
- What exactly is consuming so much memory?
- Is there any way to avoid this?
Here I want to talk about how I was looking for answers to these questions. I plan to use this material as a reference whenever I need to be profiling Python code.
I started analyzing Pylint, starting at the program entry point (
pylint/__main__.py), and got to the "fundamental" loop forthat you would expect in a program that checks many files:
def _check_files(self, get_ast, file_descrs):
# pylint/lint/pylinter.py
with self._astroid_module_checker() as check_astroid_module:
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
To begin with, I just put a statement in this loop
print(«HI»)to make sure that this is indeed the loop that starts when I execute the command pylint my_code. This experiment went smoothly.
Next, I decided to find out what exactly is stored in memory during the work of Pylint. So I used it
heapyand made a simple "heap dump", hoping to analyze this dump for anything unusual:
from guppy import hpy
hp = hpy()
i = 0
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
print("HEAP")
print(hp.heap())
if i == 100:
raise ValueError("Done")
The heap profile ended up almost entirely consisting of call stack frames (
types.FrameType). I, for some reason, expected something like this. So many similar objects in the dump made me think that there seem to be more of them than there should be.
Partition of a set of 2751394 objects. Total size = 436618350 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 429084 16 220007072 50 220007072 50 types.FrameType
1 535810 19 30005360 7 250012432 57 types.TracebackType
2 516282 19 29719488 7 279731920 64 tuple
3 101904 4 29004928 7 308736848 71 set
4 185568 7 21556360 5 330293208 76 dict (no owner)
5 206170 7 16304240 4 346597448 79 list
6 117531 4 9998322 2 356595770 82 str
7 38582 1 9661040 2 366256810 84 dict of astroid.node_classes.Name
8 76755 3 6754440 2 373011250 85 tokenize.TokenInfo
It was at this moment that I found the Profile Browser tool , which allows you to conveniently work with such data.
I configured the dump engine so that data would be written to a file every 10 loop iterations. Then I built a diagram showing the behavior of the program during operation.
for name, filepath, modname in file_descrs:
self._check_file(get_ast, check_astroid_module, name, filepath, modname)
i += 1
if i % 10 == 0:
hp.heap().stat.dump("/tmp/linting.stats")
if i == 100:
hp.pb("/tmp/linting.stats")
raise ValueError("Done")
I ended up with what is shown below. This diagram confirms that objects
type.FrameTypeand type.TracebackType(trace information) consumed a lot of memory during the explored Pylint run.

Data Analysis
The next stage of the study was the analysis of objects
types.FrameType. Since memory management mechanisms in Python are based on counting the number of references to objects, data is kept in memory as long as something refers to it. I decided to find out what exactly "holds" the data in memory.
Here I used an excellent library
objgraphthat, using the capabilities of the Python memory manager, gives information about which objects are in memory, and allows you to find out what exactly refers to these objects.
In fact, it's great that we have the ability to do this kind of software research. Namely, if there is a reference to an object, you can find everything that refers to this object (in the case of C-extensions, everything is not so smooth, but, in general,
objgraphgives reasonably accurate information). Before us is a great tool for debugging code, giving access to a lot of information about the internal mechanisms of CPython. For me, this is another reason to think of Python as a pleasant language to work with.
At first, I stumbled on searching for objects, as the team
objgraph.by_type('types.TracebackType')did not find anything at all. And this is despite the fact that I knew that there are a huge number of such objects. It turned out that a string should be used as the type name traceback. The reason for this is not entirely clear to me, but what is - that is. The correct command, in the end, looks like this:
random.choice(objgraph.by_type('traceback'))
This construct randomly selects objects
traceback. And with the help objgraph.show_backrefsyou can build a diagram of what refers to these objects.
In the end, instead of just throwing an exception, I decided to investigate what happens in the loop
for( import pdb; pdb.set_trace()) after 100 iterations. I started to study randomly selected objects traceback.
def exclude(obj):
return 'Pdb' in str(type(obj))
def f(depth=7):
objgraph.show_backrefs([random.choice(objgraph.by_type('traceback'))],
max_depth=depth,
filter=lambda elt: not exclude(elt))
Initially, I saw only chains of objects
traceback, so I decided to climb to a depth of 100 objects ...

Analyzing traceback objects
As it turns out, some objects
tracebackrefer to other objects of the same type. Well, good. And there were a lot of such chains.
For some time, without much success for the business, I studied them, and then moved on to the study of objects of the second type of interest to me -
FrameType(frame). They also looked suspicious. Analyzing them, I came to diagrams that resemble the following.

Parsing frame objects
It turns out that objects
tracebackhold objectsframe(so there are a similar number of such objects). All of this, of course, looks extremely confusing, but objectsframeat least point to specific lines of code. All of this led me to the realization of one ridiculously simple thing: I never bothered to look at data using such large amounts of memory. I should definitely look at the objects themselvestraceback.
I walked towards this goal, it seems, the most tortuous of all possible paths. Namely, it recognized the addresses in the dump created by
objgraph, then looked at the addresses in memory, then searched the Internet for "how to get a Python object, knowing its address." After all these experiments, I came up with the following scheme of actions:
ipdb> import ctypes
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object)
py_object(<traceback object at 0x7f187d22b880>)
ipdb> ctypes.cast(0x7f187d22b880, ctypes.py_object).value
<traceback object at 0x7f187d22b880>
ipdb> my_tb = ctypes.cast(0x7f187d22b880, ctypes.py_object).value
ipdb> traceback.print_tb(my_tb, limit=20)
In fact, you can just say to Python, “Look at this memory. There is definitely at least a regular Python object here. "
Later I realized that I already had links to objects of interest to me thanks to
objgraph. That is - I could just use them.
It felt like the library
astroid, the AST parser used in Pylint, was creating objects everywhere tracebackthrough exception handling code. I suppose that when something is used somewhere that can be called an "interesting trick", then along the way they forget about how the same can be done easier. So I don't really complain about it.
Objects
tracebackhave a lot of data related to astroid. There has been some progress in my research! Libraryastroidis quite similar to a program that can hold huge amounts of data in memory, since it parses files.
I rummaged through the code and found the following lines in the file
astroid/manager.py:
except Exception as ex:
raise exceptions.AstroidImportError(
"Loading {modname} failed with:\n{error}",
modname=modname,
path=found_spec.location,
) from ex
“This is it,” I thought, “this is exactly what I'm looking for!” It is a sequence of exceptions that results in the longest chains of objects
traceback. And here, among other things, files are parsed, so recursive mechanisms can also be encountered here. And something that resembles a construction raise thing from other_thingties it all together.
I removed
from exand ... nothing happened. The amount of memory consumed by the program has remained practically the same, the objects tracebackhave not gone anywhere either.
I was aware that exceptions store their local bindings in objects
traceback, so you can get to ex. As a result, the memory of them cannot be cleared.
I did a massive refactoring of the code, trying to basically get rid of the block
except, or at least from a link to ex. But, again, I got nothing. Even
though I was bursting, I could not "incite" the garbage collector on objects
traceback, even considering that there were no references to these objects. I assumed that the reason for this was that there was some other link somewhere.
In fact, I took a false trail back then. I did not know if this was the cause of the memory leak, because at one point I began to realize that I did not have any evidence to support my "theory of exception chains". I only had a bunch of guesses and millions of objects
traceback.
Then I began to look at these objects at random in search of some additional clues. I tried to manually “climb” the chain of links, but in the end I found only emptiness.
Then it dawned on me: all these objects
tracebackare located "one above the other", but there must be an object that is "above" all the others. One that is not referenced by any of the other such objects.
Links were made through a property
tb_next, the sequence of such links was a simple chain. So I decided to take a look at the objects tracebackat the end of the respective chains:
bottom_tbs = [tb for tb in objgraph.by_type('traceback') if tb.tb_next is None]
There is something magical about poking your way through half a million objects with a one-liner and finding what you need.
In general, I found what I was looking for. Found the reason why Python had to keep all these objects in memory.

Finding the Source of the Problem
It was all about the file cache!
The point is that the library
astroidcaches the results of loading modules. If the code needs a module that has already been used, the library will simply provide it with the result of loading this module that it already has. This also leads to the reproduction of errors by storing the thrown exceptions.
At this point, I made a bold decision, reasoning like this: “It makes sense to cache something that does not contain errors. But, in my opinion, there is no point in storing objects
tracebackgenerated by our code. "
I decided to get rid of the exception, keep my own class,
Errorand just rebuild the exceptions when needed. Details can be found in thisPR, but it really turned out to be not particularly interesting.
As a result, I was able to reduce the memory consumption when working with our codebase from 500 MB to 100 MB.
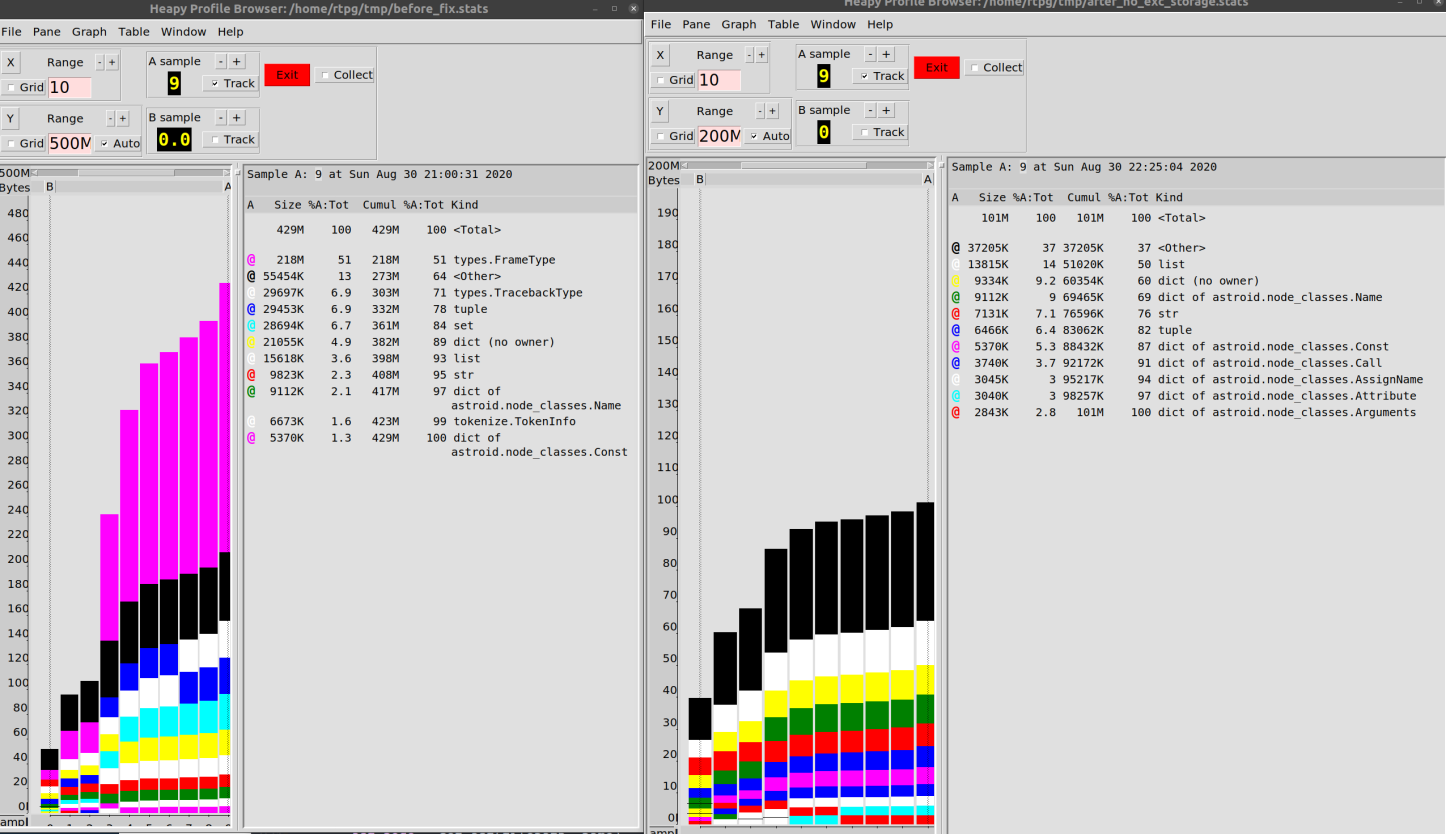
I would say that 80% improvement is not so bad.
Speaking of PR, I'm not sure if it will be included in the project. The changes that it brings in itself are not only related to performance. I believe that the way it works can, in some situations, reduce the value of the stack trace data. Considering all the details, this is a rather gross change, even though this solution passes all tests.
As a result, I made the following conclusions for myself:
- Python gives us great memory analysis capabilities. I should use these features more often when debugging code.
- , .
- , -, « ». . , , , .
- , (, , Git). , , . , .
While I was writing this, I realized that I had already forgotten much of what allowed me to come to certain conclusions. So I ended up checking some of the code snippets again. Then I ran the measurements on a different codebase and found out that memory oddities are specific to only one project. I spent a lot of time looking for and fixing this nuisance, but it is very likely that this is just a feature of the behavior of the tools we use, which manifests itself only in a small number of those who use these tools.
It is very difficult to say something definite about performance even after taking such measurements.
I will try to transfer the experience gained from the experiments I described to other projects. I believe there are many of these performance issues in open source Python projects that are easy to fix. The fact is that the Python developer community usually pays relatively little attention to this issue (this is - if we do not talk about projects that are extensions to Python, written in C).
Have you ever had to optimize the performance of your Python code?

