I should note that a month after I got acquainted with this technology, I started using antidepressants. Whether NiFi was the trigger or the last straw is not known for certain, as well as its involvement in this fact. But, since I undertook to outline everything that awaits a potential beginner on this path, I must be as frank as possible.
At a time when, technically, Apache NiFi is a powerful link between various services (it exchanges data between them, allowing them to be enriched and modified along the way), I look at it from the point of view of an analyst . This is because NiFi is a very handy ETL tool. In particular, as a team, we focus on building their SaaS architecture.
The experience of automating one of my workflows, namely the formation and distribution of weekly reports on Jira Software , I want to disclose in this article. By the way, I will also describe and publish the task tracker analytics methodology, which clearly answers the question - what are the employees doing - I will also describe and publish in the near future.
Despite the dedication of this article to beginners, I think it is correct and useful if more experienced architects (gurus, so to speak) review it in crommentions or share their use cases of NiFi in various fields of activity. A lot of guys, including me, will thank you.
Apache NiFi concept in brief.
Apache NiFi is an opensource product for automation and data flow control between systems. Getting started with it is important to immediately realize two things.
The first is the Low Code zone. What I mean? It is assumed that all manipulations with data from the moment they enter NiFi up to extraction can be performed using standard tools (processors). For special cases, there is a processor for running scripts from bash.
This suggests that doing something in NiFi is wrong - it's rather difficult (but I succeeded! - that's the second point). Difficult because any processor will kick you right away - Where to send errors? What to do with them? How long to wait? And here you gave me a little space! Have you read the documentation carefully? etc.

The second (key) is the concept of streaming programming, and nothing more. Here, I personally, did not immediately get it (please, do not judge). Having experience in functional programming in R, I unknowingly formed functions in NiFi. Ultimately - redo - my colleagues told me when they saw my futile attempts to make these "functions" friends.
I think the theory is enough for today, let's learn everything from practice better. Let's formulate a similarity of technical specification for weekly Jira analytics.
- Get the worklog and history of changes from the fat for the week.
- Display basic statistics for this period and answer the question: what was the team doing?
- Send report to boss and colleagues.
In order to bring more benefit to the world, I did not stop at a weekly period and developed a process with the ability to download a much larger amount of data.
Let's figure it out.
The first steps. Fetching data from the API
Apache NiFi doesn't have such a thing as a separate project. We only have a common workspace and the ability to form groups of processes in it. This is quite enough.
Find the Process Group in the toolbar and create the Jira_report group. Go to the group and start building the workflow. Most of the processors from which it can be assembled require Upstream Connection. In simple words, this is a trigger on which the processor will fire. Therefore, it is logical that the entire flow will begin with a regular trigger - in NiFi, this is the GenerateFlowFile processor. What does he do. Creates a streaming file that consists of a set of attributes and content. Attributes are string key / value pairs that are associated with content.
Content is a regular file, a set of bytes. Imagine that content is an attachment to a FlowFile.
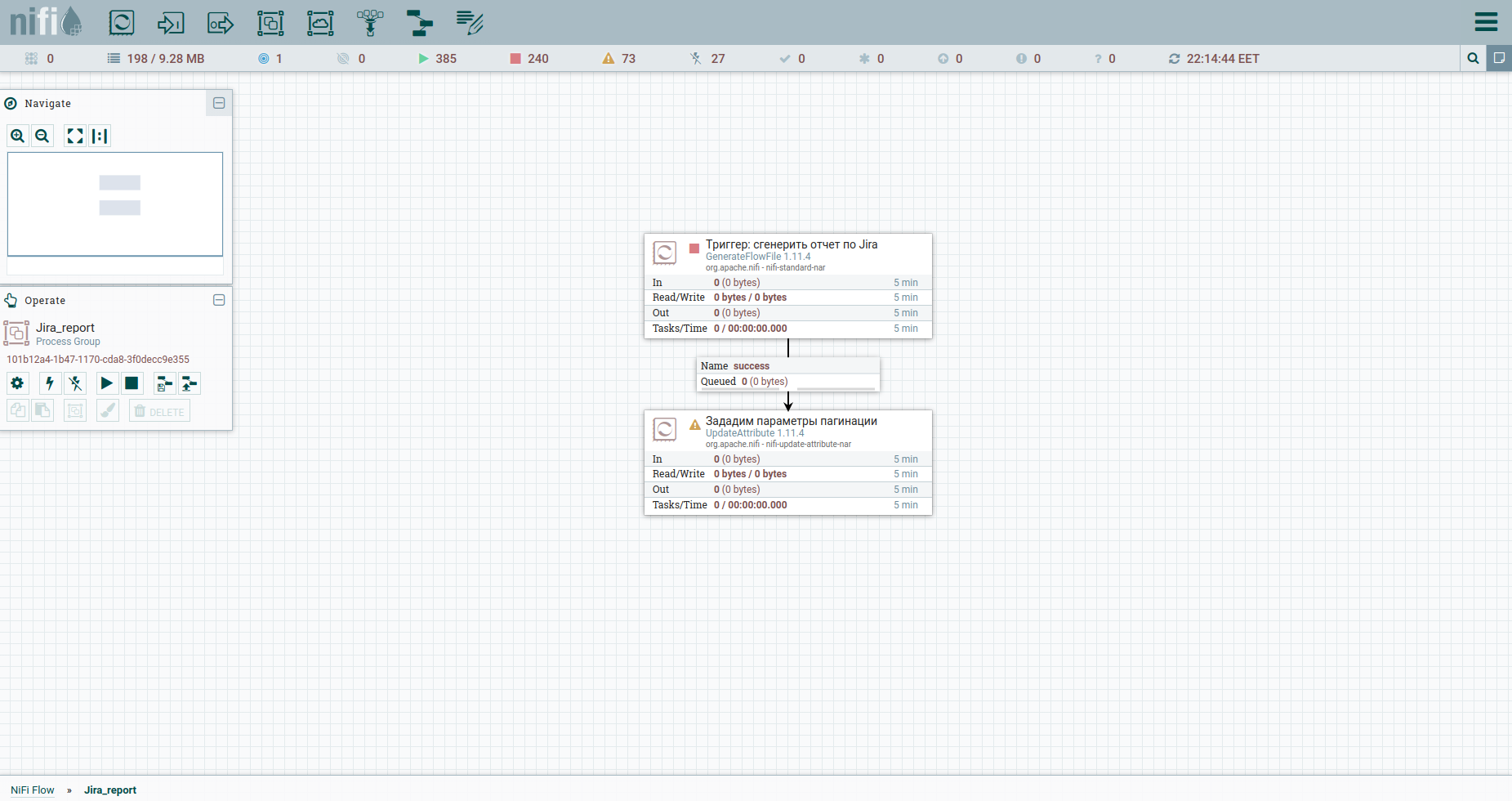
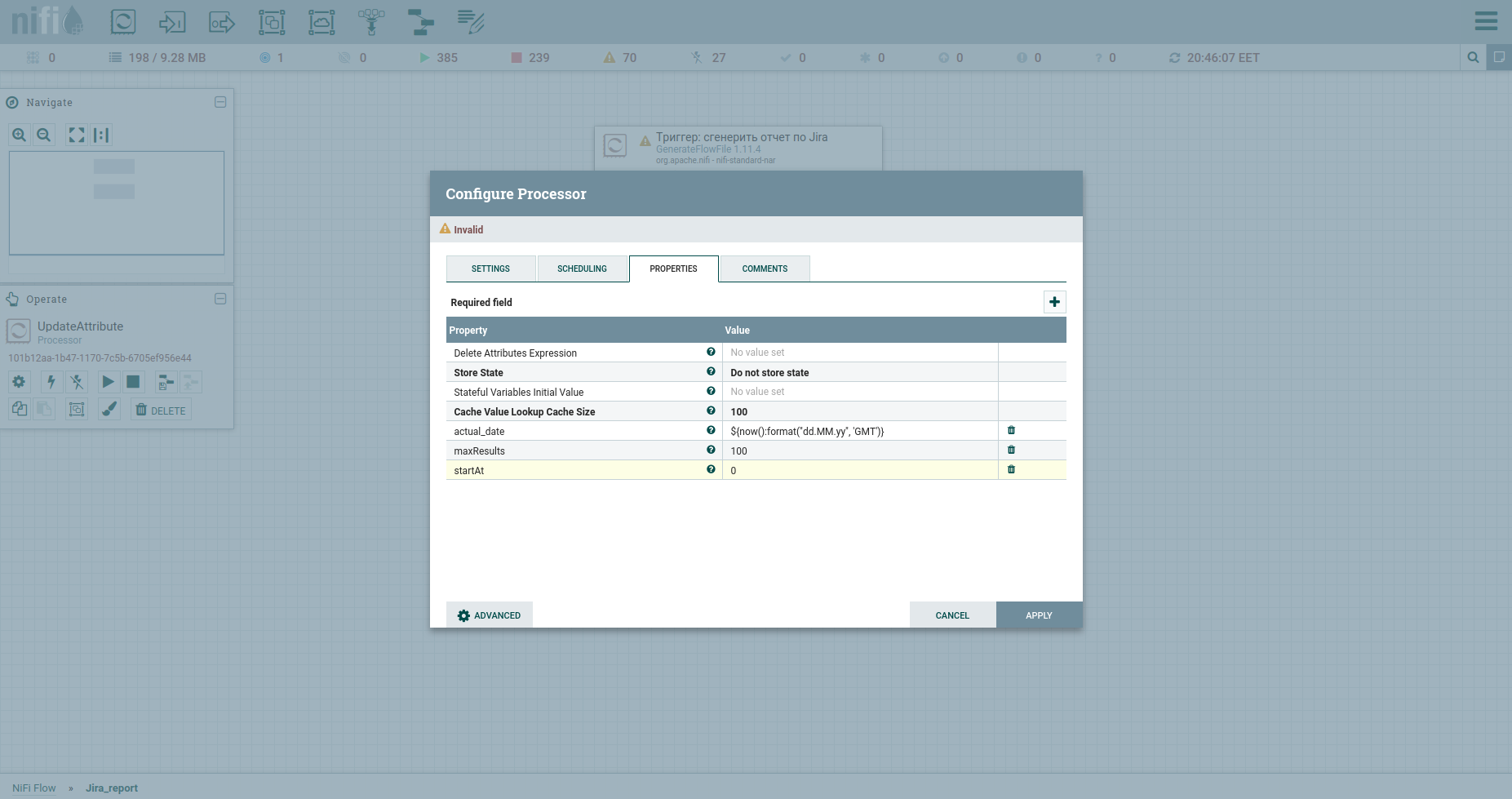
We do Add Processor → GenerateFlowFile. In the settings, first of all, I strongly recommend setting the processor name (this is a good tone) - the Settings tab. Another point: by default, GenerateFlowFile generates stream files continuously. It is unlikely that you will ever need this. We immediately increase the Run Schedule, for example, up to 60 sec - the Scheduling tab. Also, on the Properties tab, we will indicate the start date of the reporting period - the report_from attribute with a value in the format - yyyy / mm / dd. According to the Jira API documentation, we have a limit on unloading issues - no more than 1000. Therefore, in order to get all tasks, we will have to form a JQL request, which specifies the pagination parameters: startAt and maxResults.

Let's set them with attributes using the UpdateAttribute processor. At the same time, we will fasten the date of the report generation. We'll need it later. You've probably noticed the actual_date attribute. Its value is set using Expression Language. Catch a cool cheat sheet on it. That's all, we can form JQL to fat - we will indicate the pagination parameters and the required fields. Subsequently, it will be the body of the HTTP request, therefore, we will send it to the content. To do this, we use the ReplaceText processor and specify its Replacement Value something like this:
{"startAt": ${startAt}, "maxResults": ${maxResults}, "jql": "updated >= '2020/11/02'", "fields":["summary", "project", "issuetype", "timespent", "priority", "created", "resolutiondate", "status", "customfield_10100", "aggregatetimespent", "timeoriginalestimate", "description", "assignee", "parent", "components"]}Notice how attribute links are written.
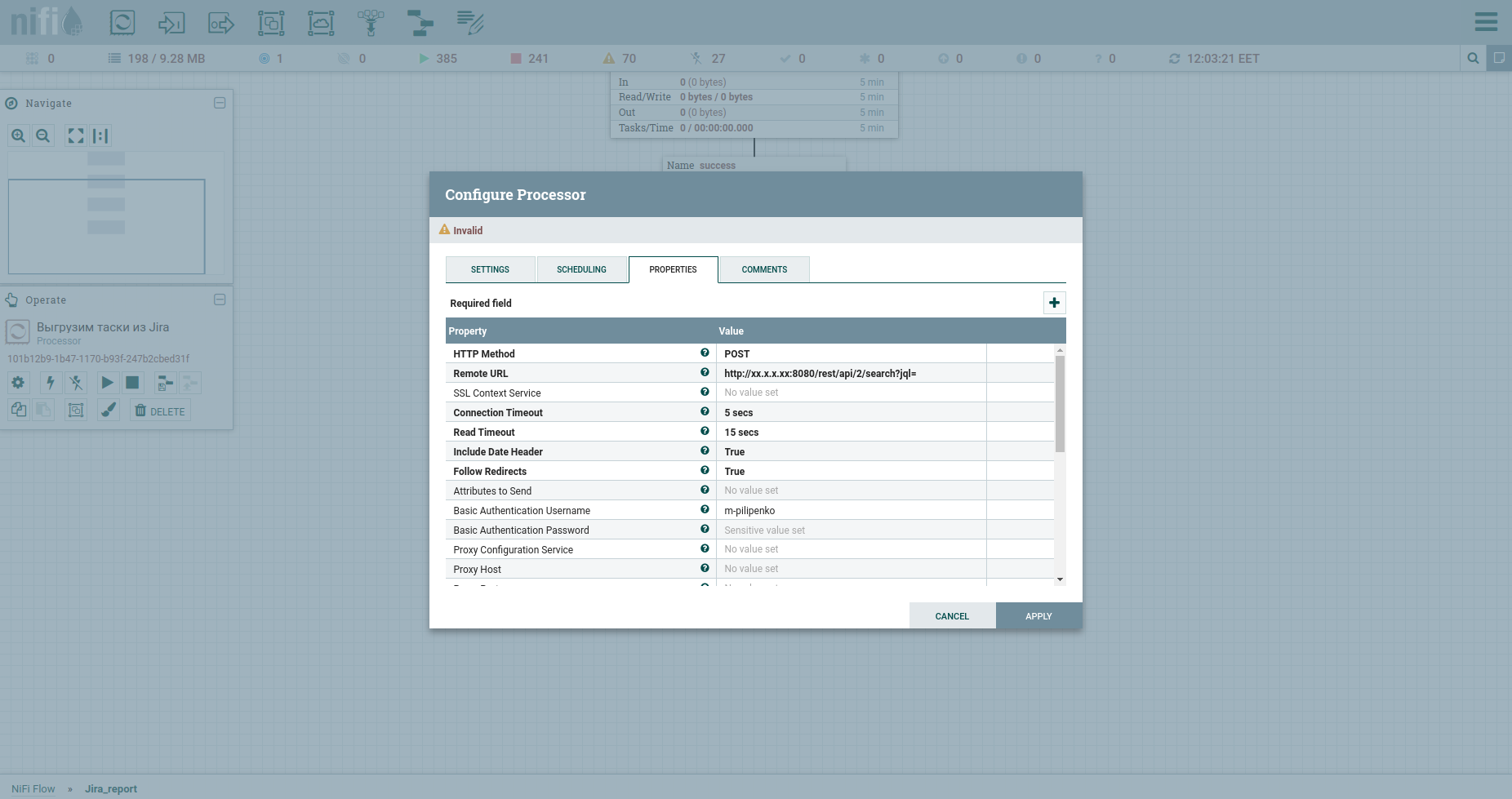
Congratulations, we're ready to make an HTTP request. The InvokeHTTP processor will fit here. By the way, he can do anything ... I mean the methods GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS. Let's modify its properties as follows:
HTTP Method we have POST.
The remote URL of our fat includes IP, port, and / rest / api / 2 / search? Jql =.
Basic Authentication Username and Basic Authentication Password are credentials to fat.
Change the Content-Type to application / json b put true in the Send Message Body, which means to send JSON that will come from the previous processor in the request body.
APPLY.
The response of the apish will be a JSON file that will be included in the content. We are interested in two things in it: the total field containing the total number of tasks in the system and the issues array, which already contains some of them. Let's parse the answer and get acquainted with the EvaluateJsonPath processor.
If JsonPath points to one object, the parsing result will be written to the flow file attribute. Here is an example - the total field and the following screen. In the case when JsonPath points to an array of objects, as a result of parsing the flow file will be split into a set with content corresponding to each object. Here's an example - the issue field. We put another EvaluateJsonPath and write: Property - issue, Value - $ .issue.

Now our stream will now consist not of one file, but of many. The content of each of them will contain JSON with information about one specific task.
Move on. Remember we set maxResults to 100? After the previous step, we will have one hundred first tasoks. Let's get more and implement pagination.
To do this, let's increase the start task number by maxResults. Let's use UpdateAttribute again: we will indicate the startAt attribute and assign it a new value $ {startAt: plus ($ {maxResults})}.
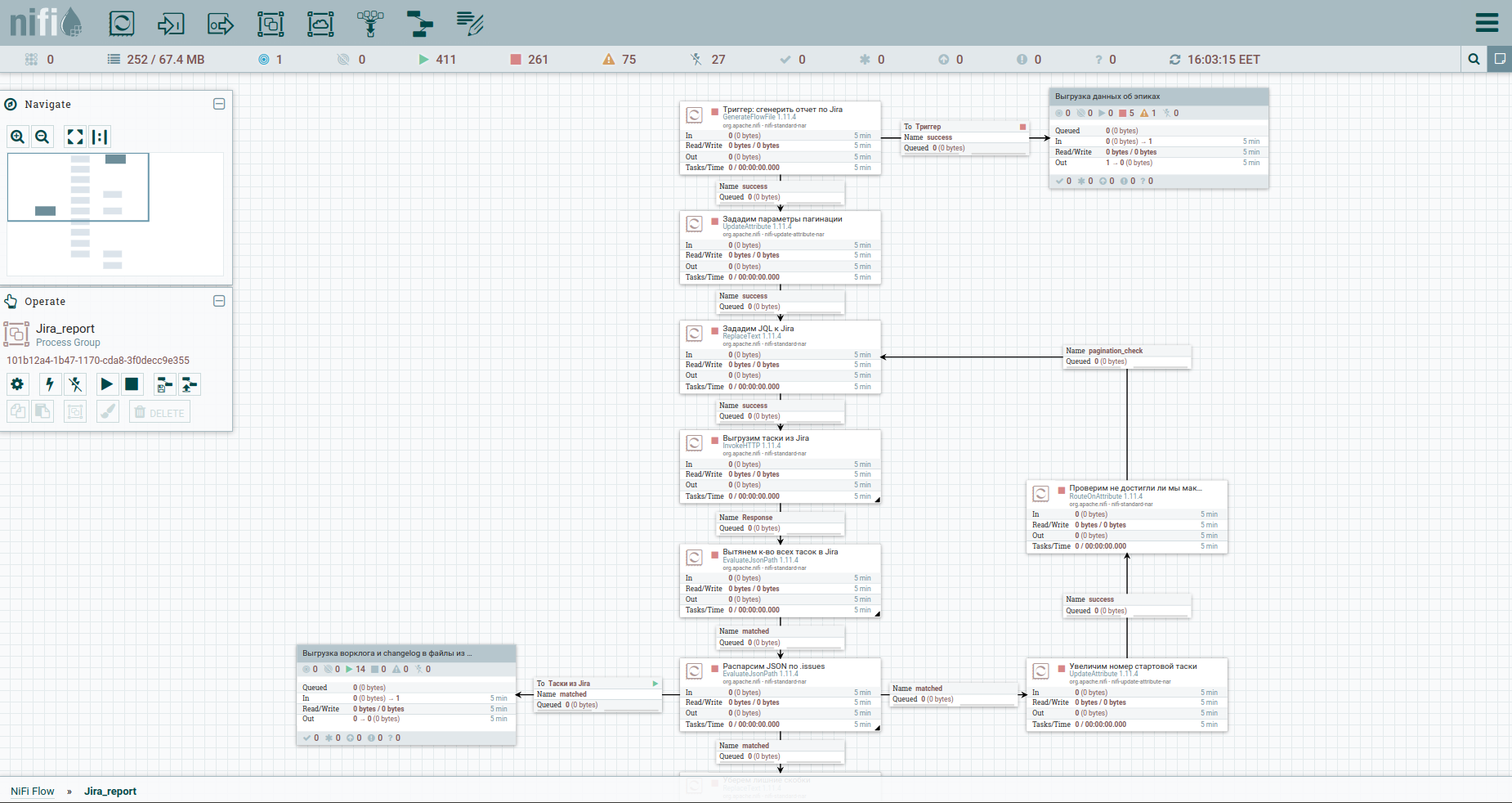
Well, we can't do without a check for reaching the maximum of TASK - the RouteOnAttribute processor. The settings are as follows: And loop. In total, the cycle will run as long as the start task number is less than the total number of tasks. At the exit from it - a stream of tasoks. This is how the process looks now:

Yes, friends, I know - you are tired of reading my comments to each square. You want to understand the principle itself. I have nothing against it.
This section should make it easier for an absolute beginner to enter NiFi. Then, having in hand a generously presented template by me, it will not be difficult to delve into the details.
Gallop across Europe. Uploading a worklog, etc.
Well, let's speed up. As they say, find the differences: For easier perception, I moved the process of unloading the worklog and the history of changes into a separate group. Here it is: To get around the limitations when automatically unloading a worklog from Jira, it is advisable to refer to each task separately. That's why we need their keys. The first column just converts the stream of tasoks into a stream of keys. Next, we turn to the apish and save the answer. It will be convenient for us to arrange the worklog and changelog for all tasks in the form of separate documents. Therefore, we will use the MergeContent processor and glue the contents of all flow files with it.
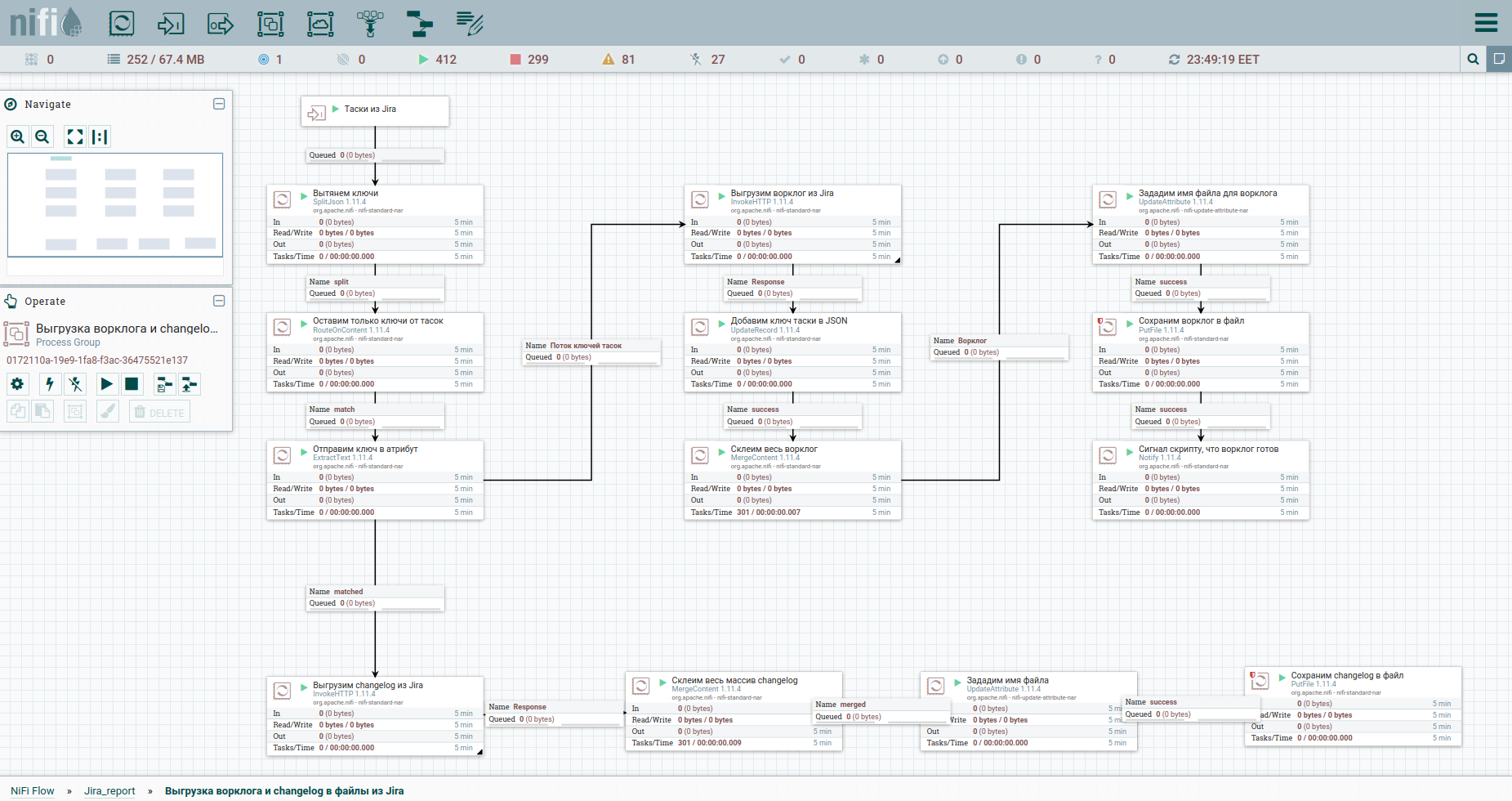
Also in the template you will notice a group for unloading data by epics. An epic in Jira is a common task that many others bind to. This group will be useful in the case when only part of the tasks is mined, so as not to lose information about the epics of some of them.
The final stage. Report generation and sending by email
Okay. All the dots were unloaded and went in two ways: to the group for unloading the worklog and to the script for generating the report. By the latter, we have one STDIN, so we need to collect all tasks in one pile. We will do this in MergeContent, but before that we will slightly correct the content so that the final json is correct. An interesting Wait processor is present in front of the script generation square (ExecuteStreamCommand). He waits for a signal from the Notify processor, which is in the worklog unloading group, that everything is ready there and you can move on. Next, we run the script from bash-a - ExecuteStreamCommand. And we send the report using PutEmail to the whole team.

I will tell you in detail about the script, as well as about the experience of implementing Jira Software analytics in our company in a separate article, which will be ready the other day.
In short, the reporting we have developed provides a strategic view of what a unit or team is doing. And this is invaluable for any boss, you must agree.
Afterword
Why exhaust yourself if you can do all this with a script at once, you ask. Yes, I agree, but partially.
Apache NiFi doesn't simplify the development process, it simplifies the operation. We can stop any thread at any time, make an edit and start over.
In addition, NiFi gives us a top-down view of the processes that the company lives by. In the next group, I will have another script. Another one will be my colleague's trial. You get it, right? Architecture in the palm of your hand. As our boss jokes, we are implementing Apache NiFi so that we can fire you all later, and I was the only one pushing the buttons. But this is a joke.
Well, in this example, the buns in the form of a schedule task for generating reports and sending letters are also very, very pleasant.
I confess, I was planning to pour out my soul and tell you about the rake I stepped on in the process of studying technology - how many of them. But here it is already longread. If the topic is interesting, please let me know. In the meantime, friends, thank you and wait for you in the comments.
useful links
An ingenious article that covers Apache NiFi right on your fingers and by letters.
A short guide in Russian.
A cool Expression Language cheat sheet .
The English-speaking Apache NiFi community is open to questions.
The Russian-speaking Apache NiFi community on Telegram is more alive than all living things, come in.