Bob Steagall recently gave a talk at CppCon 2020 entitled “ Adventures in SIMD-thinking ”, where, among other things, he talked about his experience of using AVX512 for median filtering with window 7. This talk caused me two feelings: on the one hand, it's cool , and is claimed to be almost 20x faster than the dumbest STL implementation; on the other hand, in one pass of the algorithm from 16 input samples, it turned out only 2 outputs, although the input data was enough for 10, and some implementation details made me want to try to improve them. I thought, thought, and came up with an idea, then another, then tried them "in software" and realized that I had something to share :) So this article turned out.
Basic implementation
I will briefly describe how it was done by Bob (in fact, a short retelling of the corresponding part of his story, along with his own pictures). He made the following primitives using AVX512 (I will omit those of the primitives described by him that directly correspond to the only AVX512 operation):
rotate: rotate the elements in the AVX-512 register in a circle

shift with carry : shift items from a register, replacing items from a second register
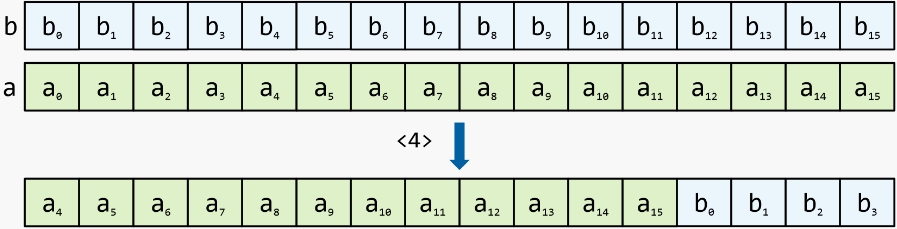
in place shift with carry : like shift with carry, but the input registers are passed by reference and the result of the shift remains in them
compare with exchange : parallel sorting up to 8 pairs of elements in a register

, , : perm 0..15, ; mask 1 «» . : , perm. vmin , vmax ́ . , .
, , . :
1) shift with carry, «» , «» (.. 0 0..6, 1 — 1..7 . .)
2) , 0 , 1 —
3) 7 , — 6 compare and exchange, . — — .
0
- , . , , ( , L2). , . AVX-512…
1
, — . 7 ; 6 !

, 6 r1-r6 , r0 r7? S[0..5], X, , S[3] .
X >= S[3], S[3] ,X <= S[2], S[2] S[3], S[2]S[2] < X < S[3], X S[3], , X. ,clamp(X, S[2], S[3])=>min(max(X, S[2]), S[3])!
:
«» 4 7- ( 0, 7, 2, 9) – X 4
6- 1..6 3..8 ( 0..7 8..15, )
6-
clamp 2 3 X[0] X[1], 2 3 X[2] X[3]
2x — 2 ( 6 5 , 7 — 6), clamp . : 1,86x . . ?
2
«» X . 6- ; 5 , 2 ( 3 ). — : S[0] <=> S[1], S[2] <=> S[3], S[4] <=> S[5]
2, . . , , !

— 2 , 2 . , : 1.06x. , .
3
- , 1, 6- .

, 4 ( ), 6; , 4- ?
2 , 4- . 6- : 2- Y 4- S, 2 3 ( Z). , min(Y[0], S[0]) => Z[0], ; max(Y[0], S[0]) Z[1]..Z[5] – . max(Y[1], S[3]) , min(Y[1], S[3]).
4- S[1], S[2], min/max. , 4 , 1 2 — 2 3 6- . , «» 4- S[1] S[2], — . , 2 , Y.
:
r1-r2 . .
— Y, r1-2, r5-6, r7-8, r11-12; permute 4 , Y r0-1, r4-5 . .
( ) «» ; r3-r6 r7-r10
max min Y[0]/S[0], Y[1]/S[3]
mask_permute Y S, S[1] S[2] ,
4
1 2, min/max X 8
, , , 2. — 1.64x , 2, 3 , .
; ( - permute; , - ), .
, :)
benchmark:
512 : 3.1-3.2 ; 7.3 , memcpy avx-512
50 : 2.8-2.9 ; 1.8 , memcpy (!)
.
5? , (disclaimer: — ).
16- 12 .
- 3 ( …)
1 , 4 ( 6 ) 4- — , . . 4 , 5 ; 8 .
2 , — 2 ; , .
3 , . , — , 12 . , «» — 24 , 12 .
9? 8 .
—
1 — 2 8- 4 , 4 ( 7 6 )
2 — , -
3 — , — 6- 2, 6- ( , ) , 8-.
, - . , https://github.com/tea/avx-median/. « », , -. , .
- , — . .
UPDATE
AVX2 . , , , , ( , 16 , ). , : 1.64x , .
It turned out that not everything is lost - the first optimization step can also be applied to this variant! You need to collect 32 edges of X, you need to muddle the data for sorting, the sorted data also needs to be permute, etc., but despite all these gestures, we got an acceleration of 1.27x.
I did not try to do steps 2 and 3, because it will obviously be slower. It is quite possible that for the case with, say, window 11, they will work in a plus (but I don't know if someone needs a fast 1D-median filter with large windows).