For the search for IT specialists, such a scheme is not yet particularly applicable, since this area is specific, and here recruiters use other tools. As for the rest, it is quite a topical thing, especially when there are more than a hundred respondents to the vacancy.
Alexander Barabash told us about how the service works and what is the logic of personnel officers. Formally, he is the director of GoRecruit, but at the same time he is directly related to development.
REM AI-. Awtor (https://habr.com/ru/company/leader-id/blog/521378/), iPavlov (https://habr.com/ru/company/leader-id/blog/522624/) OpenTalks.AI (https://habr.com/ru/company/leader-id/blog/523448/).- What is GoRecruit, how does it work?
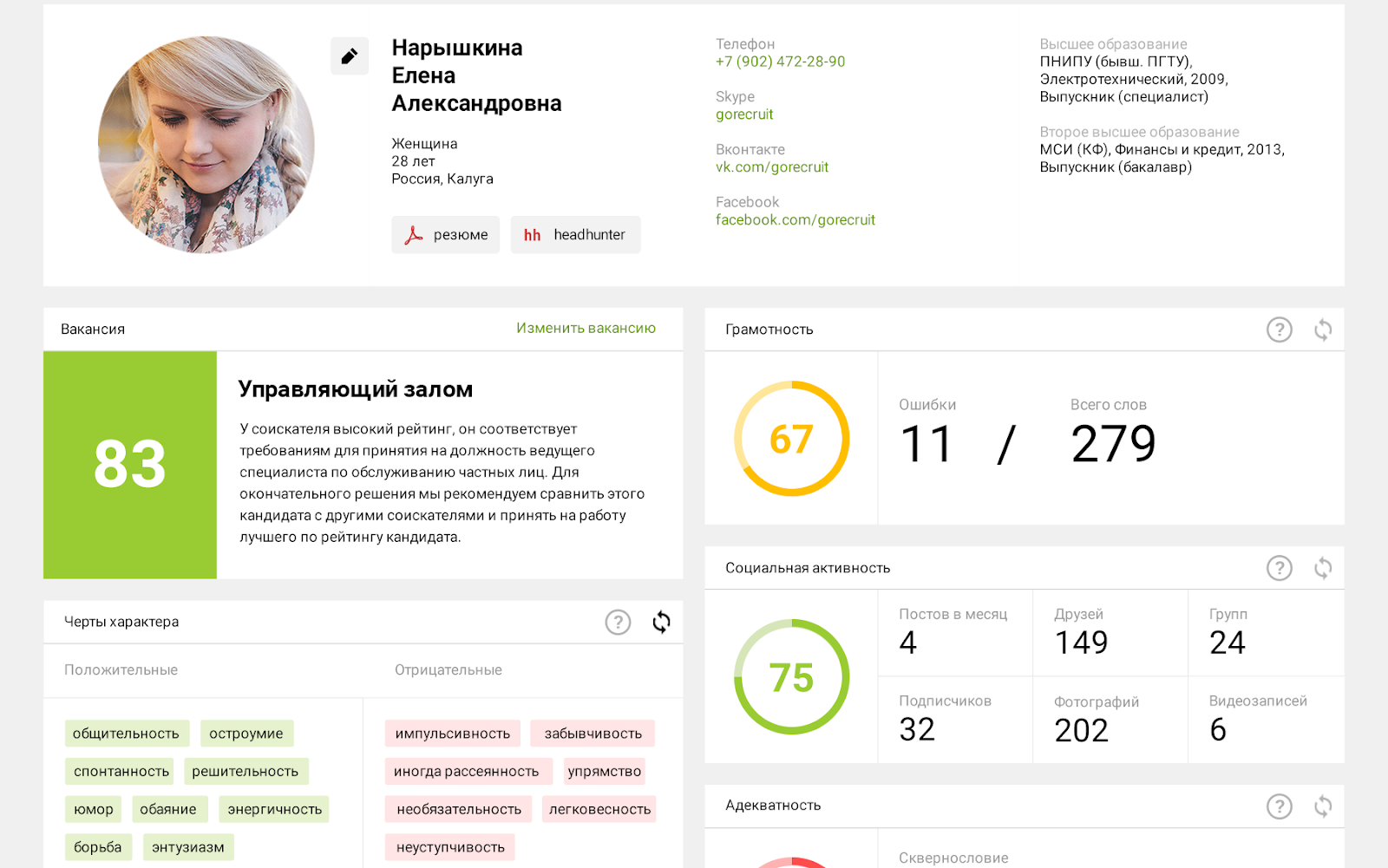
- This is a system for supporting personnel decisions based on the analysis of data from resumes and open sources, including social networks. It calculates the rating of an applicant applying for a certain profession, reducing the recruiter's labor costs.
The fundamental difference from analogs is that in order to participate in the assessment, the applicant must respond to the vacancy and independently upload his resume to it or log in through the profile on social networks. In my opinion, this is a very important logic. Some services offer cold search tools for job seekers: they take open data from the profiles of unsuspecting people, which sometimes goes against social media policies. It is not right. We take data only after authorization (i.e. user consent), supplementing them with data from resumes and open sources such as the Federal Bailiff Service, the bases of the Ministry of Internal Affairs and Tax. The ultimate task of the system is to enrich the data about the applicant by generating a detailed report for the personnel department and security personnel.
Among other information, this report contains a rating that characterizes the expected success of a given candidate in a selected vacancy. The recruiter decides what to do next with this rating.
- How do you describe the vacancy for comparison? And where does artificial intelligence?
- In fact, artificial intelligence, which is so often talked about now, is a method of extrapolating statistical data. But in order to extrapolate something, you need to have a sufficient amount of initial information. For large businesses, where there are statistical data on the movement of personnel, we build a vacancy model based on this data using neural networks.
In fact, we analyze information about those employees of the company who are successful in a given position.As a result, the candidate's rating in the report will be calculated based on this company experience (based on comparison with other people who have worked in similar positions in this company).
For small and medium-sized businesses, where statistical data is not enough to build a model, we use an expert system. The mathematical model of this system is based on the expert opinion of specialists, which replaces the course of human thought in decision-making. This approach is justified when the business lacks its own statistics. Over time, we develop these models - make adjustments as needed.
- If we talk about a neural network model, how is a person's “success” assessed in this or that position?
- And this is one of the subtleties of our work. These criteria differ from company to company. The simplest option is employment status after a certain period of time. For example, if a person is still working in this position a year after employment, he can be considered successful, because the ultimate goal is to find an unproblematic person who would work for a long time in the company.
More advanced companies have internal HR KPIs. We take them as a basis - we consider successful people with an indicator, for example, above 70%. We select appropriately data on the movement of personnel and train a mathematical model for each profession separately.
- What are the limitations of the applicability of this approach?
- There are no hard restrictions. But this is a statistical method. It is clear that the more data (the richer the sample), the more accurate the forecast, i.e. we will say more precisely how successful the candidate will be. Therefore, the solution works best for some mass professions. We are not yet ready to make recommendations for high or unique positions.
- What place does the system take in the process of searching for people?
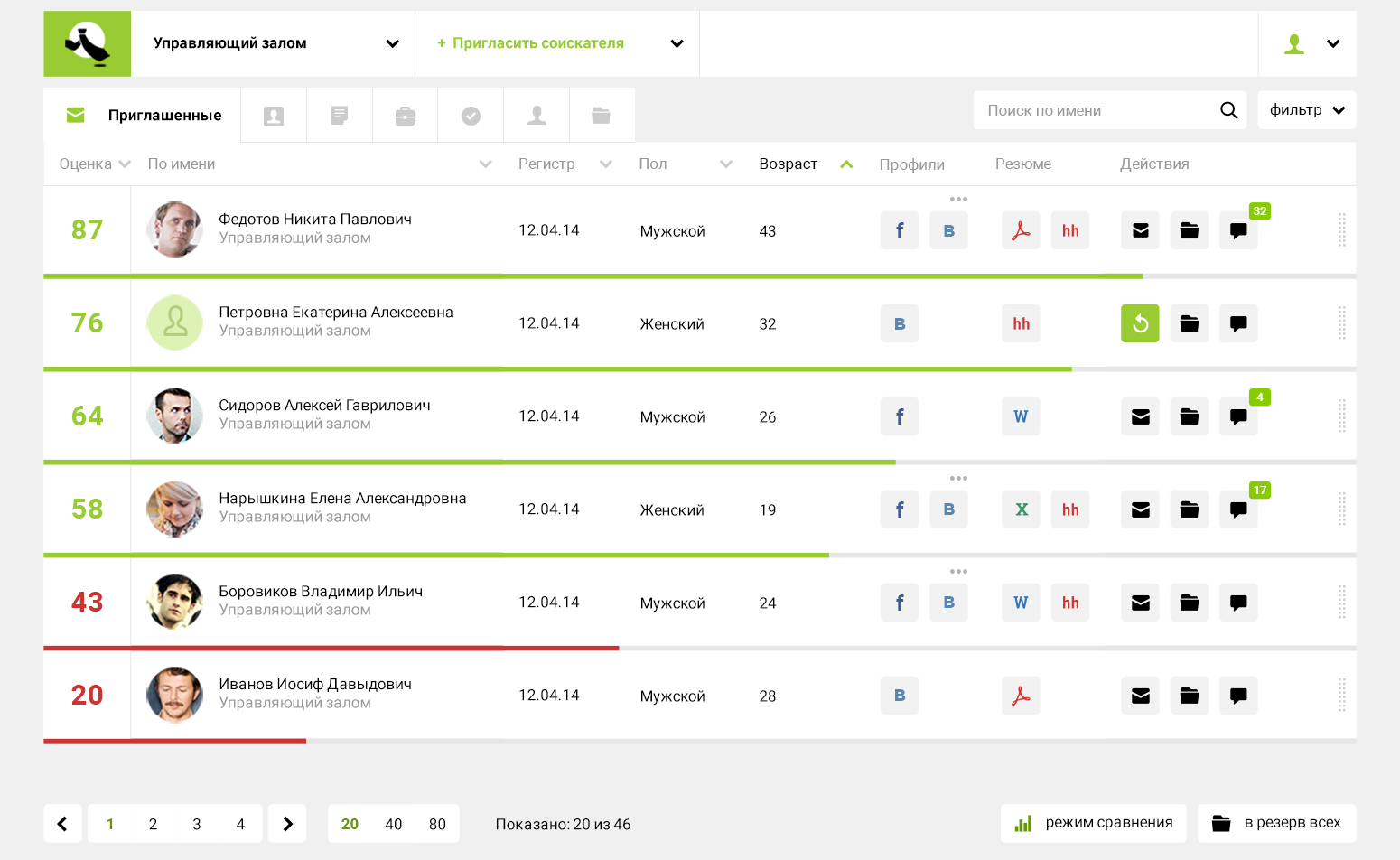
- We are not engaged in search. We occupy a different niche - we provide an assessment when we have received a lot of responses for a vacancy and it is necessary to decide who to call for an interview.
: . 600 . 5 , 50 , , , , .And our system gives an answer in 5 seconds: it calculates the rating and ranks 600 resumes by it. You can immediately proceed to the next stage - invite for an interview or send a test task, depending on how the personnel decisions are made within the company.
In fact, this is the most time consuming initial filter in the chain of actions related to personnel decision making. It's one thing to compare three people. But it is impossible to remember and compare the conditional 600 resumes - this is above the physical capabilities of a person. After reading even a dozen, you will already forget what happened in the beginning. Our psychologists like to repeat that the human brain remembers and can quickly store in the head about 7-10 parameters. Therefore, the big question is how well a recruiter will manually study 600 resumes within a week.
- How exactly is this rating built? What data do you take from your resume?
- We use a combined approach - we combine ontological engineering methods with neural networks. The system extracts semantic meanings from the resume text, which we need for the subsequent rating calculation. Where did the person work before, what position he held, what positions he held, whether he had breaks from work, what successes he achieved and what functions he performed, what kind of education he received, whether his profession corresponds to the profile of education, etc.
Also, if it matters, we highlight age, gender and other additional information - everything that a regular HR officer will look at when reading a resume. Each of these items is a parameter. Usually the recruiter compares them, we just algorithmized this comparison.
- What additional sources of information do you use?
- In addition to the aforementioned bases of the Ministry of Internal Affairs, FSSP, etc., we are now using the social network VKontakte. We also have developments for Facebook and Twitter, but VKontakte is the main source. When we made a model for making personnel decisions for the position of a PC operator for multifunctional centers, we found that about 97% of candidates have a profile on this social network. By the way, the client at that moment doubted whether it would be possible to enrich profiles with data from VKontakte, but the indicator of 97% reassured him.
- What exactly is your system interested in in your social network profile?
- First of all, we take the texts that a person publishes on his page in order to determine his psychological profile.

Examples of keywords for assessing psychotype from a joint study of the University of Pennsylvania and Cambridge
This is a kind of data preprocessing. We evaluate personality traits by words and phrases used in posts (you can read more about a similar technique used to analyze posts on Facebook here (pdf) and here ).
Using the Myers-Briggs typology, we classify a person as one of 16 psychotypes.This information also affects the final rating: people of completely different psychotypes are suitable for different professions.
In addition, we are, of course, interested in the information from the profile. VKontakte gives out about 70 parameters - what a person wrote about himself on the page: age, gender, education, preferences, children, etc.
- How many posts can the system evaluate to a person? What if only photos of cats are posted on social networks?
- The system does not offer miracles - it behaves like a regular recruiter.
Let's say a candidate applied for a job but didn't write anything on his resume. We (like the recruiter) look at open data - let's say there is nothing there either. Either there is no profile on the social network itself, or it is empty.
. , , .This is the common logic of making a personnel decision. If you do not see information about the candidate and cannot check it with open sources, you go to the next resume.
When comparing two people - with a wealth of proven experience, good education and knowledge, or some kind of incognito, you will most likely choose the one about which you know more.
Our system interprets human logic here. Lack of data is also information that characterizes a person in a certain way, but, as a rule, it is used with a low rating.
- As a result, from the point of view of the system, the ideal candidate is the one who openly “spreads his life” on the social network?
- No. Social media is just an add-on, and the basic data is obtained from the resume.
- Do you analyze the texts of articles on Habré or the code on GitHub to further enrich your profile?
- No. These are mainly resources for IT people, and we do not have such a focus. In this segment, there are other tools that are sharpened for the search and assessment of IT specialists.
- Are there any factors that, from the point of view of the system, are unambiguously credited to the candidate as plus or minus?
- This is exactly the unique feature of GoRecruit: there are no such factors. All data collected affects the final decision. But for each profession, in each company, the degree of influence of each of the factors will differ.
The meaning of the mathematical model lies in the fact that these parameters change depending on how the training takes place - what data is used for this.
- In the course of working on the models, hundreds of resumes must have passed before your eyes. Can you identify any typical features of generations?
- Probably not, except for one. The older a person is, the richer his background is. As a rule, with age, his career path begins to be traced and in general there is more information about him.
But I can note another feature: the resume as a format is much more diverse than it seems at first glance. Despite the presence of templates like HeadHunter, people write very different things on resumes and in very different wordings. And here we are faced with problems in identifying semantic meanings, since all algorithms partly rest on the structure of the resume. This is a challenging and challenging task.
- You have applied for the Archipelago accelerator 20.35... What do you want to get from him?
- I think this is an interesting opportunity for the overall development of our product in all directions. Based on what I've read about the Archipelago, it offers multidirectional opportunities, so we don't perceive the event as something one-sided - looking for an investor or something else. Here we are waiting for the solution of our development issues, new contacts, product promotion and will even look for clients. Together.
- Who is on your team? Recruiters, developers, mathematicians?
- We have a team of mathematicians, programmers and psychologists - people at the intersection of technical and humanitarian sciences (psychology and mathematics), experts in the field of Big data, artificial intelligence (machine learning).