
Image source
Two revolutions in natural language processing
The first revolution in NLP was associated with the success of models based on vector representations of the semantics of a language, obtained using unsupervised learning methods. The flowering of these models began with the publication of the results of Tomáš Mikolov , PhD student Yoshua Bengio (one of the founding fathers of modern deep learning, a Turing Prize laureate), and the emergence of the popular word2vec tool. The second revolution began with the development of attention mechanisms in recurrent neural networks, which resulted in the understanding that the attention mechanism is self-sufficient and could well be used without the recurrent network itself. The resulting neural network model is called the "transformer". It was presented to the scientific community in 2017 in an article entitled “Attention Is All You Need ,” written by a group of researchers from Google Brain and Google Research. The rapid development of transformer-based networks has resulted in giant language models like OpenAI's Generative Pre-trained Transformer 3 (GPT-3)capable of efficiently solving many NLP problems.
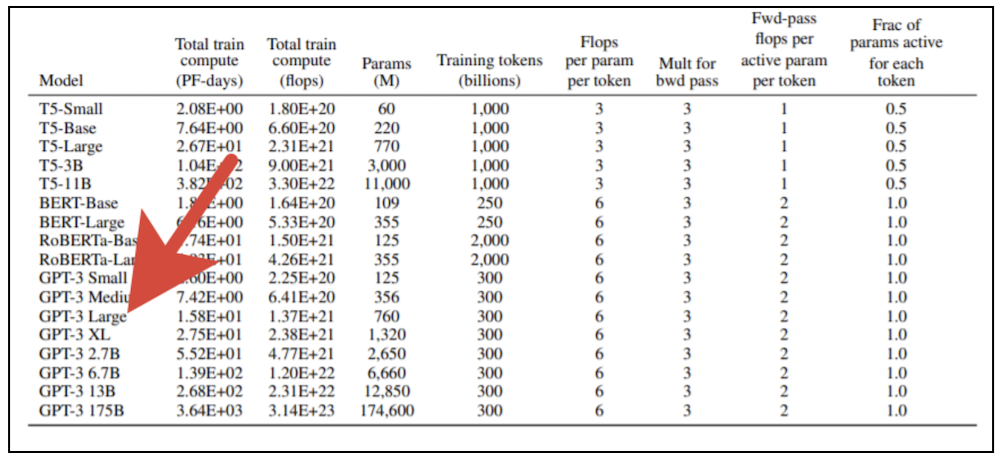
It takes significant computing resources to train giant transformer models. You can't just take a modern graphics card and train such a model on your home computer. In the original OpenAI publication, 8 variants of the model are presented, and if you take the smallest of them (GPT-3 Small) with 125 million parameters and try to train it using a professional video card NVidia V100 equipped with powerful tensor cores, then it will take about six months. If we take the largest version of the model with 175 billion parameters, then the result will have to wait almost 500 years. The cost of training the largest version of the model at the rates of cloud services that provide modern computing devices for rent,exceeds a billion rubles (and this is also subject to linear performance scaling with an increase in the number of processors involved, which is in principle unattainable).
Long live supercomputers!
It is clear that such experiments are available only to companies with significant computing resources. To solve such problems, in 2019 Sberbank put into operation the Christophari supercomputer , which took the first place in performance among the supercomputers available in our country. 75 DGX-2 compute nodes (each with 16 NVidia V100 cards ) connected by an ultra-fast bus based on Infiniband technologyallow you to train GPT-3 Small in just a few hours. However, even for such a machine, the task of training larger variants of the model is not trivial. Firstly, part of the machine is busy with training other models designed to solve problems in the field of computer vision, speech recognition and synthesis, and many other areas of interest to various companies from the Sberbank ecosystem. Secondly, the learning process itself, which simultaneously uses many computational nodes in a situation where the model weights do not fit in the memory of one card, is rather non-standard.
In general, we found ourselves in a situation where the torch.distributed, familiar to many, was not suitable for our purposes. We did not have so many options, in the end we turned to the "native" implementation of Megatron-LM for NVidiaand Microsoft's new brainchild - DeepSpeed , which required the creation of custom docker containers on Christophari, with which our colleagues from SberCloud promptly helped . DeepSpeed, first of all, gave us convenient tools for model parallel training, that is, spreading one model across several GPUs and sharding the optimizer between GPUs. This allows you to use larger batches, as well as train models with more than 1.5 billion weights without a mountain of additional code.
Surprisingly, technology over the past half century in its development has described the next round of the spiral - it looks like the era of mainframes (powerful computers with terminal access) is returning. We are already accustomed to the fact that the main development tools are a personal computer allocated for exclusive use by the developer. In the late 1960s and early 1970s, an hour of mainframe operation cost about the same as a full month's wages for a computer operator! It seemed that these times were gone forever and "iron" became forever cheaper than working time. However, it looks like the hardware has made an impressive comeback. The everyday life of a modern machine learning specialist again resembles the everyday life of Sasha Privalov from the story of the Strugatsky brothers "Monday starts on Saturday", with the only difference that the place of "Aldan" in our case is taken by "Christofari", and the role of magic and sorcery is performed by methods of deep learning.
From SberDevices experience
Many times in the past we have had to learn other models based on transformers - these are various inheritors of BERT, and encoder-decoder models, like T5 from Google . Virtual assistants created by SberDevices for various surfaces, starting with the latest SberBox and SberPortaland ending with the usual Sberbank Online application, they use several similar models in their work to solve various problems in the course of communicating with the user. For example, the virtual assistant Joy uses the GPT-2 Medium model in the chatter mode, trained on a large corpus of Russian literature, trained on a special dialogue dataset and equipped with a special ranking mechanism designed to select the most interesting answers. Such models are able to conduct a conversation with the user, not choosing cues from a pre-prepared library of answers, but making their own phrases “on the fly”, which makes communication with them more diverse and entertaining.
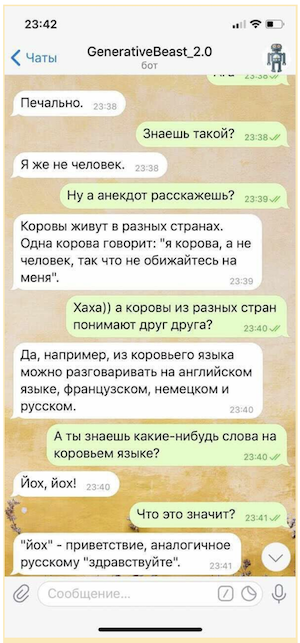

Of course, such a "chatter" cannot be used without some insurance in the form of a system of microintents (rules designed to provide controlled answers to some of the most sensitive questions) and a separate model designed to dodge provocative questions, but even in such a limited form "Generative" "chatter" is able to noticeably raise the mood of her interlocutor.
In a word, our experience in teaching large transformer models came in handy when Sberbank's management decided to allocate computing resources for a research project to train GPT-3. Such a project required combining the efforts of several units at once. On the part of SberDevices, the leadership role in this process was taken by the Department of Experimental Machine Learning Systems (with the participation of a number of experts from other teams), and on the part of Sberbank.AI - by the AGI NLP team . Our colleagues from SberCloud, who support Christophari, also actively joined the project.
Together with colleagues from the AGI NLP team, we managed to assemble the first version of the Russian-language training corpus with a total volume of over 600 GB. It includes a huge collection of Russian literature, snapshots of Russian and English Wikipedia, a collection of snapshots of news and Q&A sites, public sections of Pikabu , a complete collection of materials from the popular science portal 22century.ru and the banking portal banki.ru , as well as the Omnia Russica corpus . In addition, since we wanted to experiment with the ability to handle program code, we included snapshots of github and StackOverflow in the training corpus.... The AGI NLP team has done a lot of data cleaning and deduplication, as well as preparing the model validation and testing kits. If in the original corpus used by OpenAI, the ratio of English to other languages is 93: 7, then in our case the ratio of Russian to other languages is approximately 9: 1.
We chose the GPT-3 Medium (350 million parameters) and GPT-3 Large (760 million parameters) architectures as the basis for the first experiments. In doing so, we trained the model as with alternating transformer blocks with a sparseand dense attention mechanisms and models in which all attention blocks were complete. The fact is that the original work from OpenAI talks about block interleaving, but does not provide their specific sequence. If all attention blocks in the model are complete, it increases the computational cost of training, but ensures that the predictive potential of the model is fully exploited. Currently, the scientific community is actively studying various models of attention, designed to reduce the computational costs of training models and increase accuracy. In a short time, researchers have proposed a longformer , a reformer , a transformer with an adaptive attention span., compressive transformer , blockwise transformer , BigBird , linformer and a number of other similar models. We are also engaged in research in this area, while models composed of only dense-blocks are a kind of benchmark that allows us to assess the degree of decrease in the accuracy of various "accelerated" versions of the model.
Competition "AI 4 Humanities: ruGPT-3"
This year, within the framework of AI Journey, the Sberbank.AI team organized the AI 4 Humanities: ruGPT-3 competition. As part of the overall test, participants are invited to submit prototypes of solutions for any business or social problem created using the pre-trained ruGPT-3 model. Participants in the special nomination "AIJ Junior" are invited to create a solution for generating meaningful essays in four humanitarian subjects (Russian language, history, literature, social studies) of grade 11 (USE) on the basis of ruGPT-3 on the basis of ruGPT-3 for a given topic / text of the assignment.
Especially for these competitions, we trained three versions of the GPT-3 model: 1) GPT-3 Medium, 2) GPT-3 Large with alternating sparse and dense-blocks of the transformer, 3) the most "powerful" GPT-3 Large, composed of only dense blocks. The training datasets and tokenizers are identical for all models - the BBPE tokenizer and our custom Large1 dataset with a volume of 600 GB were used (its composition is given in the text above).
All three models are available for download in the competition repository.
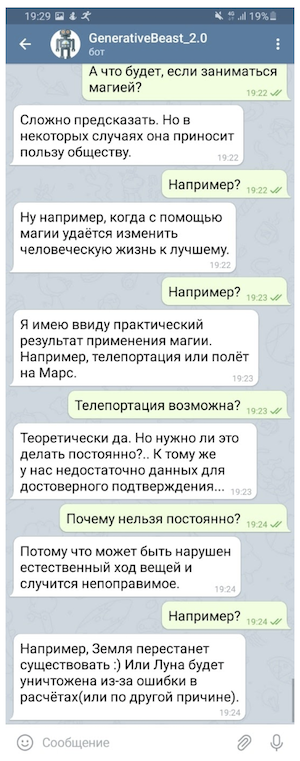
Here are some fun examples of how the third model works:



How will models like GPT-3 change our world?
It is important to understand that models like GPT-1/2/3, in fact, solve exactly one problem - they try to predict the next token (usually a word or part of it) in the sequence of the previous ones. This approach makes it possible to use "unlabeled" data for training, that is, to do without involving a "teacher", and on the other hand, it allows solving a fairly wide range of problems from the NLP field. Indeed, in the text of a dialogue, for example, a reply-reply is a continuation of the history of communication, in a work of fiction - the text of each paragraph continues the previous text, and in a question and answer session, the text of the answer follows the text of the question. As a result, large-capacity models can solve many such problems without special additional training - they only need examples that fit into the "model context"which GPT-3 has quite impressive - as many as 2048 tokens.
GPT-3 is capable not only of generating texts (including poems, jokes and literary parodies), but also correcting grammatical errors, conducting dialogues, and even (SUDDENLY!) Writing more or less meaningful program code. Many interesting uses of GPT-3 can be found on the site of independent researcher Gwern Branwen. Branuen, developing an idea expressed in a joke tweet from Andrej Karpathy, asks an interesting question: are we witnessing the emergence of a new programming paradigm?
Here is the text of Karpaty's original tweet:
“I love the idea of Software 3.0. Programming moves from preparing datasets to preparing queries that allow the meta-learning system to "understand" the essence of the task it needs to perform. LOL "[Love the idea for Software 3.0. Programming moving from curating datasets to curating prompts to make the meta learner "get" the task it's supposed to be doing. LOL].
Developing Karpaty's idea, Branuen writes:
« GPT-3 [ ] , : , , , ( GPT-2); , , , [prompt], , , «» - , , . , , «» «», GPT-3 . « » , : , , , , , , , , , ».
Since our model "saw" github and StackOverflow in the learning process, it is quite capable of writing code (sometimes not devoid of very deep meaning):
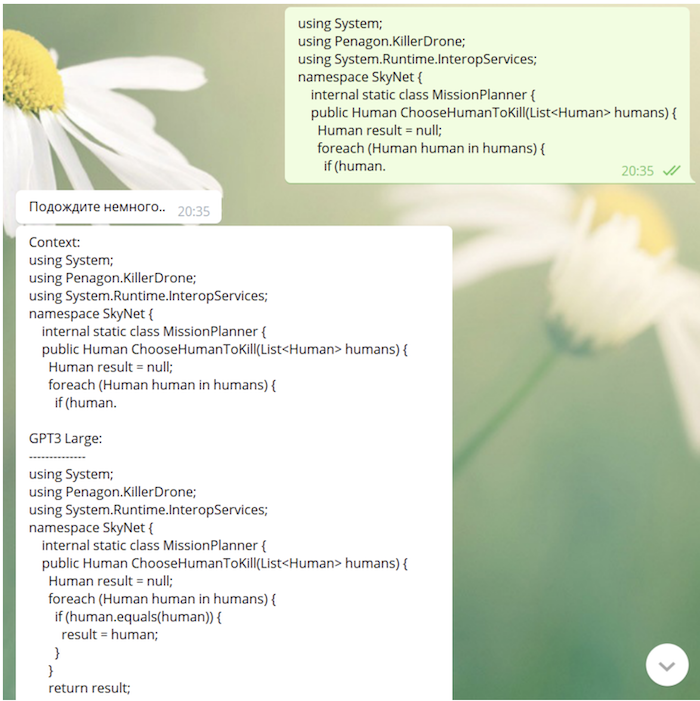
What's next
This year we will continue to work on giant transformer models. Further plans are related to the further expansion and cleaning of datasets (they, in particular, will include snapshots of the arxiv.org preprint service for scientific publications and the PubMed Central research library, specialized dialog datasets and datasets on symbolic logic), increasing the size of trained models, as well as using improved tokenizer.
We hope that the publication of trained models will spur the work of Russian researchers and developers who need super-powerful language models, because on the basis of ruGPT-3 you can create your own original products, solve various scientific and business problems. Try using our models, experiment with them and be sure to share with all the results you get. Scientific progress makes our world better and more interesting, let's improve the world together!