Prolog
Let's start with logic programming and the Prolog language. Knowledge about the subject area is presented in it as a set of facts and rules. Facts describe immediate knowledge. The facts about customers (ID, name and email address) and invoices (account ID, customer, date, amount due and paid amount) from the example from the previous post would look like this
client(1, "John", "john@somewhere.net").
bill(1, 1,"2020-01", 100, 50).Rules describe abstract knowledge that can be inferred from other rules and facts. The rule consists of a head and a body. In the head of the rule, you need to specify its name and a list of arguments. The body of a rule is a list of predicates connected by logical operations AND (specified by a comma) and OR (specified by a semicolon). Predicates can be facts, rules, or built-in predicates, such as comparison operations, arithmetic operations, etc. The relationship between the arguments of the rule head and the arguments of the predicates in its body is set using boolean variables - if the same variable is in the positions of two different arguments, This means that these arguments are identical. A rule is considered true when the logical expression of the rule body is true. The domain model can be defined as a set of referencing rules:
unpaidBill(BillId, ClientId, Date, AmoutToPay, AmountPaid) :- bill(BillId, ClientId, Date, AmoutToPay, AmountPaid), AmoutToPay < AmountPaid.
debtor(ClientId, Name, Email) :- client(ClientId, Name, Email), unpaidBill(BillId, ClientId, _, _, _).We have set two rules. In the first, we assert that all invoices that have less than the amount payable are unpaid invoices. In the second, the debtor is a client who has at least one unpaid invoice.
The syntax of Prolog is very simple: the main element of the program is the rule, the main elements of the rule are predicates, logical operations and variables. In the rule, attention is focused on variables - they play the role of an object of the modeled world, and predicates describe their properties and the relationship between them. In the definition of the debtor rule, we state that if the ClientId, Name, and Email objects are related by a client and unpaidBill relationship, then they will also be related by a debtor relationship. Prolog comes in handy when a problem is formulated as a set of rules, statements or logical statements. For example, when working with natural language grammar, compilers, in expert systems, when analyzing complex systems such as computers, computer networks, infrastructure objects. Complex,convoluted rule systems are best described explicitly and left to the Prolog runtime to deal with them automatically.
Prolog is based on first order logic (with some elements of higher order logic included). Inference is performed using a procedure called SLD resolution (Selective Linear Definite clause resolution). Simplified, its algorithm is a tree traversal of all possible solutions. The inference procedure finds all solutions for the first predicate of the rule body. If the current predicate in the knowledge base is represented only by facts, then the solutions are those that correspond to the current bindings of variables to values. If by rules, then recursive checking of their nested predicates is required. If no solutions are found, then the current search branch fails. Then a new branch is created for each partial solution found. In each branch, the inference procedure binds the found values to variables,included in the current predicate, and recursively searches for a solution for the remaining list of predicates. The work ends when the end of the predicate list is reached. The search for a solution can enter an endless loop in the case of recursive definition of rules. The result of the search procedure is a list of all possible bindings of values to boolean variables.
In the example above for the debtor rule, the resolution rule will first find one solution for the client predicate and associate it with booleans: ClientId = 1, Name = "John", Email = "john@somewhere.net". Then, for this variant of variable values, a solution will be performed for the next predicate unpaidBill. To do this, you first need to find solutions for the predicate bill, provided that ClientId = 1. The result will be bindings for the variables BillId = 1, Date = "2020-01", AmoutToPay = 100, AmountPaid = 50. At the end, AmoutToPay <AmountPaid will be checked in the built-in comparison predicate.
Semantic networks
Semantic networks are one of the most popular ways to represent knowledge. The Semantic Web is an information model of a subject area in the form of a directed graph. The vertices of the graph correspond to the concepts of the domain, and the arcs define the relations between them.
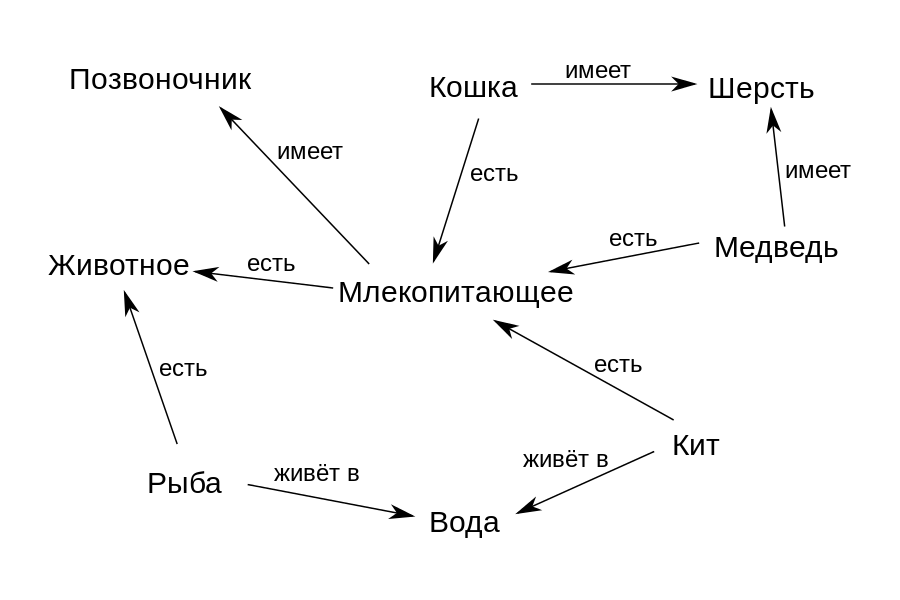
For example, according to the graph in the figure above, the concept of "Whale" is associated with the relationship "is" ("is") with the concept of "Mammal" and "lives in" with the concept of "Water". Thus, we can formally set the structure of the subject area - what concepts it includes and how they are related to each other. And then such a graph can be used to find answers to questions and derive new knowledge from it. For example, we can deduce the knowledge that "Whale" "has" "Spine" if we decide that the relationship "is" denotes a class-subclass relationship, and the subclass "Whale" should inherit all the properties of its class "Mammal".
RDF
The semantic web is an attempt to build a global semantic network based on the resources of the World Wide Web by standardizing the presentation of information in a form suitable for machine processing. For this, information is additionally embedded in HTML pages in the form of special attributes of HTML tags, which allows describing the meaning of their content in the form of an ontology - a set of facts, abstract concepts and relationships between them.
The standard approach for describing the semantic model of WEB resources is RDF (Resource Description Framework or Resource Description Framework). According to it, all statements must have the form of a triplet "subject - predicate - object". For example, knowledge about the concept of "Whale" will be presented as follows: "Whale" is a subject, "lives in" - a predicate, "Water" - an object. The whole set of such statements can be described using a directed graph, subjects and objects are its vertices, and predicates are arcs, predicate arcs are directed from objects to subjects. For example, the ontology from the animal example can be described as follows:
@prefix : <...some URL...>
@prefix rdf: <http://www.w3.org/1999/02/rdf-schema#>
@prefix rdfs: <http://www.w3.org/2000/01/22-rdf-syntax-ns#>
:Whale rdf:type :Mammal;
:livesIn :Water.
:Fish rdf:type :Animal;
:livesIn :Water.This notation is called Turtle and is intended to be human readable. But the same can be written in XML, JSON formats or using tags and attributes of an HTML document. Although in Turtle notation predicates and objects can be grouped together by subject for readability, at the semantic level each triplet is independent.
RDF is useful in cases where the data model is complex and contains a large number of object types and relationships between them. For example, Wikipedia provides access to the content of its articles in RDF format. The facts described in the articles are structured, their properties and relationships are described, including facts from other articles.
RDFS
An RDF model is a graph; by default, no additional semantics are included in it. Everyone can interpret the links in the graph as they see fit. You can add some standard links to it using RDF Schema - a set of classes and properties for building ontologies on top of RDF. RDFS allows you to describe standard relationships between concepts, such as the belonging of a resource to a certain class, the hierarchy between classes, the hierarchy of properties, and to restrict the possible types of subject and object.
For example, the statement
:Mammal rdfs:subClassOf :Animal.specifies that "Mammal" is a subclass of the concept "Animal" and inherits all of its properties. Accordingly, the concept of "Whale" can also be attributed to the class "Animal". But for this it is necessary to point out that the concepts "Mammal" and "Animal" are classes:
:Animal rdf:type rdfs:Class.
:Mammal rdf:type rdfs:Class.Also, the predicate can be set constraints on the possible values of its subject and object.
Statement
:livesIn rdfs:range :Environment.indicates that the object of the relationship "lives in" must always be a resource belonging to the class "Environment". Therefore, we must add a statement that the concept of "Water" is a subclass of the concept of "Environment":
:Water rdf:type :Environment.
:Environment rdf:type rdfs:ClassRDFS allows you to describe the data schema - to enumerate classes, properties, set their hierarchy and restrictions on their values. And RDF is to fill this schema with concrete facts and define the relationship between them. Now we can ask a question about this graph. This can be done in a special query language SPARQL, which resembles SQL:
SELECT ?creature
WHERE {
?creature rdf:type :Animal;
:livesIn :Water.
} This query will return us 2 values: "Whale" and "Fish".
An example from previous publications with accounts and customers can be implemented approximately as follows. With RDF, you can describe a data schema and fill it with values:
:Client1 :name "John";
:email "john@somewhere.net".
:Client2 :name "Mary";
:email "mary@somewhere.net".
:Bill_1 :client :Client1;
:date "2020-01";
:amountToPay 100;
:amountPaid 50.
:Bill_2 :client :Client2;
:date "2020-01";
:amountToPay 80;
:amountPaid 80.But abstract concepts such as "Debtor" and "Unpaid Bills" from the first article in this series include arithmetic operations and comparison. They do not fit into the static structure of the semantic network of concepts. These concepts can be expressed using SPARQL queries:
SELECT ?clientName ?clientEmail ?billDate ?amountToPay ?amountPaid
WHERE {
?client :name ?clientName;
:email ?clientEmail.
?bill :client ?client;
:date ?billDate;
:amountToPay ?amountToPay;
:amountPaid ?amountPaid.
FILTER(?amountToPay > ?amountPaid).
}The WHERE clause is a list of triple patterns and filter conditions. Boolean variables can be substituted into triplets, the name of which begins with the "?" The task of the query executor is to find all possible values of the variables for which all triplet patterns would be contained in the graph and the filtering conditions would be satisfied.
Unlike Prolog, where rules can be used to construct other rules, in RDF a query is not part of the Semantic Web. A request cannot be referenced as a data source for another request. True, SPARQL has the ability to represent query results as a graph. So you can try to combine the query results with the original graph and run the new query on the combined graph. But such a decision would clearly go beyond the ideology of RDF.
OWL
An important component of Semantic Web technologies is OWL (Web Ontology Language) - a language for describing ontologies. With the RDFS vocabulary, you can express only the most basic relationships between concepts — the hierarchy of classes and relationships. OWL offers a much richer vocabulary. For example, you can specify that two classes (or two entities) are equivalent (or different). This task is often encountered when combining ontologies.
You can create composite classes based on the intersection, union, or complement of other classes:
- When intersected, all instances of a composite class must also apply to all source classes. For example, "Marine Mammal" must be both "Mammal" and "Sea Dweller" at the same time.
- . , , «» «», «» «». «».
- , . , «» «».
- . , .
- — , .
Such expressions that allow you to link concepts together are called constructors.
OWL also allows you to set many important relationship properties:
- Transitivity. If the relations P (x, y) and P (y, z) hold, then the relation P (x, z) is also satisfied. Examples of such relationships are "More" - "Less", "Parent" - "Child", etc.
- Symmetry. If the relation P (x, y) is satisfied, then the relation P (y, x) is also fulfilled. For example, a Relative relationship.
- Functional dependence. If the relations P (x, y) and P (x, z) hold, then the values of y and z must be identical. An example is the Father relationship - a person cannot have two different fathers.
- Inversion of relations. You can specify that if the relation P1 (x, y) is satisfied, then one more relation P2 (y, x) must be fulfilled. An example of such a relationship is the parent-child relationship.
- Chains of relationships. You can set that if A is associated with some property with B, and B - with C, then A (or C) belongs to the given class. For example, if A has a father to B, and father B has his father C, then A is C.'s grandson.
You can also set restrictions on the values of the arguments of relations. For example, specify that arguments must always belong to a certain class, or that a class must have at least one relationship of a given type, or limit the number of relationships of this type for it. Or you can specify that all instances that are related by a given relationship to a given value belong to a particular class.
OWL is now the de facto standard tool for building ontologies. This language is better suited for building large and complex ontologies than RDFS. OWL syntax allows you to express more different properties of concepts and the relationships between them. But it also introduces a number of additional restrictions, for example, the same concept cannot be simultaneously declared both as a class and as an instance of another class. OWL ontologies are stricter, more standardized, and therefore more readable. If RDFS is just a few additional classes on top of an RDF graph, then OWL has a different mathematical basis - description logic. Accordingly, formal inference procedures become available, allowing you to extract new information from OWL ontologies, check their consistency and answer questions.
Descriptive logic is a piece of first-order logic. Only one-place predicates (for example, a concept belongs to a class), two-place predicates (a concept has a property and its value), as well as class constructors and relationship properties, listed above, are allowed in it. All other expressions of first-order logic in descriptive logic have been dropped. For example, the statements that the concept of "Unpaid invoice" belongs to the class "Invoice", the concept of "Invoice" has the properties "Amount to be paid" and "Amount paid" will be acceptable. But to make a statement that the concept of "Unpaid invoice" property "Amount to be paid" should be greater than the property "Amount paid" will not work. This requires a rule that includes a predicate for comparing these properties. Unfortunately,the OWL constructors don't allow this.
Thus, the expressiveness of descriptive logic is lower than that of first-order logic. But on the other hand, inference algorithms in descriptive logic are much faster. In addition, it possesses the property of decidability - the solution can be found guaranteed in a finite time. It is believed that in practice such a vocabulary is quite enough for building complex and voluminous ontologies, and OWL is a good compromise between expressiveness and inference efficiency.
Also worth mentioning is SWRL (Semantic Web Rule Language), which combines the ability to create classes and properties in OWL with writing rules in a limited version of the Datalog language. The style of these rules is the same as in Prolog. SWRL supports built-in predicates for comparison, math, string, date, and list manipulation. This is exactly what we lacked in order to implement the concept of "Unpaid invoice" with the help of one simple expression.
Flora-2
As an alternative to semantic networks, consider a technology such as frames. A frame is a structure that describes a complex object, an abstract image, a model of something. It consists of a name, a set of properties (characteristics) and their values. The property value can be another frame. Also, the property can have a default value. A function for calculating its value can be attached to a property. A frame can also include service procedures, including handlers for such events, such as creating, deleting a frame, changing the value of properties, etc. An important property of frames is the ability to inherit. The child frame includes all the properties of the parent frames.
The system of linked frames forms a semantic network very similar to an RDF graph. But in the tasks of creating ontologies, frames were supplanted by OWL, which is now the de facto standard. OWL is more expressive, has a more advanced theoretical basis - formal descriptive logic. Unlike RDF and OWL, in which the properties of concepts are described independently of each other, in the frame model, the concept and its properties are considered as a single whole - a frame. If in RDF and OWL models, the vertices of the graph contain the names of concepts, and the edges contain their properties, then in the frame model, the vertices of the graph contain concepts with all their properties, and the edges contain connections between their properties or inheritance relations between concepts.
In this, the frame model is very close to the object-oriented programming model. They are largely the same, but have a different scope - frames are aimed at modeling a network of concepts and relationships between them, and OOP - at modeling the behavior of objects, their interaction with each other. Therefore, OOP provides additional mechanisms for hiding the implementation details of one component from others, restricting access to methods and fields of a class.
Modern framing languages (such as KL-ONE, PowerLoom, Flora-2) combine the composite data types of the object model with first-order logic. In these languages, you can not only describe the structure of objects, but also operate with these objects in rules, create rules describing the conditions for an object to belong to a given class, etc. The mechanisms of inheritance and composition of classes receive a logical interpretation, which becomes available for use by inference procedures. These languages are more expressive than OWL and are not limited to two-place predicates.
As an example, let's try to implement our example with debtors in the Flora-2 language... This language includes 3 components: the F-logic frame logic, which combines frames and first-order logic, the higher-order logic HiLog, which provides tools for forming statements about the structure of other statements and meta-programming, and the Transactional Logic change logic, which allows in logical form describe data changes and side effects of computations. Now we are only interested in the F-logic frame logic . To begin with, we will use it to declare the structure of frames that describe the concepts (classes) of clients and debtors:
client[|name => \string,
email => \string
|].
bill[|client => client,
date => \string,
amountToPay => \number,
amountPaid => \number,
amountPaid -> 0
|].Now we can declare instances (objects) of these concepts:
client1 : client[name -> 'John', email -> 'john@somewhere.net'].
client2 : client[name -> 'Mary', email -> 'mary@somewhere.net'].
bill1 : bill[client -> client1,
date -> '2020-01',
amountToPay -> 100
].
bill2 : bill[client -> client2,
date -> '2020-01',
amountToPay -> 80,
amountPaid -> 80
].The '->' symbol means the association of an attribute with a specific value in an object and a default value in a class declaration. In our example, the amountPaid field of the bill class has a default value of zero. The ':' symbol means the creation of an entity of the class: client1 and client2 are entities of the client class.
Now we can declare that the concepts "Unpaid invoice" and "Debtor" are subclasses of the concepts "Account" and "Client":
unpaidBill :: bill.
debtor :: client.The symbol '::' declares an inheritance relationship between classes. The structure of the class is inherited, methods and default values for all its fields. It remains to declare the rules specifying the belonging to the unpaidBill and debtor classes:
?x : unpaidBill :- ?x : bill[amountToPay -> ?a, amountPaid -> ?b], ?a > ?b.
?x : debtor :- ?x : client, ?_ : unpaidBill[client -> ?x]. The first statement states that a variable
?is an unpaidBill entity if it is a bill entity and its amountToPay field is greater than amountPaid. In the second, what ?belongs to the unpaidBill class, if it belongs to the client class and there is at least one entity of the unpaidBill class in which the value of the client field is equal to a variable ?. This entity of the unpaidBill class will be associated with an anonymous variable ?_, the value of which is not used further.
You can get a list of debtors using the query:
?- ?x:debtor.We ask you to find all values related to the debtor class. The result will be a list of all possible values for the variable
?x:
?x = client1Frame logic combines the visibility of an object-oriented model with the power of logic programming. It will be convenient when working with databases, modeling complex systems, integrating disparate data - in those cases where you need to focus on the structure of concepts.
SQL
Finally, let's take a look at the main features of SQL syntax. In the last publication, we said that SQL has a logical theoretical basis - relational calculus, and considered the implementation of an example with debtors in LINQ. In terms of semantics, SQL is close to framing languages and OOP models - in a relational data model, the main element is a table, which is perceived as a whole, and not as a set of separate properties.
The SQL syntax fits perfectly with this table orientation. The request is split into sections. The entities of the model, which are represented by tables, views and nested queries, have been moved to the FROM section. Links between them are specified using JOIN operations. Dependencies between fields and other conditions are in the WHERE and HAVING clauses. Instead of boolean variables that bind predicate arguments, we operate on table fields directly in the query. This syntax describes the structure of the domain model more clearly than the “linear” Prolog syntax.
How I see the syntax style of the modeling language
Using the unpaid invoice example, we can compare approaches such as logic programming (Prolog), frame logic (Flora-2), semantic web technologies (RDFS, OWL, and SWRL), and relational calculus (SQL). I summarized their main characteristics in a table:
| Language | Mathematical basis | Style orientation | Scope of application |
|---|---|---|---|
| Prolog | First order logic | On the rules | Rule-based systems, pattern matching. |
| RDFS | Graph | On the connection between concepts | WEB resource data schema |
| OWL | Descriptive logic | On the connection between concepts | Ontologies |
| SWRL | A stripped-down version of Datalog's first-order logic | On rules on top of links between concepts | Ontologies |
| Flora-2 | Frames + first order logic | On rules on top of object structure | Databases, modeling complex systems, integrating disparate data |
| SQL | Relational calculus | On table structures | Database |
Now you need to find the mathematical basis and syntax style for a modeling language designed to work with semi-structured data and data integration from disparate sources, which would be combined with general-purpose object-oriented and functional programming languages.
The most expressive languages are Prolog and Flora-2 - they are based on full first-order logic with elements of higher-order logic. The rest of the approaches are subsets of it. Except for RDFS - it has nothing to do with formal logic at all. At this stage, full-fledged first-order logic seems to me the preferred option. To begin with, I plan to dwell on it. But the limited option in the form of a relational calculus or deductive database logic also has its advantages. It provides great performance when working with large amounts of data. It should be considered separately in the future. Descriptive logic seems too limited and incapable of expressing dynamic relationships between concepts.
From my point of view, for working with semi-structured data and integrating disparate data sources, frame logic is more suitable than rules-oriented Prolog, or OWL, which is oriented on links and concept classes. The frame model explicitly describes the structures of objects and focuses attention on them. In the case of objects with many properties, the frame form is much more readable than rules or subject-property-object triplets. Inheritance is also a very useful mechanism that can dramatically reduce the amount of repetitive code. Compared to the relational model, frame logic allows you to describe complex data structures such as trees and graphs in a more natural way. And the most important thing,the proximity of the frame model for describing knowledge to the OOP model will allow integrating them in one language in a natural way.
I want to borrow a query structure from SQL. The definition of a concept can have a complex form and it does not hurt to break it down into sections in order to emphasize its component parts and facilitate perception. Also, for most developers, the SQL syntax is pretty familiar.
So, I want to take frame logic as the basis of the modeling language. But since the goal is to describe data structures and integrate disparate data sources, I will try to abandon the rule-oriented syntax and replace it with a structured version borrowed from SQL. The main element of the domain model will be a "concept" (concept). In its definition, I want to include all the information needed to extract its entities from the source data:
- the name of the concept;
- a set of its attributes;
- () , ;
- , ;
- , .
The definition of the concept will resemble an SQL query. And the entire domain model will be in the form of interrelated concepts.
I plan to show the resulting syntax of the modeling language in the next publication. For those who want to get acquainted with it now, there is a full text in a scientific style in English, available here:
Hybrid Ontology-Oriented Programming for Semi-Structured Data Processing
Links to previous publications:
Designing a multi-paradigm programming language. Part 1 - What is it for?
We design a multi-paradigm programming language. Part 2 - Comparison of Model Building in PL / SQL, LINQ and GraphQL