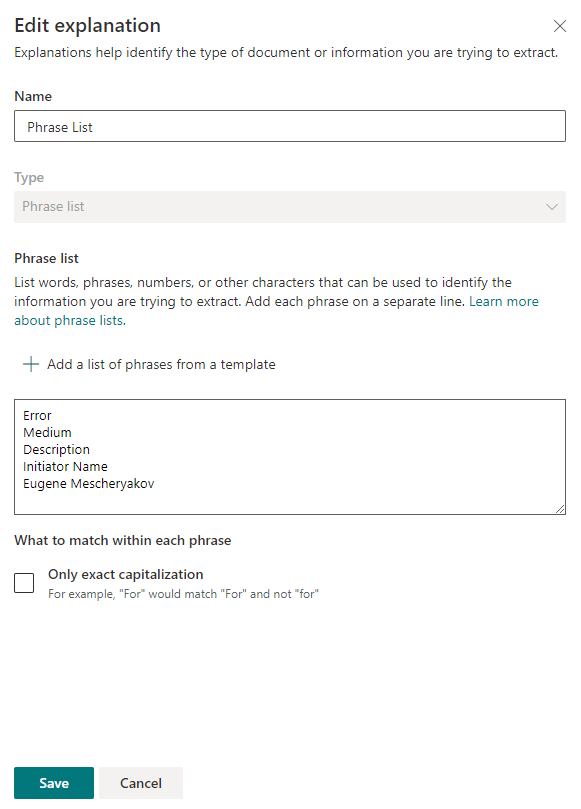
After saving the settings, you can try to scan the existing files for key phrases. If a match is found, then the file will be opposite the "Match".
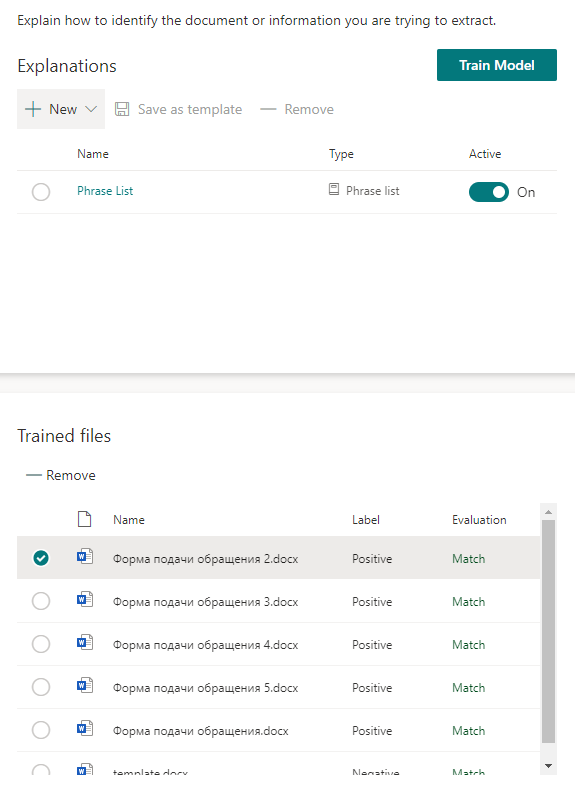
We start training the model and go to pour tea. It will take some time.
After the model is trained, it is necessary to configure the "Extractors" - data extraction models. Each extractor is essentially a specific type of SharePoint field that will be automatically generated in the target library. After adding a file to this library, the information extracted from the file will be written to this field.
When creating an extractor, you need to specify its name and type. Currently 4 types are supported:
- Single line text
- Multi-line text
- date and time
- Number
You can also use existing fields in a SharePoint library.
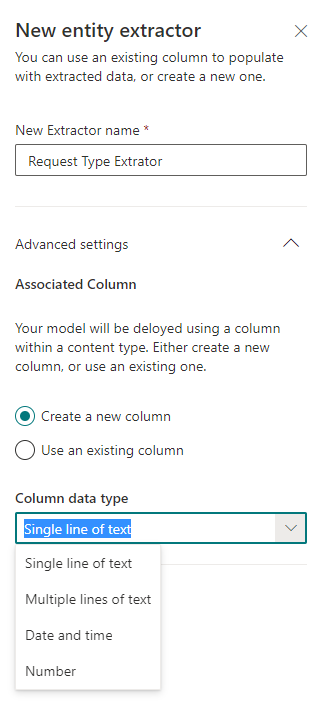
When setting up the extractor in the template of the uploaded file, double-click on the information we want to extract, recognized in the previous step.
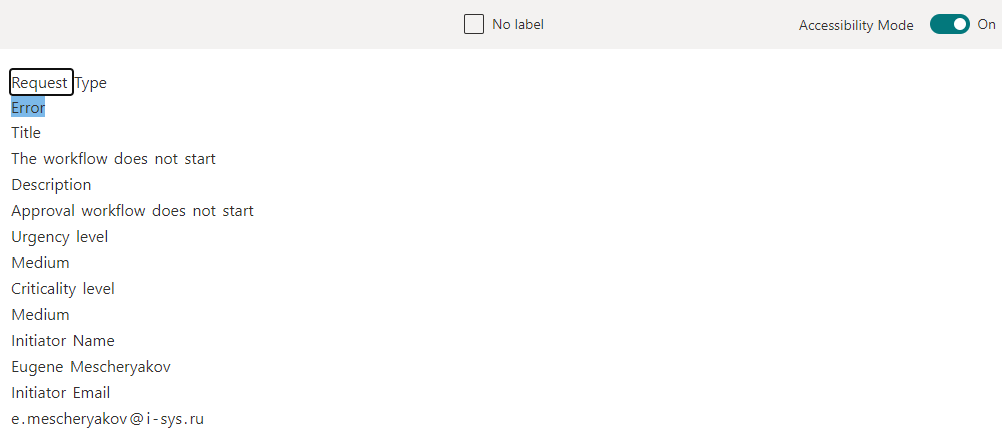
We create several such extractors, mark the necessary data and, after that, move on to the final part - applying the trained model to the SharePoint library and checking if it all works at all.

Select the required SharePoint site and specify the target library. I created the HelpDesk Requests library in advance and did not make any changes in it, leaving it in its original form. We save the settings and go to the library. After saving the SharePoint Syntex settings, new SharePoint fields appear in the library, corresponding by name and type to the created extractors.
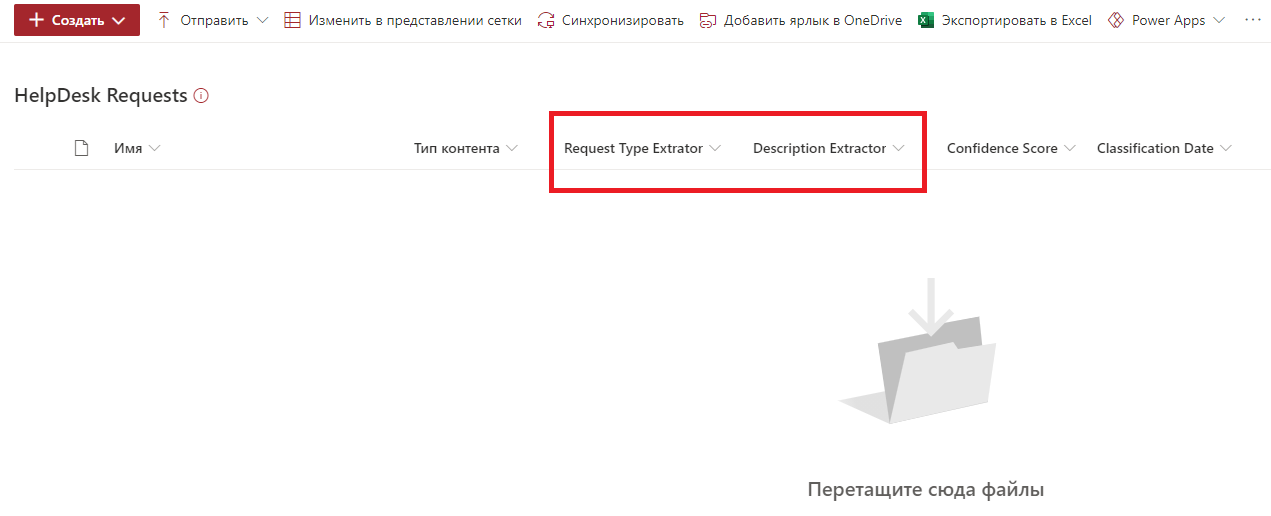
It remains to add the file to the library and check. Add another request template file.

SharePoint Syntex recognized the case type and description. The data is stored in the fields. Everything seems to be in order.
Total
Setting up the SharePoint Syntex data model took me very little time, everything is quite intuitive and easy to configure and use. On the plus side, I see a really useful ability to automatically extract key information from file content and write it to SharePoint fields. This feature can significantly speed up the work and remove unnecessary stages of user work, when, after adding a file, it is still necessary to manually fill in a number of requisites in the library. Cons - I would like more types of fields for extractors and closer integration with Microsoft Power Platform. But I am sure that this will be added soon as part of the next updates.
Also, SharePoint Syntex requires a separate license ($ 5 per user per month) and, at the moment, is not included in the Enterprise licenses of Microsoft 365. But in the future, this may change and perhaps SharePoint Syntex will become part of the basic services of Microsoft 365. Try activating the trial version for a month and see the capabilities of this service. Have a nice day everyone!