To generate the required report with a specified frequency, it is enough to write a corresponding custom Report resource.
Usage scenarios
Custom Metering reports are needed, for example, in the following cases:
- OpenShift, , (worker nodes) . . CPU , , -, , .
- OpenShift. Metering, , , , . , , , .
- In addition, in a situation with public clusters, the operations department would be useful to be able to keep records in the context of teams and departments by the total operating time of their pods (or by how much CPU or memory resources were spent on it). In other words, we are again interested in information about who owns this or that sub.
To solve these problems in the cluster, it is enough to create certain custom resources, which we will do next. Installing the Metering operator is beyond the scope of this article, so referring to the installation documentation if necessary . You can learn more about how to use the standard Metering reports in the related documentation .
How Metering works
Before creating custom assets, let's take a look at Metering a bit. Once installed, it creates six types of custom resources, of which we will focus on the following:
- ReportDataSources (RDS) - This mechanism allows you to specify what data is available and can be used in ReportQuery or custom Report resources. RDS also allows you to extract data from multiple sources. In OpenShift, data is pulled from Prometheus as well as custom ReportQuery (RQ) resources.
- ReportQuery (rq) – SQL- , RDS. RQ- Report, RQ- , . RQ- RDS-, RQ- Metering view Presto ( Metering) .
- Report – , , ReportQuery. , , , Metering. Report .
Lots of RDS and RQ are available out of the box. Since we are primarily interested in node-level reports, let's look at those of them that will help you write your custom queries. Run the following command while in the "openshift-metering" project:
$ oc project openshift-metering
$ oc get reportdatasources | grep node
node-allocatable-cpu-cores
node-allocatable-memory-bytes
node-capacity-cpu-cores
node-capacity-memory-bytes
node-cpu-allocatable-raw
node-cpu-capacity-raw
node-memory-allocatable-raw
node-memory-capacity-raw
Here we are interested in two RDS: node-capacity-cpu-core and node-capput-capacity - capacity-raw, since we want to get a report on CPU consumption. Let's start with node-capacity-cpu-core and run the following command to see how it collects data from Prometheus:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml
<showing only relevant snippet below>
spec:
prometheusMetricsImporter:
query: |
kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)
Here we see a Prometheus request that fetches data from Prometheus and stores it in Presto. Let's execute the same request in the OpenShift metrics console and see the result. We have an OpenShift cluster with two worker nodes (each with 16 cores) and three master nodes (each with 8 cores). The last column, Value, contains the number of cores assigned to the node.

So, the data is received and stored in Presto tables. Now let's see the reportquery (RQ) custom resources:
$ oc project openshift-metering
$ oc get reportqueries | grep node-cpu
node-cpu-allocatable
node-cpu-allocatable-raw
node-cpu-capacity
node-cpu-capacity-raw
node-cpu-utilization
Here we are interested in the following RQS: node-cpu-capacity and node-cpu-capacity-raw. As the name suggests, these metrics contain both descriptive data (how long a node is running, how many processors it has allocated, etc.) and aggregated data.
The two RDS and two RQS we are interested in are interconnected by the following chain:
node-cpu-capacity (rq) <b>uses</b> node-cpu-capacity-raw (rds) <b>uses</b> node-cpu-capacity-raw (rq) <b>uses</b> node-capacity-cpu-cores (rds)
Customizable Reports
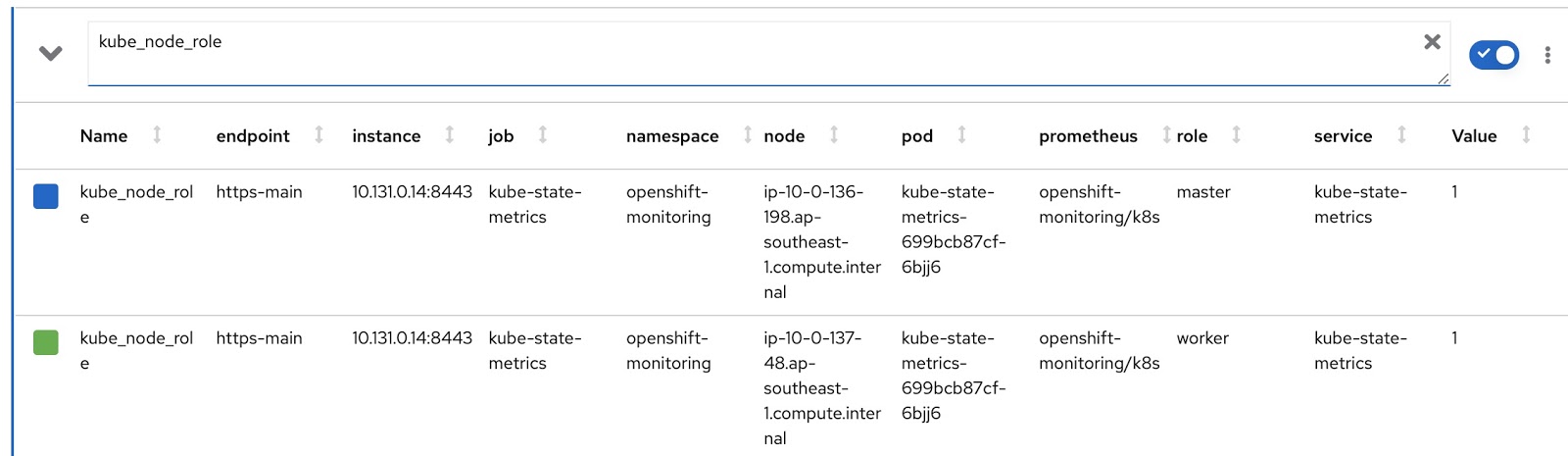
Now let's write our own customized versions of RDS and RQ. We need to change the Prometheus request so that it displays the mode of the node (master / worker) and the corresponding node label, which indicates which team this node belongs to. The node operation mode is contained in the kube_node_role Prometheus metric, see the role column:
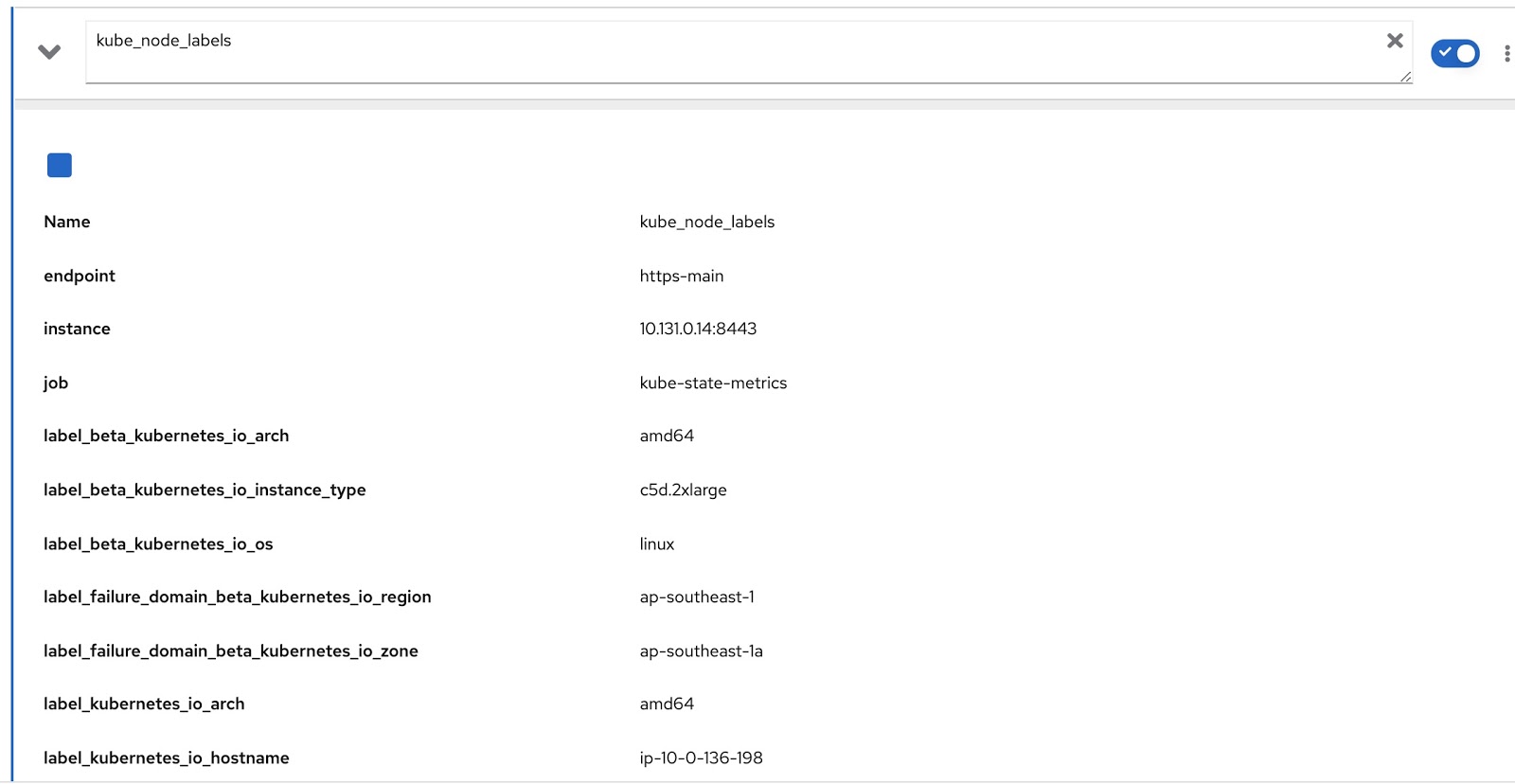
And all the labels assigned to the node are contained in the Prometheus metric kube_node_labels, where they are formed using the label_ template. for example, if a node has a label node_lob, then in the Prometheus metric it will be displayed as label_node_lob.
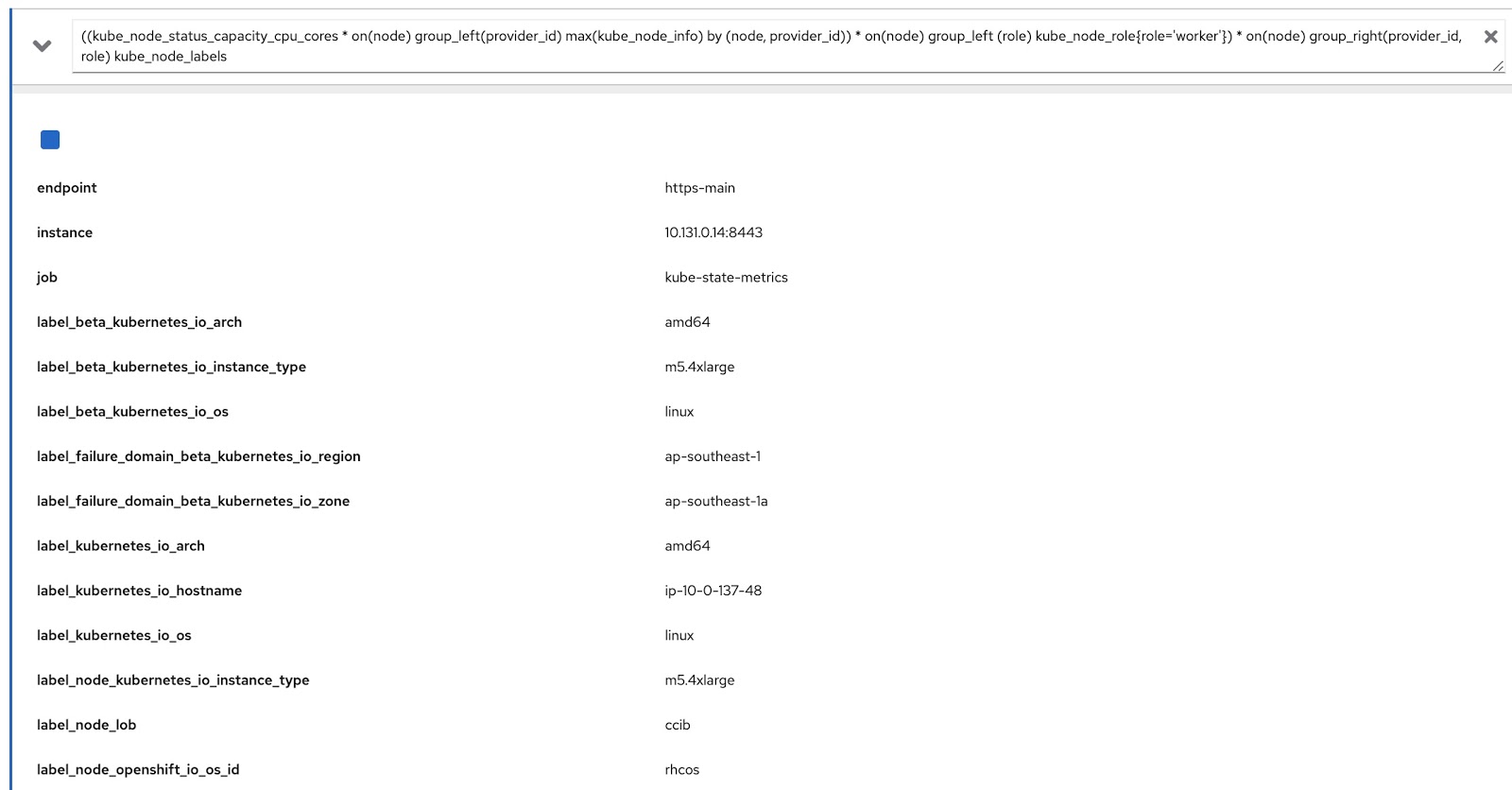
Now we just have to modify the original query with these two Prometheus queries to get the data we need, like this:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
Now let's run this query in the OpenShift metrics console and make sure that it returns data both by labels (node_lob) and by roles. In the picture below, this is, firstly, label_node_lob, as well as the role (it is there, it just did not appear on the screenshot):
So, we need to write four custom resources (you can download them from the list below):
- rds-custom-node-capacity-cpu-cores.yaml - Specifies a Prometheus request.
- rq-custom-node-cpu-capacity-raw.yaml - refers to the request from step 1 and outputs raw data.
- rds-custom-node-cpu-capacity-raw.yaml - refers to RQ from step 2 and creates a view object in Presto.
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml - refers to RDS from clause 3 and outputs data taking into account the entered start and end dates of the report. In addition, the role and label columns are extracted to the same file.
Having created these four yaml files, go to the openshift-metering project and execute the following commands:
$ oc project openshift-metering
$ oc create -f rds-custom-node-capacity-cpu-cores.yaml
$ oc create -f rq-custom-node-cpu-capacity-raw.yaml
$ oc create -f rds-custom-node-cpu-capacity-raw.yaml
$ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml
Now it remains only to write a custom Report object that will refer to the RQ object from step 4. For example, you can do this as shown below so that the report runs immediately and returns data from September 15th to 30th.
$ cat report_immediate.yaml
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: custom-role-node-cpu-capacity-lables-immediate
namespace: openshift-metering
spec:
query: custom-role-node-cpu-capacity-labels
reportingStart: "2020-09-15T00:00:00Z"
reportingEnd: "2020-09-30T00:00:00Z"
runImmediately: true
$ oc create -f report-immediate.yaml
After executing this report, the result file (csv or json) can be downloaded from the following URL (just replace DOMAIN_NAME with your own):
metering-openshift-metering.DOMAIN_NAME / api / v1 / reports / get? Name = custom-role-node-cpu- capacity-hourly & namespace = openshift-metering & format = csv
As you can see in the screenshot of the CSV file, it contains both role and node_lob. To get the node's uptime in seconds, divide node_capacity_cpu_core_seconds by node_capacity_cpu_cores:

Conclusion
The Metering operator is a cool thing for OpenShift clusters deployed anywhere. By providing an extensible framework, it allows you to create custom resources to generate the reports you want. All source codes used in this article can be downloaded here .