

New data landscape - new data storage
The intensity of data manipulation is increasing across all industries. And the banking sector is a clear illustration of this. Over the past few years, the number of banking transactions has increased more than tenfold. As the BCG research shows , in Russia alone, in the period from 2010 to 2018, the number of non-cash transactions using plastic cards showed more than thirtyfold growth - from 5.8 to 172 per person per year. The point is, first of all, the triumph of micropayments: most of us have become akin to online banking, and the bank is now at hand - on the phone.
The IT infrastructure of a credit institution must be ready for such a challenge. And this is really a challenge. Among other things, if earlier the bank needed to ensure the availability of data only during its working hours, now it is 24/7. Until recently, 5ms was considered an acceptable norm for latency, so what? Now even 1 ms is too much. For modern storage systems, the target is 0.5ms.
The same is with reliability: in the 2010s, an empirical understanding was formed that it was enough to bring its level to the “five dozen” - 99.999%. True, this understanding has become outdated. In 2020, it's absolutely normal for businesses to demand 99.9999% for storage and 99.99999% for overall architecture. And this is not a whim at all, but an urgent need: either there is no time window for infrastructure maintenance, or it is tiny.

For clarity, it is convenient to project these indicators onto the plane of money. The easiest way is through the example of financial institutions. The diagram above shows how much each of the top 10 world banks earns in an hour. For the Industrial and Commercial Bank of China alone, this is no less than $ 5 million. Exactly how much will cost an hour of downtime of the IT infrastructure of the largest credit institution in China (and only lost profits are taken into account in the calculation!). From this perspective, it is clear that reducing downtime and increasing reliability, not only by a few percent - even by a fraction of a percent, are fully rationally justified. Not only for reasons of increasing competitiveness, but also simply for the sake of maintaining market positions.
Comparable changes are taking place in other industries. For example, in air travel: before the pandemic, air traffic only gained momentum from year to year, and many began to use it almost like a taxi. As for consumer patterns, society has a deeply rooted habit of total accessibility of services: upon arrival at the airport, we need a Wi-Fi connection, access to payment services, a map of the area, etc. As a result, the load on infrastructure and services in public spaces increased many times. And those approaches to it, infrastructure, construction, which we considered acceptable even a year ago, are rapidly becoming obsolete.

Is it too early to switch to All-Flash?
For solving the problems mentioned above, from the point of view of AFA performance, all-flash arrays, that is, arrays entirely built on flash, are the best fit. Unless, until recently, doubts persisted as to whether they are comparable in reliability with those assembled on the basis of HDD and with hybrid ones. After all, solid-state flash has a metric such as mean time between failures, or MTBF. Degradation of cells due to I / O operations, alas, is a given.
So the outlook for All-Flash was clouded by the question of how to prevent data loss in the event that SSDs are ordered to live long. Backing up is a usual option, but the recovery time would be unacceptably long based on modern requirements. Another way out is to establish a second level of storage on spindle drives, but this scheme loses some of the advantages of a "strictly flash" system.
However, the numbers say otherwise: the statistics of the giants of the digital economy, including Google, in recent years show that flash is much more reliable than hard drives. Moreover, both over a short period of time and over a long period: on average, it takes four to six years before flash drives fail. In terms of data storage reliability, they are in no way inferior to spindle magnetic drives, or even surpass those.
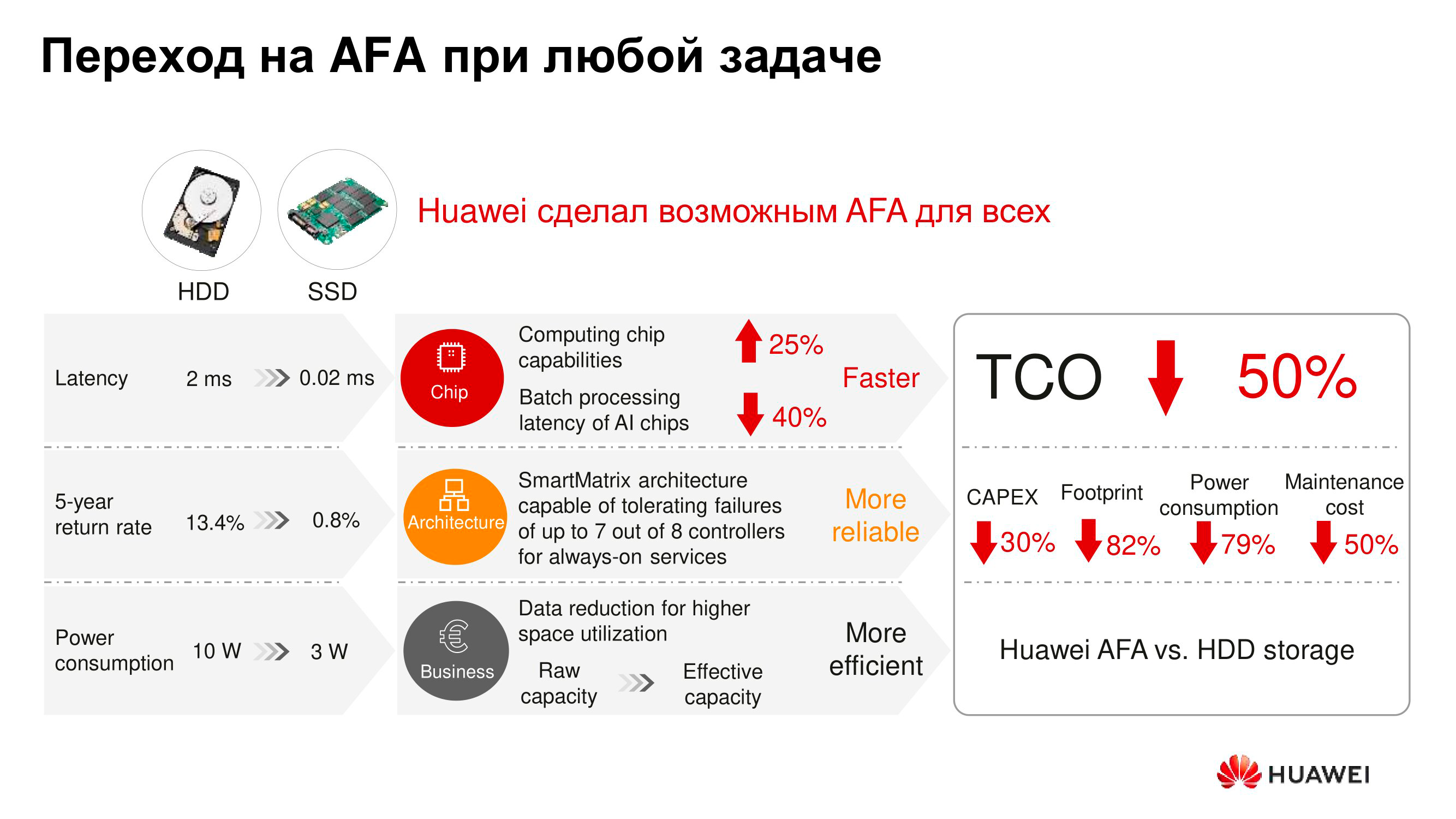
Another traditional argument in favor of spindle drives is their affordability. There is no doubt that the cost of storing a terabyte on a hard disk is still relatively low. And if you only take into account the cost of equipment, keeping a terabyte on a spindle drive is cheaper than on a solid-state drive. However, in the context of financial planning, it matters not only how much a particular device was purchased, but also what the total cost of owning it for a long time - from three to seven years.
From this point of view, everything is completely different. Even if we leave out of the brackets deduplication and compression, which, as a rule, are used on flash arrays and make their operation more economically profitable, such characteristics as rack space occupied by carriers, heat dissipation, and power consumption remain. And according to them, the flush wins over its predecessors. As a result, the TCO of flash storage systems, taking into account all parameters, is often almost half as much as in the case of arrays on spindle drives or with hybrids.
According to ESG reports, Dorado V6 All-Flash storage systems can actually achieve a 78% reduction in cost of ownership over a five-year interval - including through efficient deduplication and compression, and low power consumption and heat dissipation. The German analytical company DCIG also recommends them for use as the optimal TCO available today.
The use of solid-state drives makes it possible to save usable space, reduce the number of failures, reduce the time for solution maintenance, and reduce energy consumption and heat dissipation of the storage system. And it turns out that AFA in economic terms is at least comparable to traditional arrays on spindle drives, but often surpasses them.

Royal Flush from Huawei
Among our All-Flash storages, the top place belongs to the OceanStor Dorado 18000 V6 hi-end system. And not only among ours: in the industry as a whole, it holds the speed record - up to 20 million IPOS in the maximum configuration. In addition, it is extremely reliable: even if two controllers fly at once, or up to seven controllers one after another, or an entire engine at once, the data will survive. The considerable advantages of the "eighteen thousandth" are given by the AI wired into it, including the flexibility in managing internal processes. Let's see how all this is achieved.

To a large extent, Huawei has a head start because it is the only manufacturer on the market that makes data storage systems itself - completely and completely. We have our own circuitry, our own microcode, our own service.
The controller in OceanStor Dorado systems is built on the Kunpeng 920, a proprietary and manufactured Huawei processor. It uses the Intelligent Baseboard Management Controller (iBMC), also ours. The AI chips, namely the Ascend 310, which optimize failure predictions and give recommendations on settings, are also huavean, as well as the I / O boards - the Smart I / O module. Finally, the controllers in solid state drives are designed and manufactured by us. All this provided the basis for making an integrally balanced and high performance solution.

, . 40 OceanStor Dorado 18000 V6 metro- : IOPS, - .

NVMe
Huawei's latest storage systems support end-to-end NVMe, which we are focusing on for a reason. Traditionally used storage access protocols were developed in the hoary IT antiquity: they are based on SCSI commands (hello, 1980s!), Which pull along a lot of functions to ensure backward compatibility. Whichever method of access you take, the protocol overhead is colossal in this case. As a result, storages that use SCSI-related protocols have I / O latency that cannot be lower than 0.4–0.5 ms. In turn, being a protocol created for working with flash memory and getting rid of crutches for the sake of notorious backward compatibility, NVMe - Non-Volatile Memory Express - knocks latency down to 0.1 ms, moreover, not on storage systems, but on the entire stack, from host to drives. Not surprising,that NVMe is in line with data storages development trends for the foreseeable future. We also staked on NVMe - and are gradually moving away from SCSI. All Huawei storage systems produced today, including the Dorado line, support NVMe (although, as an end-to-end, it is implemented only on the advanced Dorado V6 series models).

FlashLink: a handful of technology
The cornerstone technology for the entire OceanStor Dorado line is FlashLink. More precisely, it is a term that encompasses an integral set of technologies that serve to ensure high performance and reliability. This includes deduplication and compression technologies, the functioning of the RAID 2.0+ data distribution system, the separation of "cold" and "hot" data, full-strip sequential data recording (random writes, with new and changed data, are aggregated into a large stack and written sequentially, which increases the speed read-write).
Among other things, FlashLink includes two important components - Wear Leveling and Global Garbage Collection. It is worth dwelling on them separately.
Virtually any SSD is a miniature storage system with a large number of blocks and a controller that ensures data availability. And it is provided, among other things, due to the fact that data from "killed" cells are transferred to "not killed" ones. This ensures that they can be read. There are various algorithms for this transfer. In general, the controller tries to balance the wear of all storage cells. This approach has a drawback. When data moves inside an SSD, the amount of I / O it performs is dramatically reduced. At the moment, this is a necessary evil.
Thus, if the system has a lot of solid-state drives, a "saw" appears on the graph of its performance, with sharp ups and downs. The trouble is that one drive from the pool can start data migration at any time, and the overall performance is removed at a time from all SSDs in the array. But Huawei engineers figured out how to avoid the "saw".
Fortunately, the controllers in the drives, the storage controller, and the microcode from Huawei are "native", these processes in OceanStor Dorado 18000 V6 are launched centrally, synchronously on all drives of the array. Moreover, at the command of the storage controller and precisely when there is no heavy load on I / O.
: , -, , , : Wear Leveling, .
Plus, the system controller sees what is happening in each cell of the drive, in contrast to the storage systems of competing manufacturers: they are forced to purchase solid-state media from third-party vendors, which is why cell-level detailing is not available to the controllers of such storages.
As a result, the OceanStor Dorado 18000 V6 has a very short period of performance loss during Wear Leveling, and it is performed mainly when no other processes are interfered with. This gives high, consistent performance on a consistent basis.

What makes the OceanStor Dorado 18000 V6 reliable
In modern data storage systems, four levels of reliability are distinguished:
- hardware, at the drive level;
- architectural, at the equipment level;
- architectural together with the software part;
- cumulative, referring to the decision as a whole.
Since, we recall, our company designs and manufactures all the components of the storage system itself, we ensure reliability at each of the four levels, with the ability to thoroughly track what is happening on which of them at the moment.

The reliability of the drives is guaranteed primarily by the previously described Wear Leveling and Global Garbage Collection. When an SSD looks like a black box to the system, it has no idea how cells wear out in it. For OceanStor Dorado 18000 V6, the drives are transparent, which makes it possible to balance evenly across all drives in the array evenly. Thus, it turns out to significantly extend the life of SSDs and secure a high level of reliability of their operation.

Also, additional redundant cells in it affect the reliability of the drive. And along with a simple reserve in the storage system, the so-called DIF cells are used, which contain checksums, as well as additional codes that allow each block to be saved from a single error, in addition to protection at the RAID array level.

The SmartMatrix solution is the key to architectural reliability. In short, these are four controllers that sit on a passive backplane as part of one engine. Two such engines - respectively, with eight controllers - are connected to common shelves with drives. Thanks to SmartMatrix, even if seven controllers out of eight cease to function, access to all data, both read and write, remains. And if you lose six of the eight controllers, you can even continue caching.

I / O cards on the same passive backplane are available to all controllers, both on the front-end and on the back-end. With this full-mesh connection scheme, no matter what fails, access to the drives is always preserved.

It is most appropriate to talk about architecture reliability in the context of failure scenarios that the storage system can protect against.
The storage will survive the situation without loss if two controllers "fall off", including simultaneously. Such stability is achieved due to the fact that any cache block certainly has two more copies on different controllers, that is, in total, it exists in three copies. And at least one is on a different engine. Thus, even if the entire engine stops working - with all four of its controllers - it is guaranteed that all the information that was in the cache memory will be saved, because the cache will be duplicated in at least one controller from the remaining engine. Finally, with a daisy-chain connection, you can lose up to seven controllers, and even if they are eliminated in blocks of two - and again, all I / O and all data from the cache memory will be saved.

When compared with hi-end storages from other manufacturers, it can be seen that only Huawei provides complete data protection and full availability even after the death of two controllers or the entire engine. Most vendors use a scheme with so-called controller pairs, to which drives are connected. Unfortunately, in this configuration, if two controllers fail, there is a risk of losing I / O access to the drive.

Alas, the failure of a single component is not objectively excluded. In this case, performance will slow down for a while: it is necessary to rebuild the paths and resume access for I / O operations relative to those blocks that either came for writing, but were not yet written, or were requested for reading. The OceanStor Dorado 18000 V6 has an average rebuild timing of approximately one second - significantly less than its closest analog in the industry (4 seconds). This is achieved thanks to the same passive backplane: when the controller fails, the others immediately see its input-output, and in particular which data block was not added; as a result, the nearest controller picks up the process. Hence the ability to restore performance in just a second. It should be added that the interval is stable: a second per controller,second for another, etc.

In the OceanStor Dorado 18000 V6 passive backplane, all boards are available to all controllers without any additional addressing. This means that any controller is capable of picking up I / O on any port. Whatever front-end port I / O comes to, the controller will be ready to work it out. Hence - the minimum number of internal transfers and a noticeable simplification of balancing.
Front-end balancing is performed using the multipathing driver, and balancing is additionally carried out within the system itself, since all controllers see all I / O ports.

Traditionally, all Huawei arrays are designed in such a way that they do not have a single point of failure. All its components can be replaced "hot" without rebooting the system: controllers, power modules, cooling modules, I / O boards, etc.

A technology such as RAID-TP also improves the reliability of the system as a whole. This is the name of a RAID group that allows you to hedge against the simultaneous failure of up to three drives. Moreover , a 1 TB rebuild consistently takes less than 30 minutes. Best recorded results - eight times faster than with the same amount of data on a spindle drive. Thus, it is possible to use extremely capacious drives, say, 7.68 or even 15 TB, and not worry about the reliability of the system.
It is important that the rebuild is carried out not in the spare drive, but in the spare space - the reserve capacity. Each drive has dedicated storage space used for disaster recovery. Thus, the restoration is carried out not according to the "many to one" scheme, but according to the "many to many" scheme, due to which it is possible to significantly speed up the process. And as long as there is free capacity, the recovery can be continued.

Separately, mention should be made of the reliability of a solution from several storages - in a metro-cluster, or, in Huawei's terminology, HyperMetro. Such schemes are supported on the entire model range of our data storage systems and can work with both file and block access. Moreover, on the block it functions both via Fiber Channel and Ethernet (including iSCSI).
In essence, we are talking about bi-directional replication from one storage system to another, in which the replicated LUN is assigned the same LUN-ID as the main one. The technology works primarily due to the consistency of caches from two different systems. Thus, for the host it is absolutely all the same which side it is from: here and there it sees the same logical disk. As a result, nothing prevents you from deploying a failover cluster spanning two sites.
For quorum, a physical or virtual Linux machine is used. It can be located on the third site, and the requirements for its resources are small. A common scenario is to rent a virtual site exclusively for hosting a quorum VM.
The technology also allows expansion: two storages - in a metro-cluster, an additional platform - with asynchronous replication.

Historically, many customers have formed a "storage zoo": a bunch of storage systems from different manufacturers, different models, different generations, with different functionality. However, the number of hosts can be impressive, and they are often virtualized. In such conditions, one of the priority tasks of administration is to quickly, uniformly and conveniently provide logical disks for hosts, preferably in such a way as not to delve into where these disks are physically located. This is exactly what our OceanStor DJ software solution is intended for, which can unified management of various storage systems and provide services from them without being tied to a specific storage model.

Same and AI
As already mentioned, the OceanStor Dorado 18000 V6 has built-in processors with artificial intelligence algorithms - Ascend. They are used, firstly, to predict failures, and secondly, to form recommendations for tuning, which also increases the performance and reliability of the storage.
The prediction horizon is two months: the AI machinery assumes that it will most likely happen during this time, is it time to make an expansion, change access policies, etc. Recommendations are given in advance, which makes it possible to schedule windows for system maintenance in advance.
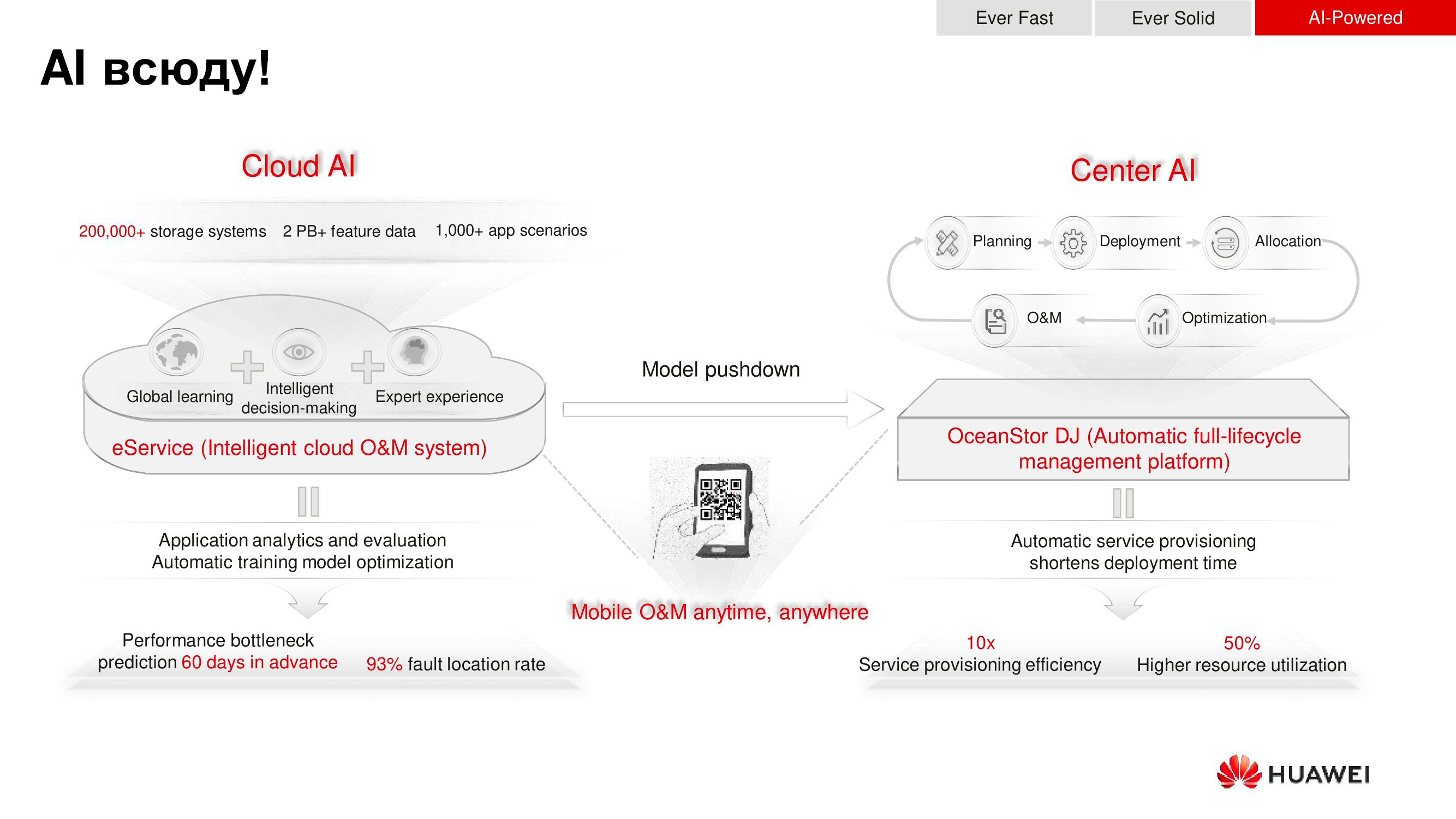
The next stage in the development of AI from Huawei involves bringing it to the global level. During service maintenance - failover or recommendation - Huawei aggregates information from logging systems from all storages of our customers. Based on the collected data, an analysis of occurred or potential failures is carried out and global recommendations are made - based not on the functioning of one particular storage system or even a dozen, but on what is happening and happening with thousands of such devices. The sample is huge, and based on it, AI algorithms begin to learn extremely quickly, which makes predictions more accurate.
Compatibility

In 2019-2020, there was a lot of innuendo about how our hardware interacts with VMware products. In order to finally stop them, we responsibly declare: VMware is a partner of Huawei. All imaginable tests were carried out for the compatibility of our hardware with its software, and as a result, on the VMware website in the hardware compatibility list, the currently available storage systems of our production are indicated without any reservations. In other words, with the VMware software environment, you can use Huawei storage, including Dorado V6, with full support.

The same goes for our collaboration with Brocade. We continue to interact and conduct interoperability tests for our products to ensure that our storage systems are fully interoperable with the latest Brocade FC switches.

What's next?
We continue to develop and improve our processors: they become faster, more reliable, their performance is growing. We are also improving AI chips - on their basis, among other things, modules are produced that accelerate deduplication and compression. Those who have access to our configurator may have noticed that in Dorado V6 models these cards are already available for order.
We are also moving towards additional caching on Storage Class Memory - non-volatile memory with especially low latencies, about ten microseconds per read. Among other things, SCM gives a performance boost, especially when working with big data and when solving OLTP problems. After the next update, SCM cards should become available for order.
And of course, file access functionality will be expanding across the entire Huawei data store lineup - stay tuned for our updates.