
At the beginning of this year, Tensor held a meetup in the city of Ivanovo, where I made a presentation about experiments with fuzzing testing of the interface. Here is a transcript of this report.
When will monkeys replace all QA? Is it possible to abandon manual testing and UI autotests, replacing them with fuzzing? What would a complete state and transition diagram look like for a simple TODO application? An example of implementation and how such fuzzing works further under the cut.
Hello! My name is Sergey Dokuchaev. For the last 7 years I have been doing testing in all its forms at Tenzor.

We have over 400 people responsible for the quality of our products. 60 of them are dedicated to automation, security and performance testing. In order to support tens of thousands of E2E tests, monitor performance indicators of hundreds of pages and identify vulnerabilities on an industrial scale, you need to use tools and methods that have been tested and time-tested in battle.

And, as a rule, they talk about such cases at conferences. But besides this, there are many interesting things that are still difficult to apply on an industrial scale. That's interesting and let's talk about it.

In the movie "The Matrix" in one of the scenes Morpheus offers Neo to choose a red or blue pill. Thomas Anderson worked as a programmer and we remember what choice he made. If he were a notorious tester, he would have devoured both tablets to see how the system would behave in non-standard conditions.
Combining manual testing and autotests has become almost standard. Developers know best how their code works and write unit tests, functional testers check new or frequently changing functionality, and all the regression goes to various autotests.
However, in creating and maintaining autotests, suddenly there is not much auto- and quite a lot of manual work:
- You need to figure out what and how to test.
- You need to find the elements on the page, drive the necessary locators into Page Objects.
- Write and debug the code.
- — . / , , ROI .
Fortunately, there are not two or three tablets in the testing world. And a whole scattering: semantic testing, formal methods, fuzzing testing, AI-based solutions. And even more combinations.

The assertion that any monkey that will type on a typewriter for an infinitely long time will be able to type any given text in advance has taken root in testing. Sounds good, we can make one program endlessly click on the screen in random places and eventually we can find all the errors.
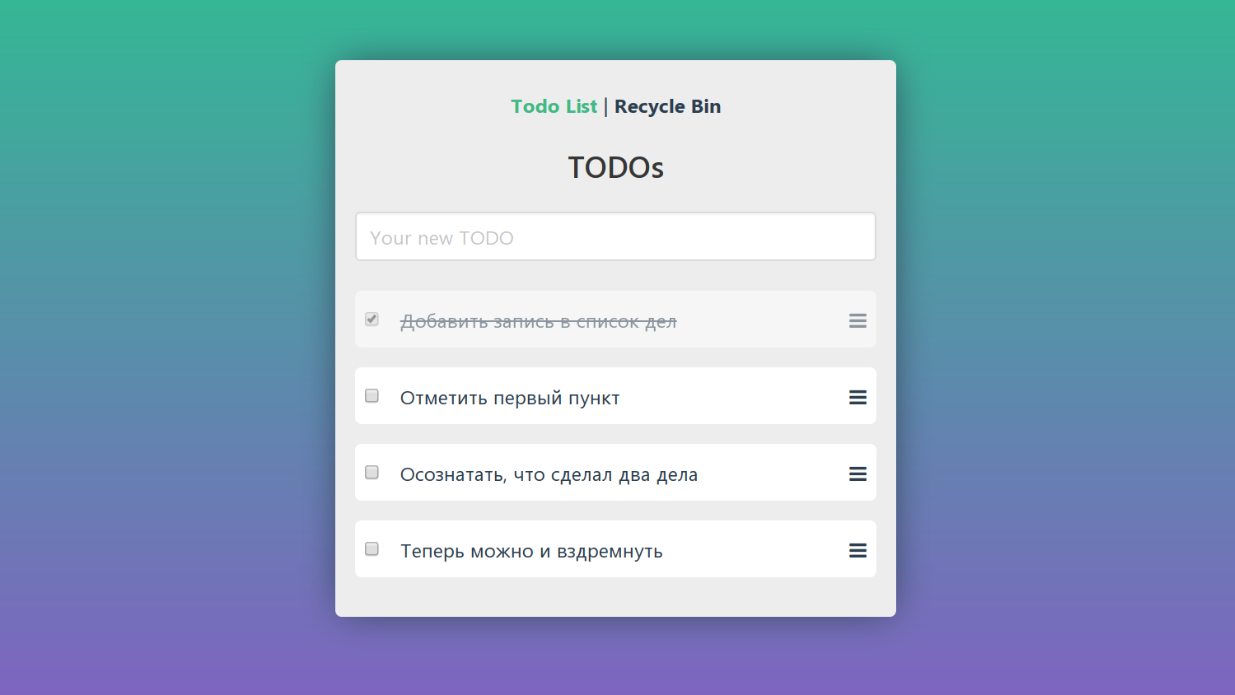
Let's say we made such a TODO and want to test it. We take a suitable service or tool and see the monkeys in action:
By the same principle, my cat somehow, lying on the keyboard, irrevocably broke the presentation and had to do it again:

It is convenient when after 10 actions the application throws an exception. Here our monkey immediately understands that an error has occurred, and we can understand from the logs at least approximately how it repeats itself. What if the error occurred after 100K random clicks and looks like a valid response? The only significant advantage of this approach is the maximum simplicity - you poke a button and you're done.

The opposite of this approach is formal methods.

This is a photograph of New York in 2003. One of the brightest and most crowded places on the planet, Times Square is illuminated only by the headlights of passing cars. That year, millions of people in Canada and the United States found themselves in the Stone Age for three days due to a cascading power plant shutdown. One of the key reasons for the incident was a race condition error in the software.
Error-critical systems require a special approach. Methods that rely not on intuition and skills, but on mathematics are called formal. And unlike testing, they allow you to prove that there are no errors in the code. Models are much more difficult to create than to write the code they are supposed to test. And their use is more like proving a theorem in a lecture on calculus.

The slide shows a part of the model of the two-handshake algorithm written in the TLA + language. I think it's obvious to everyone that using these tools when checking molds on the site is comparable to building a Boeing 787 to test the aerodynamic properties of a corn plant.

Even in traditionally error-prone medical, aerospace and banking industries, it is very rare to use this method of testing. But the approach itself is irreplaceable if the cost of any mistake is calculated in millions of dollars or in human lives.
Fuzzing testing is now most often viewed in the context of security testing. And a typical scheme demonstrating this approach, we take from the OWASP guide :

Here we have a site that needs to be tested, there is a database with test data and tools with which we will send the specified data to the site. Vectors are ordinary strings that were obtained empirically. Such strings are most likely to lead to the discovery of a vulnerability. It's like the quotation mark that many people automatically put in place of the numbers in the URL from the address bar.
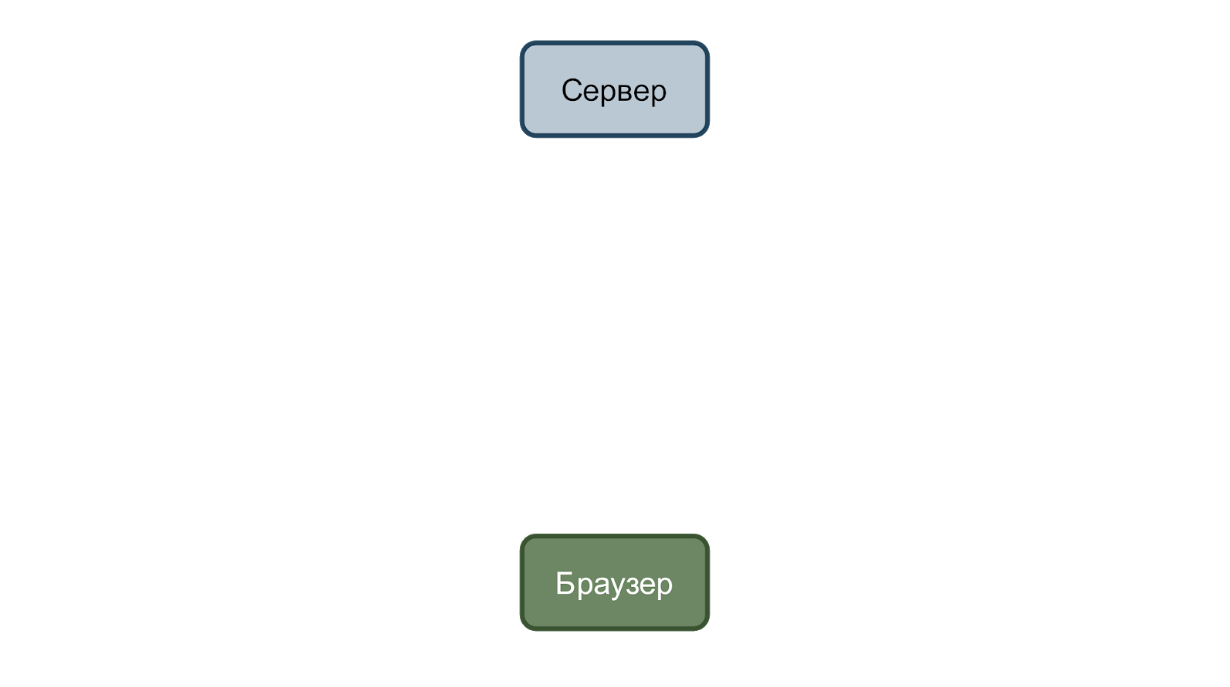
In the simplest case, we have a service that accepts requests and a browser that sends them. Consider a case with changing the user's date of birth.

The user enters a new date and clicks the “Save” button. A request is sent to the server with data in json format.
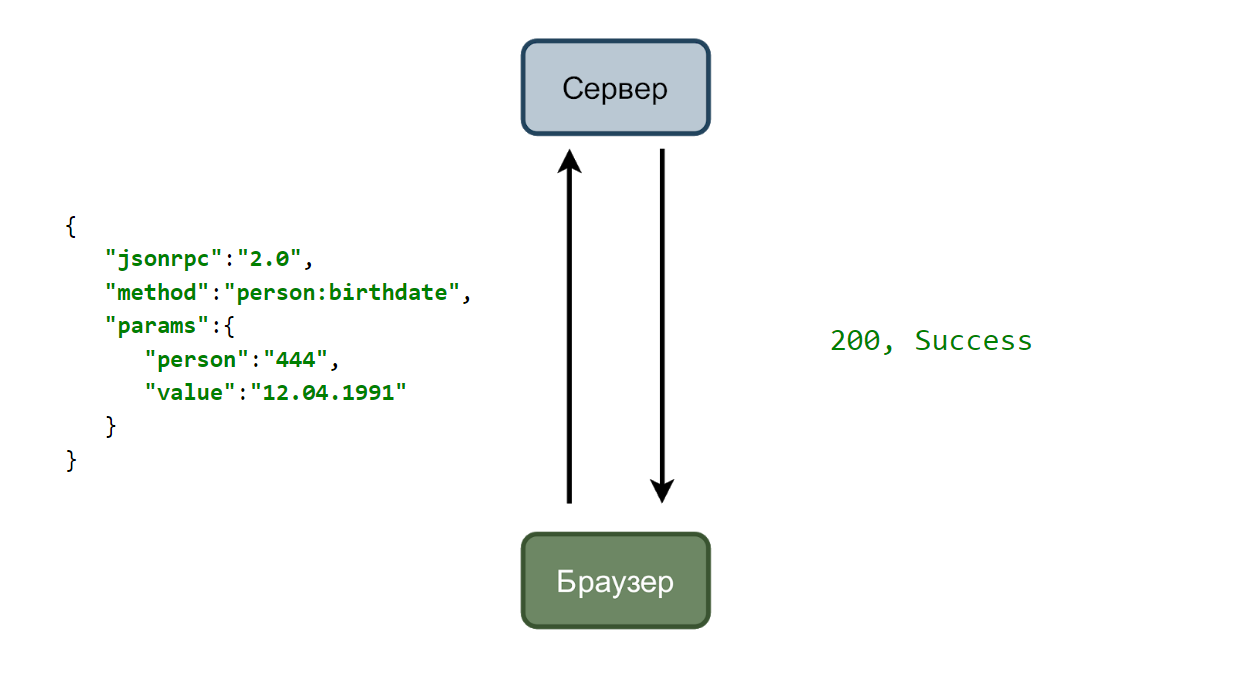
And if all is well, then the service responds with two hundredth code.

It is convenient to work with json's programmatically and we can teach our fuzzing tool to find and determine dates in the transmitted data. And he will begin to substitute various values for them, for example, it will transmit a nonexistent month.

And if in response, instead of a message about an invalid date, we received an exception, then we fix the error.
Fuzzing an API is not difficult. Here we have the transmitted parameters in json, here we send a request, receive a response and analyze it. What about the GUI?
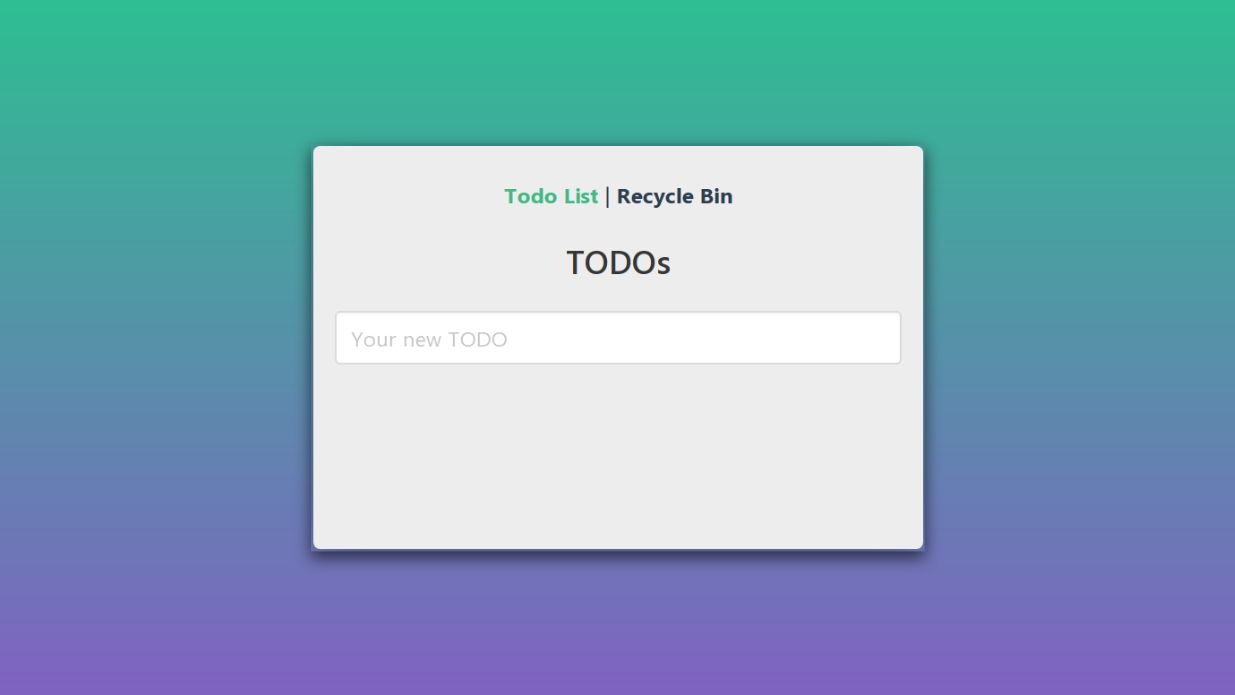
Let's take a look at the program from the dummy testing example again. In it, you can add new tasks, mark completed, delete and view the basket.
If we deal with decomposition, we will see that the interface is not a single monolith, it also consists of separate elements:
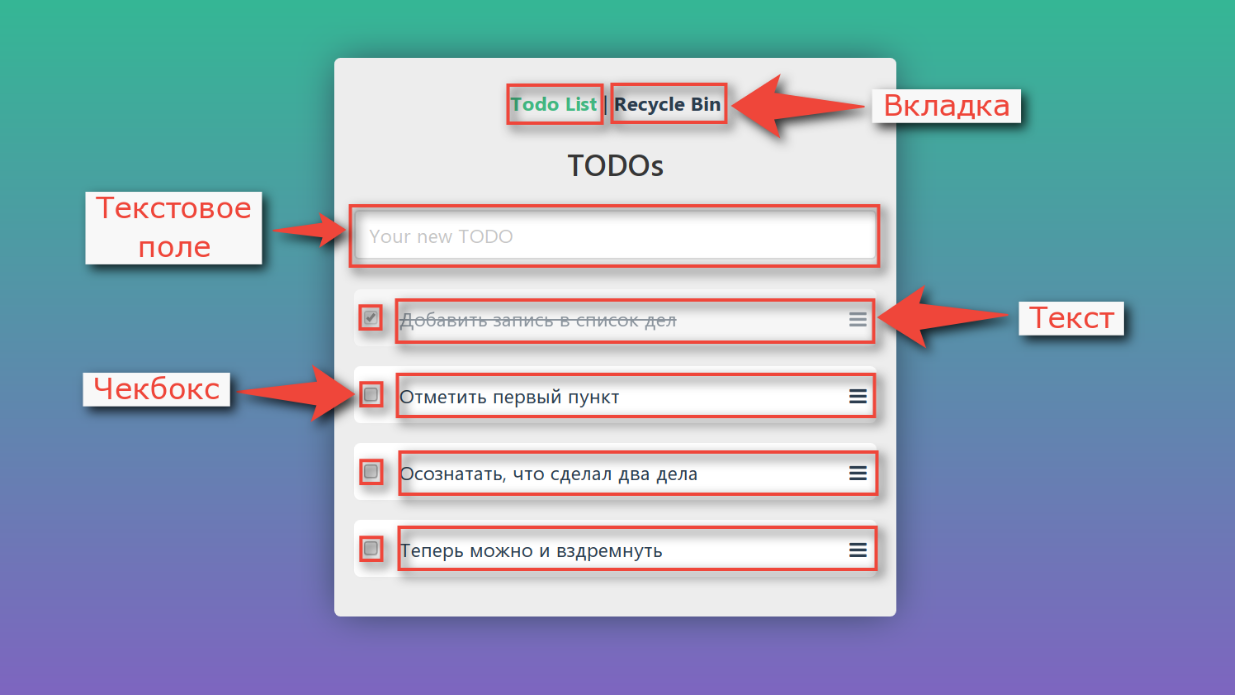
There is not much we can do with each of the controls. We have a mouse with two buttons, a wheel and a keyboard. You can click on an element, move the mouse cursor over it, you can enter text into text fields.
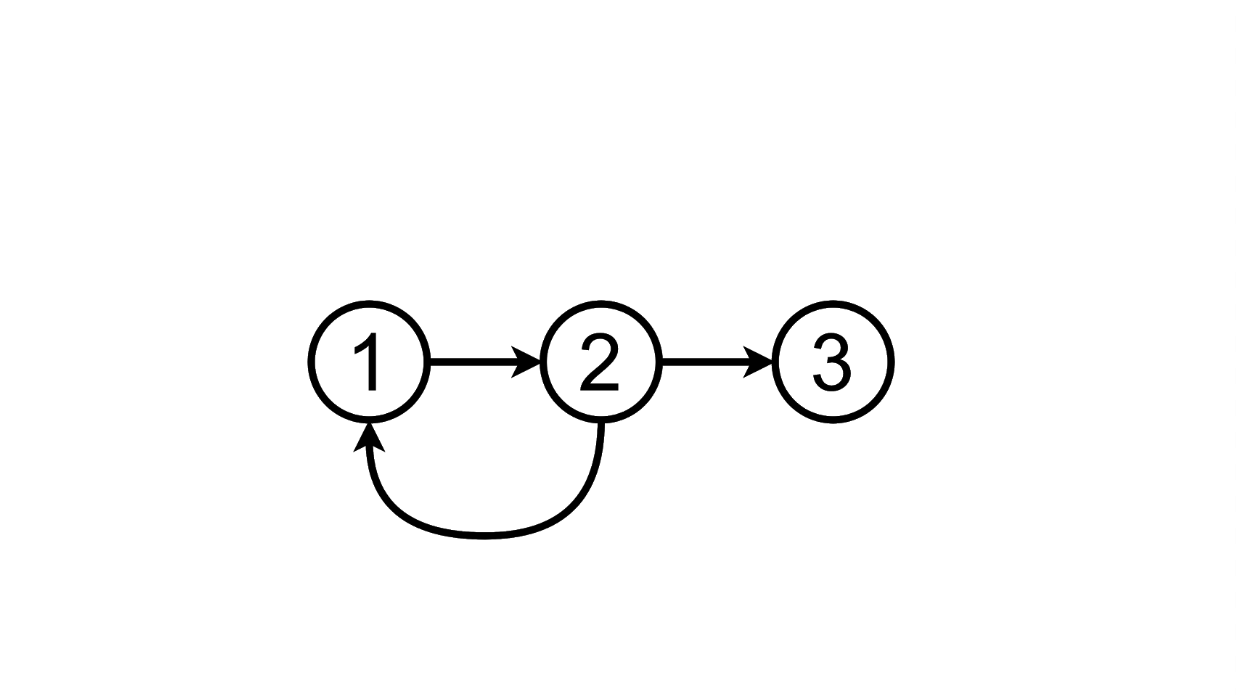
If we enter some text in the text field and press Enter, then our page will go from one state to another:
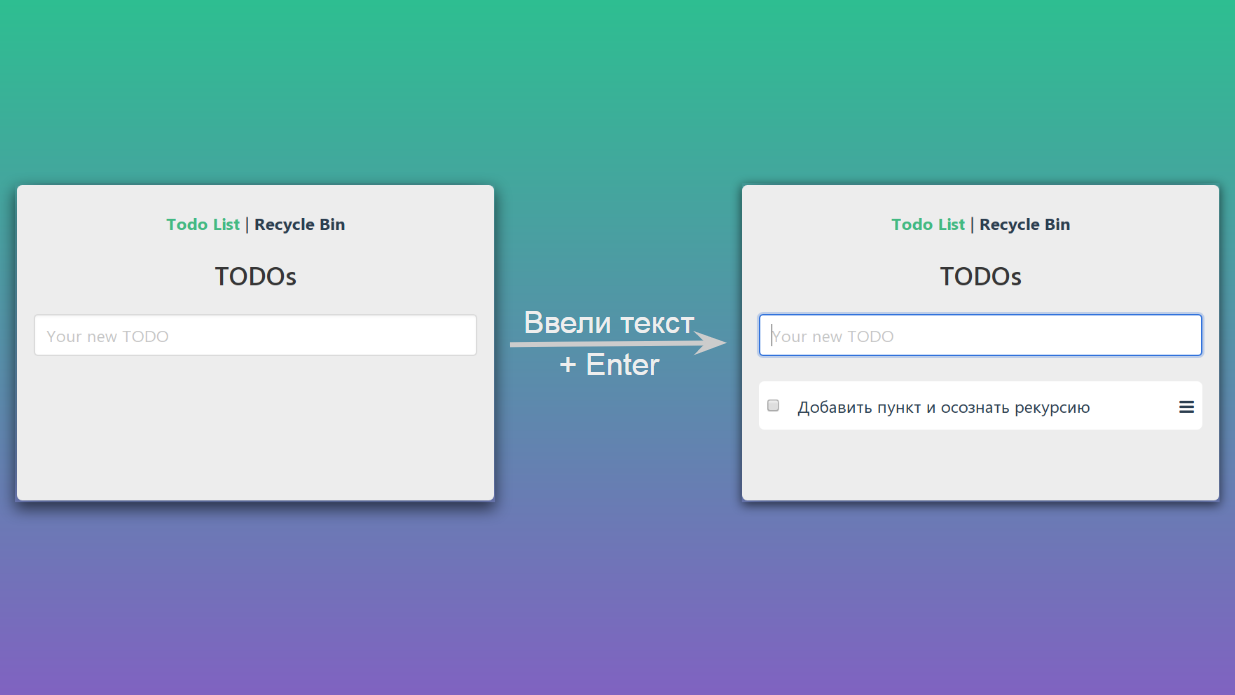
Schematically, it can be depicted like this:

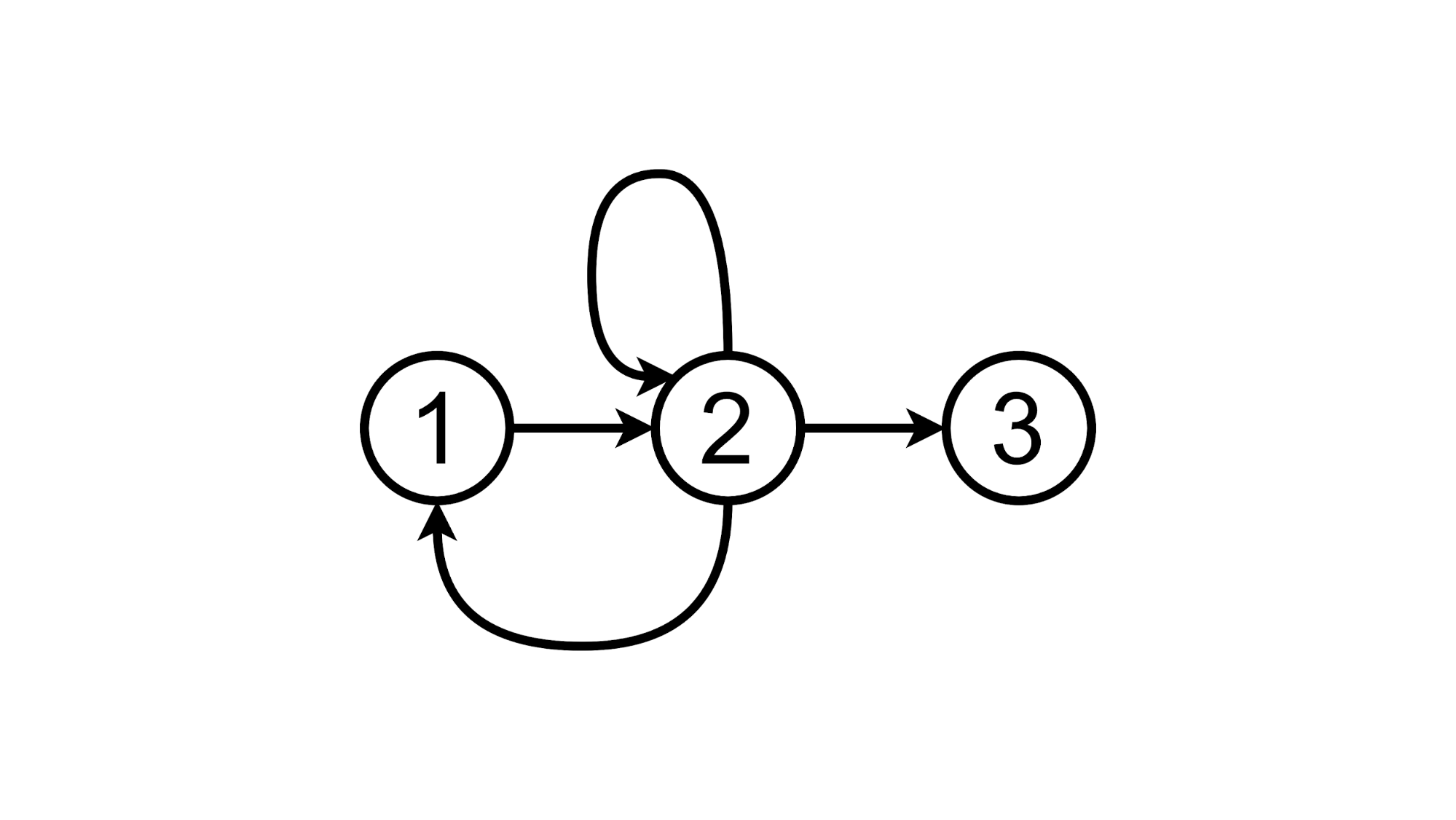
From this state, we can go to the third by adding another task to the list:
And we can delete the added task, returning to the first state:
Or click on the TODOs label and stay in the second state:
And now let's try to implement the Proof-of-Concept of this approach.

To work with the browser, we will take a chromedriver, we will work with the state diagram and transitions through the NetworkX python library, and we will draw through yEd.

We launch the browser, create a graph instance, in which there can be many connections with different directions between two vertices. And we open our application.

Now we must describe the state of the application. Due to the image compression algorithm, we can use the size of the PNG image as a state identifier and, through the __eq__ method, implement a comparison of this state with others. Through the iterated attribute, we fix that all buttons have been clicked, values have been entered into all fields in this state, in order to exclude reprocessing.

We write a basic algorithm that will bypass the entire application. Here we fix the first state in the graph, in the loop we click all the elements in this state and fix the resulting states. Next, select the next unprocessed state and repeat the steps.

When fuzzing the current state, we must each time return to this state from a new one. To do this, we use the nx.shortest_path function, which will return a list of elements that need to be clicked to go from the base state to the current one.
In order to wait for the end of the application's response to our actions, the wait function uses the Network Long Task API, showing whether JS is busy with any work.
Let's go back to our application. The initial state is as follows:
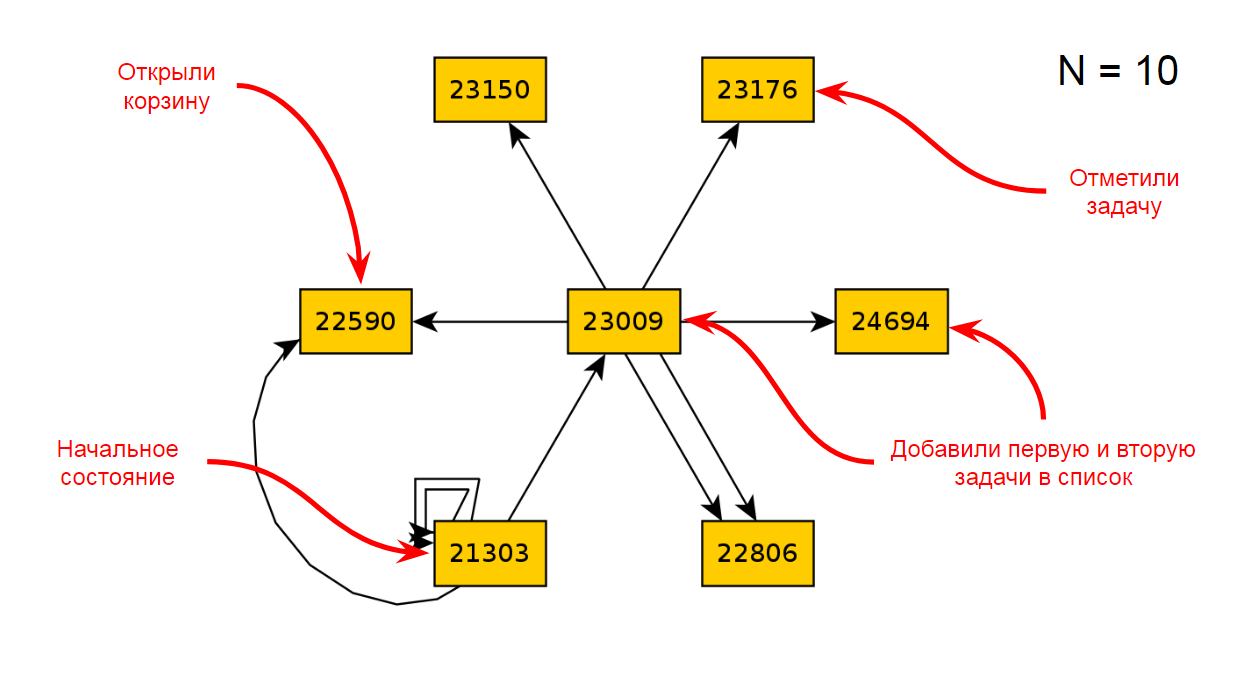
After ten iterations of the application, we will get the following diagram of states and transitions:
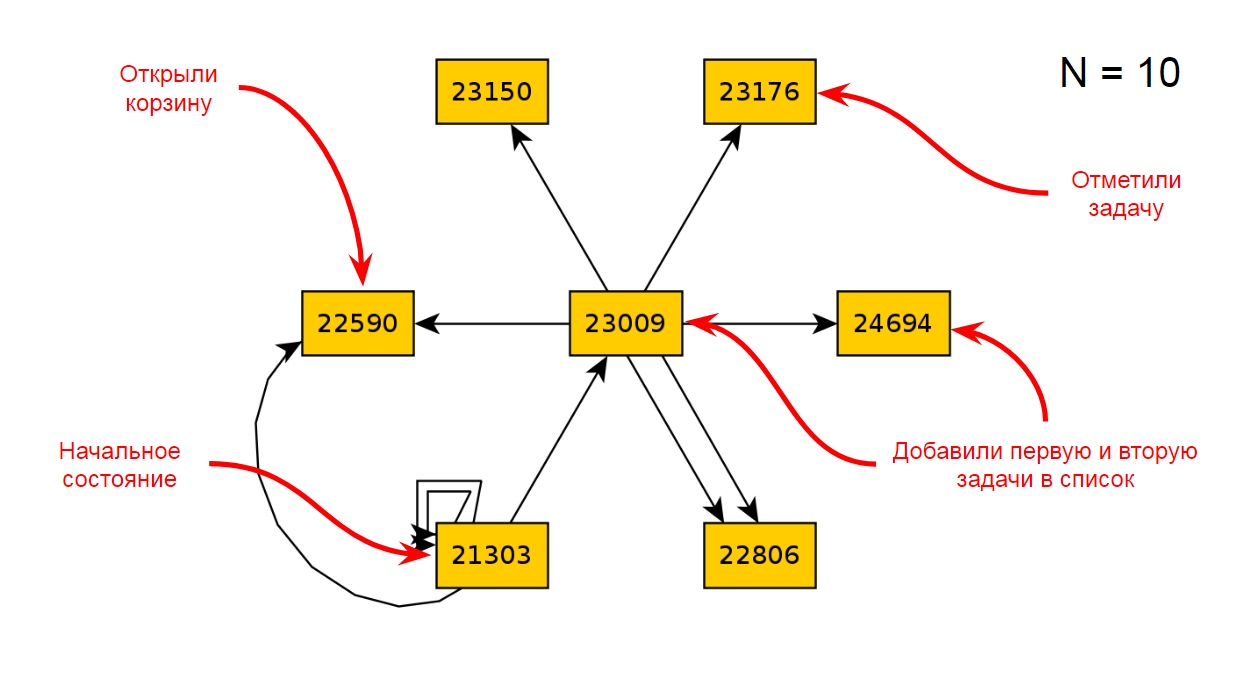
After 22 iterations, this is the following:
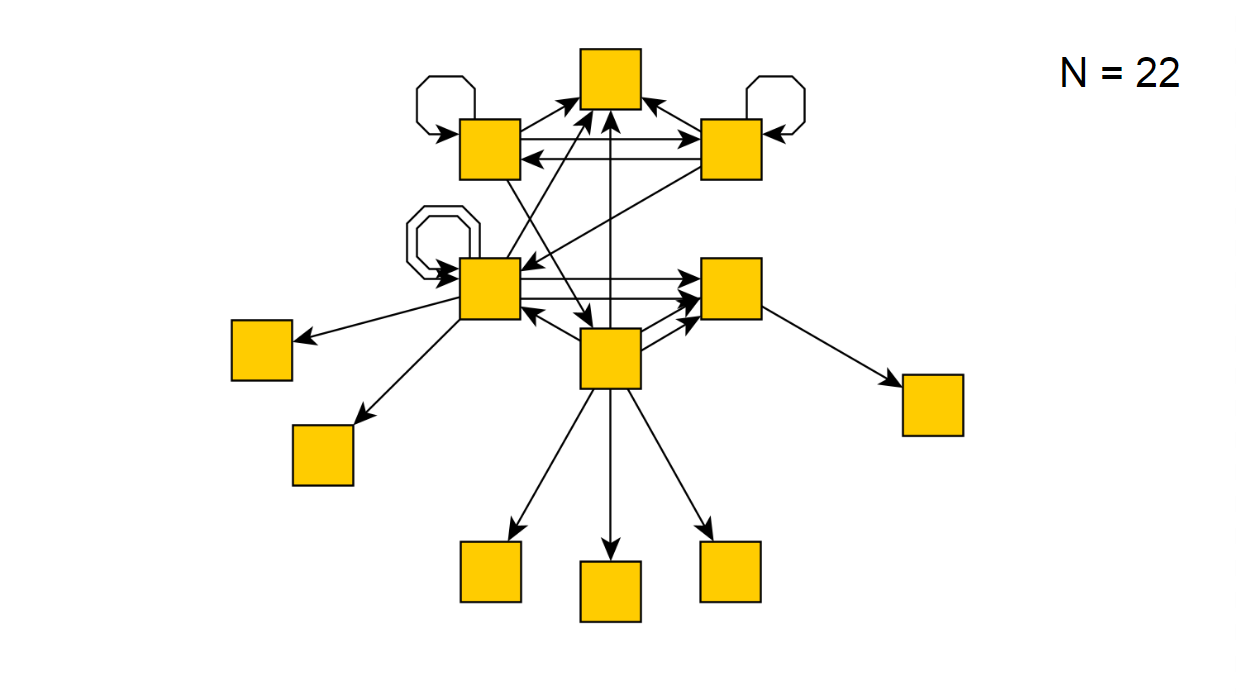
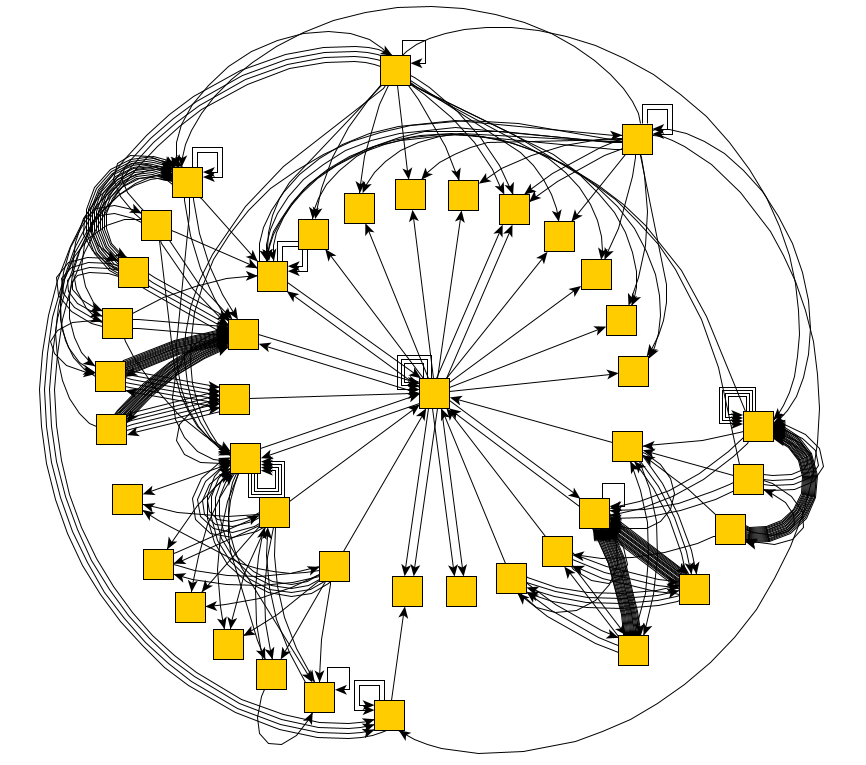
If we run our script for several hours, then it will suddenly report that it has bypassed all possible states, receiving the following diagram:

So, with a simple demo application we did it. And what happens if you set this script on a real web application. And there will be chaos:
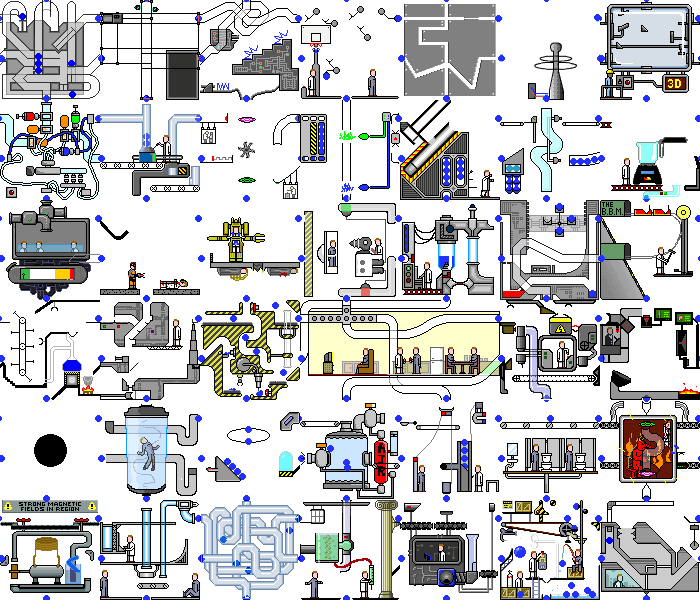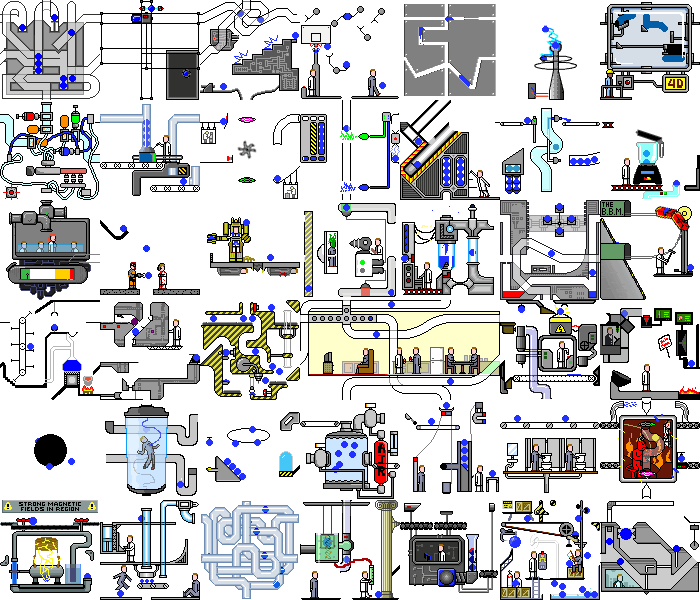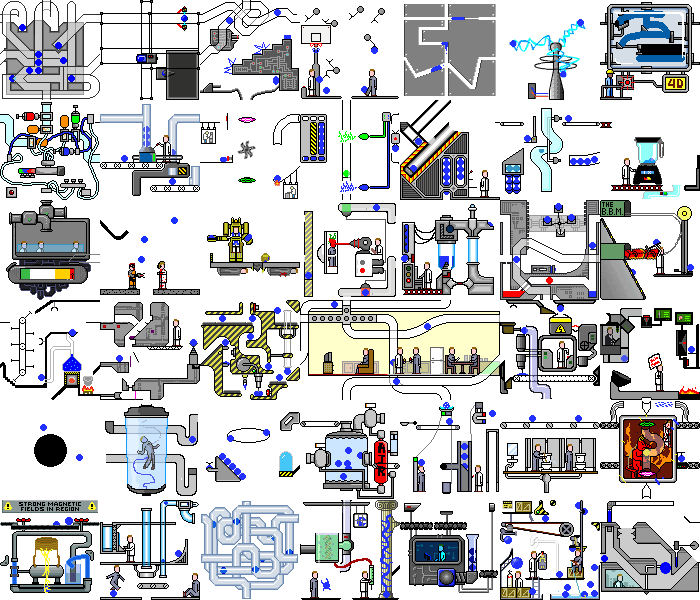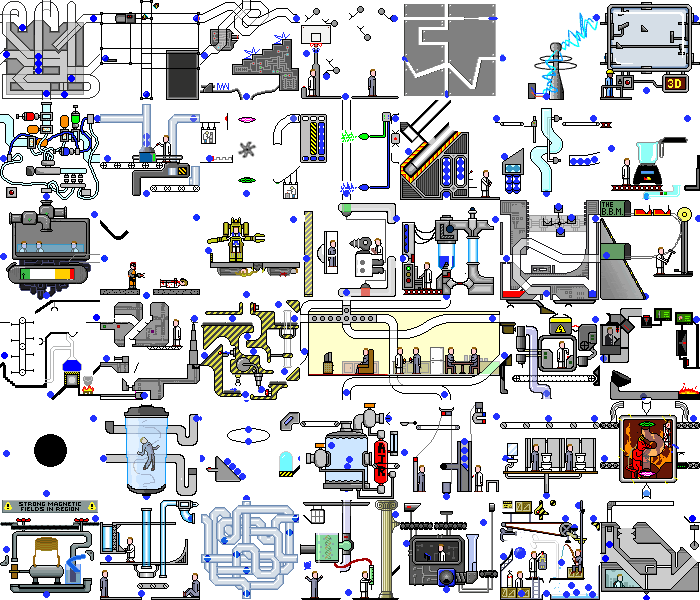
Not only do changes occur on the backend, the page itself is constantly redrawn when reacting to timers or events, when performing the same actions, we can get different states. But even in such applications, you can find pieces of functionality that our script can handle without significant modifications.
Take for testingVLSI authentication page :

And for it, it quickly enough turned out to build a complete state and transition diagram:

Excellent! We can now traverse all the states of the application. And purely in theory, find all the errors that depend on the actions. But how do you teach a program to understand that there is an error before it?
In testing, the program's responses are always compared with a certain standard called an oracle. They can be technical specifications, mock-ups, program analogues, previous versions, tester experience, formal requirements, test cases, etc. We can also use some of these oracles in our tool.

Let's consider the last pattern “it was different before”. Autotests are engaged in regression testing.
Let's go back to the graph after 10 iterations of TODO:
Let's break the code that is responsible for opening the shopping cart and run 10 iterations again:
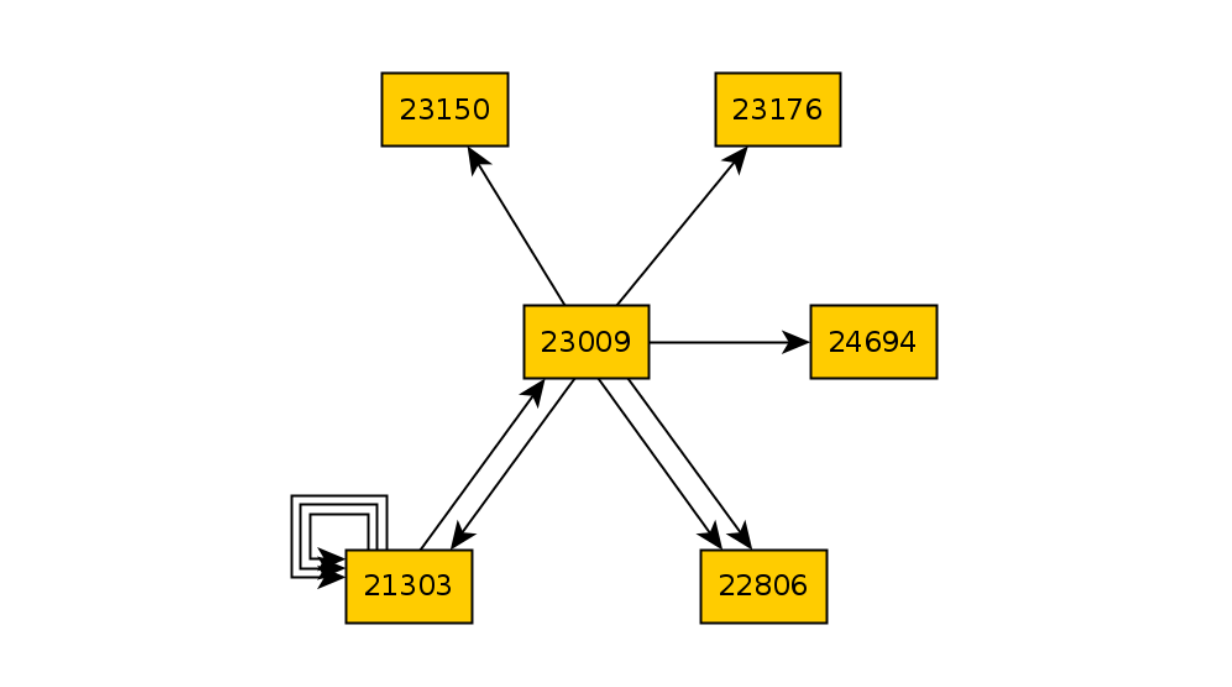
And then we compare the two graphs and find the difference in states:
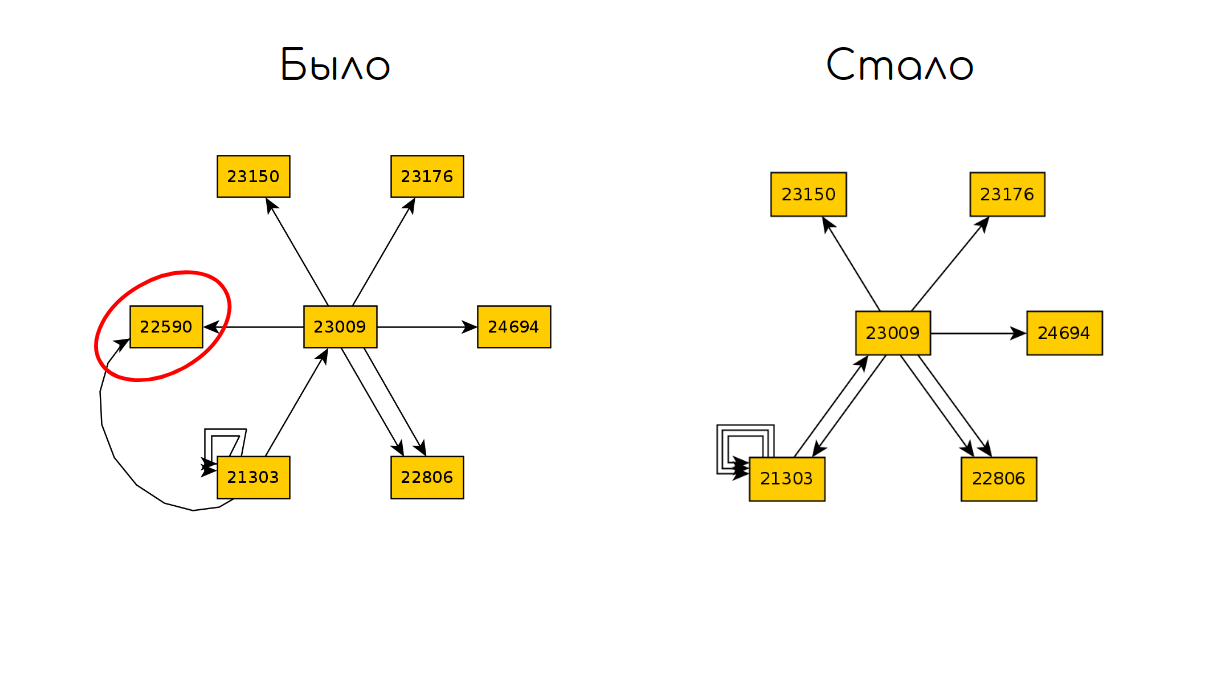
We can summarize for this approach:

As it stands, this technique can be used to test a small application and identify obvious or regression errors. For the technique to take off for large applications with unstable GUIs, significant improvements will be required.
All source code and a list of used materials can be found in the repository: https://github.com/svdokuchaev/venom . For those who want to understand the use of fuzzing in testing, I highly recommend The Fuzzing Book . There, in one of the parts, the same approach to fuzzing simple html forms is described .
