Starting an example
Below we will write a simple application in java (the author used java 14, but java 8 is fine too), measure its performance using counters inside the application, and try to improve the result by executing the code in several threads. All that is needed to reproduce the example is any java development environment or just jdk and a visualvm utility that will help us diagnose the problems that have arisen. The example intentionally does not use various benchmarks for measuring performance and other advanced tools - in this case, they are superfluous. The test case was run under Windows on an Intel Core i7 processor with 4 physical and 8 logical cores.
So, let's create a simple application that, in a loop, will perform a computational task that burdens the processor, namely, the calculation of the factorial. Moreover, each task, too, in a loop will calculate the factorial of a number lying in the range from 1 to 25. The floating range is taken to bring the example closer to reality. Below is the code for the work () function:
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(RandomUtils.nextInt(1, 25));
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
The function receives as input the number of cycles for calculating the factorial, specified by a constant:
private static final int POWER_BASE = 1000000;After completing a certain number of tasks specified in the variable
private static final int LOG_STEP = 10;The number of completed tasks and the total time of their execution are logged.The
work () function also uses:
//
private long startTime;
//
private AtomicLong counter = new AtomicLong();
//
private long factorial(int power) {
if (power == 1) return power;
else return power * factorial(power - 1);
}
It should be noted that a one-time execution of the work () function in one thread takes about 20 ms, so a synchronized call to the shared variable counter at the end, which could be a bottleneck, does not create problems, since it happens for each thread no more than 20 times ms, which significantly exceeds the execution time of counter.incrementAndGet (). In other words, contention between threads associated with access to a synchronized counter should not significantly affect the results of the experiment and can be neglected.
Let's run the following code in one thread and see the result:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
work(POWER_BASE);
}
In the console we see the following output:
10 Tasks completed in 0 seconds
...
100 Tasks completed in 2 seconds
...
500 Tasks completed in 10 seconds
So, in one thread we got a performance equal to 50 tasks per second or 20 ms per task.
Parallelizing code
If we got the performance X in one thread, then on 4 processors, in the absence of additional load, we can expect that the performance will be about 4 * X, that is, it will increase by 4 times. It seems quite logical. Well let's try!
Introducing a simple pool with a fixed number of threads:
private ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
Constant:
private static final int POOL_SIZE = 1;We will change in the range from 1 to 16 and fix the result.
Redesigning the launch code:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(() -> work(POWER_BASE));
}
By default, the size of the task queue in the thread pool is Integer.MAX_VALUE, we add no more than Integer.MAX_VALUE tasks to the thread pool, so the task queue should not overflow.
Go!
First, let's set the POOL_SIZE constant to 8 threads:
private static final int POOL_SIZE = 8;Run the application and look at the console:
10 Tasks completed in 3 seconds
20 Tasks completed in 6 seconds
30 Tasks completed in 8 seconds
40 Tasks completed in 10 seconds
50 Tasks completed in 14 seconds
60 Tasks completed in 16 seconds
70 Tasks completed in 19 seconds
80 Tasks completed in 20 seconds
90 Tasks completed in 23 seconds
100 Tasks completed in 24 seconds
110 Tasks completed in 26 seconds
120 Tasks completed in 28 seconds
130 Tasks completed in 29 seconds
140 Tasks completed in 31 seconds
150 Tasks completed in 33 seconds
160 Tasks completed in 36 seconds
170 Tasks completed in 46 seconds
What do we see? Instead of the expected increase in performance, it dropped by more than 10 times from 20ms per task to 270ms. But that's not all! The message about 170 completed tasks is the last in the log. Then the application seemed to have stopped completely.
Before dealing with the reasons for this strange behavior of the program, let's understand the dynamics and remove the log sequentially for 4 and 16 threads by setting the POOL_SIZE constant to the appropriate values.
Log for 4 threads:
10 Tasks completed in 2 seconds
20 Tasks completed in 4 seconds
30 Tasks completed in 6 seconds
40 Tasks completed in 8 seconds
50 Tasks completed in 10 seconds
60 Tasks completed in 13 seconds
70 Tasks completed in 15 seconds
80 Tasks completed in 18 seconds
90 Tasks completed in 21 seconds
100 Tasks completed in 33 seconds
The first 90 tasks completed in about the same time as for 8 threads, then another 12 seconds were required to complete another 10 tasks and the application hung.
Log for 16 threads:
10 Tasks completed in 2 seconds
20 Tasks completed in 3 seconds
30 Tasks completed in 6 seconds
40 Tasks completed in 8 seconds
...
290 Tasks completed in 51 seconds
300 Tasks completed in 52 seconds
310 Tasks completed in 63 seconds
After completion For 310 tasks, the application was frozen and, as in the previous cases, the last 10 tasks took more than 10 seconds to complete.
Let's summarize:
Parallelizing the execution of tasks leads to degradation of performance by 10 or more times
In all cases, the application hangs and the fewer threads the faster it hangs (we will return to this fact)
Search for problems
Obviously, something is wrong with our code. But how do you find the reason? To do this, we'll use the visualvm utility. And we will launch it before the execution of our application, and after launching the application we will switch to the required java process in the visualvm interface. The application can be launched directly from the development environment. Of course, this is generally wrong, but in our example it will not affect the result.
First of all, we look at the Monitor tab and see that something is wrong with the memory.
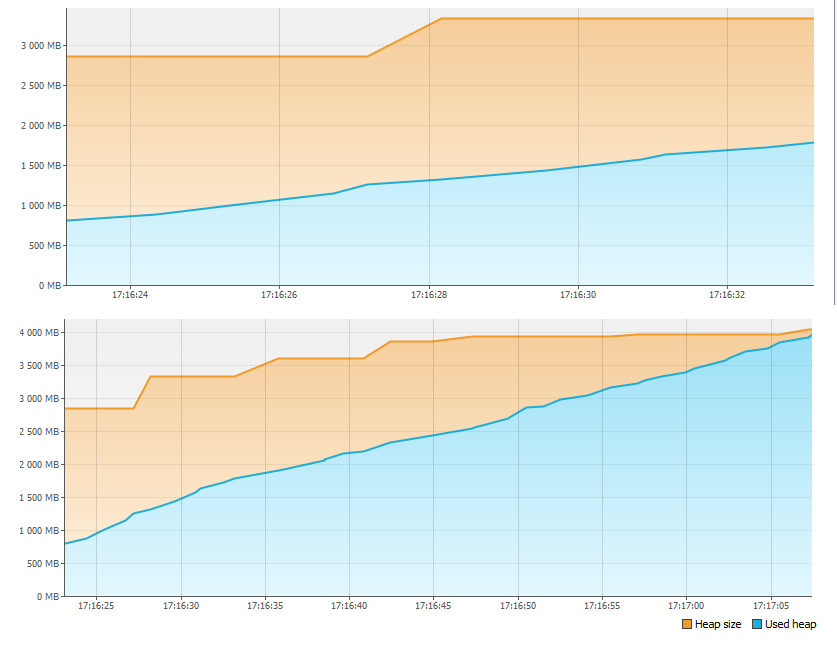
In less than a minute, 4GB of memory simply ran out! Therefore, the application stopped. But where did the memory go?
Restart the application and press the Heap Dump button on the Monitor tab. After removing and opening the memory dump, we see:

In the Classes by Size of Instances section, more than 1 GB is occupied by the LinkedBlockingQueue $ Node class. It is nothing more than one top of the thread pool task queue. The second largest class is the task itself being added to the thread pool. In support of this, in the Classes By Number of Instances section, we see the correspondence between the number of instances of the first and second classes (the match is not entirely accurate, apparently due to the fact that first a task is created, and then only a new top of the queue, and because of the time difference multiplied by the number of threads, we have a slight discrepancy in the number of instances).
Now let's count. We create about 2 billion tasks in a loop (Integer.MAX_VALUE), that is, about 2GB of tasks. Tasks are executed slower than they are created, so the queue size keeps growing. Even if each task required only 8 bytes of memory, the maximum queue size would be:
8 * 2GB = 16GB
With a total heap size of 4GB, it is not surprising that there was not enough memory. In fact, if we did not interrupt the execution of the application whose log stopped, after a while we would see the famous OutOfMemoryError and even without visualvm, just by looking at the code, we could guess where the memory is going.
Let's remember that the fewer the number of threads running the tasks, the faster the application stopped. We can now try to explain this. The fewer the number of threads, the faster the application runs (why - we have yet to find out) and the faster the task queue fills up and memory becomes full.
Well, fixing the memory overflow problem is very simple. Let's create a constant instead of Integer.MaxValue:
private static final int MAX_TASKS = 1024 * 1024;
And let's change the code as follows:
startTime = System.currentTimeMillis();
for (int i = 0; i < MAX_TASKS; i++) {
executorService.execute(() -> work(POWER_BASE));
}
Now it remains to run the application and make sure that everything is in order with memory:

We continue the analysis
We launch our application again, sequentially increasing the number of threads and fixing the result.
1 thread - 500 Tasks in 10 seconds
2 threads - 500 tasks in 21 seconds
4 threads - 500 Tasks in 37 seconds
8 threads - 500 Tasks in 49 seconds
16 threads - 500 Tasks in 57 seconds
As we can see, the execution time of 500 tasks when increasing the number of threads does not decrease, but increases, while the speed of execution of each portion of 10 tasks is uniform and the threads no longer freeze.
Let's use the visualvm utility again and take a thread dump while the application is running. For the most accurate picture, it is better to take a dump when working on 16 threads. There are different utilities for analyzing thread dumps, but in our case, you can simply scroll through all threads with the names "pool-1-thread-1", "pool-1-thread-2", etc. in the visualvm interface and see the following:

At the time of dumping, most threads generate the next random number to calculate the factorial. It turns out that this is the most time-consuming function. Why then? To figure it out, let's go into the source code of Random.next () and see the following:
private final AtomicLong seed;
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
All threads share a single instance of the seed variable, access to which is synchronized through the use of the AtomicLong class. This means that when each random number is generated, threads are queued to access this variable, rather than executing in parallel. Therefore, productivity does not grow. But why does she fall? The answer is simple. When parallelizing execution, additional resources are spent on supporting parallel processing, in particular, switching the processor context between threads. It turns out that additional costs have appeared, and the threads still do not work in parallel, since they compete for access to the value of the seed variable and are queued when seed.compareAndSet () is called. Competition between threads for a limited resource, perhapsthe most common cause of performance degradation when parallelizing computations.
Let's change the code of the work () function as follows:
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(20);
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
and again check the performance on a different number of threads:
1 thread - 1000 tasks in 17 seconds
2 threads - 1000 tasks in 10 seconds
4 threads - 1000 tasks in 5 seconds
8 threads - 1000 tasks in 4 seconds
16 threads - 1000 tasks in 4 seconds
Now the result is close to our expectations. Performance on 4 threads has increased by about 4 times. Further, the increase in performance practically stopped because parallelization is limited by processor resources. Let's take a look at the graphs of the processor load, captured through visualvm when working on 4 and 8 threads.

As you can see from the graphs, with 4 threads, more than 50% of processor resources are free, and with 8 threads, the processor is used by almost 100%. This means that in this example, 8 threads is the limit, further performance will only decrease. In our example, the performance growth stopped already on 4 threads, but if the threads, instead of calculating the factorial, performed synchronous I / O, then, most likely, the limit of parallelization at which it gives a performance gain could be significantly increased. Readers can check this on their own and write the result in the comments to the article
If we talk about practice, then two important points can be noted:
Parallelization is usually effective when the number of threads is up to 2 times the number of processor cores (of course, in the absence of other processor load)
CPU utilization in practice should not exceed 80% to ensure fault tolerance
Reducing contention between threads
Getting carried away with talk about performance, we forgot one essential thing. By changing the call to RandomUtils.nextInt () in the code to a constant, we changed the business logic of our application. Let's go back to the old algorithm while avoiding performance issues. We found out that calling RandomUtils.nextInt () causes each of the threads to use the same seed variable to generate a random number, and, meanwhile, this is completely optional. Using in our example instead of
RandomUtils.nextInt(1, 25)the ThreadLocalRandom class:
ThreadLocalRandom.current().nextInt(1, 25)will solve the problem with competition. Now each thread will use its own instance of the internal variable needed to generate the next random number.
Using a separate variable for each thread, instead of synchronized access to a single instance of a class that is shared between threads, is a common technique to improve performance by reducing contention between threads. The java.lang.ThreadLocal class can be used to store the values of variables in the context of a thread, although there are more advanced tools, for example, Mapped Diagnostic Context.
In conclusion, I would like to note that reducing competition between threads is not only a technical, but also a logical task. In our example, each thread can use its own variable instance without any problems, but what if we need one instance for all, for example, a shared counter? In this case, you would have to refactor the algorithm itself. For example, store a counter in the context of each stream and periodically or upon request calculate the value of the total counter based on the values of the counters for each stream.
Conclusion
So, there are 3 points that affect the performance of parallel processing:
- CPU resources
- Competition between threads
- Other factors that indirectly affect the overall result