
A thorny and difficult path of a person who collided with the FSIS USRN Rosreestr. He is waiting for endless waiting for the browser to load, keys, captchas, intervals between requests of 5 minutes. Why would he suffer so much? He had already contributed his own money when he decided to work with this system and order his extracts. But no - getting an extract from the USRN is like undressing onions. The last step that awaits the sufferer - the downloaded, coveted extract is represented by a zip archive, in which, um, another archive and a sig file. And the statement file itself is already inside. But it's not easy to read it either - it's in xml. And in order for everything to grow together, it turns out to be necessary to download this xml along with sig to a special page of Rosreestr. And there, there is still a captcha waiting. And so with each statement! We will overcome this last pain today using python.
Task:
- unpack all zip in the folder,
- download by spec. link to Rosreestr,
- finally download !, a human-readable view of the statement.
So, initially in the folder there are downloaded zip archives of extracts:
After importing python modules:
import os
import zipfile
import webbrowser,time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
Let's unpack all zip archives and delete them so that they don't get confused with the contents:
zipFiles = []
sigFiles = []
for filename in os.listdir('.'):
if filename.endswith('.zip'):
zipfile.ZipFile(filename, 'r').extractall()
os.remove(filename)
We got zip archives and sig files for them, which will then be uploaded to the Rosreestr website:
Go to the main program loop for all files in the directory (in my case, "C: / 2"):
for filename in zipFiles:
act = browser.find_element_by_id('sig_file')
act.send_keys('C:\\2\\'+str(filename)+'.sig')
act = browser.find_element_by_id('xml_file')
# zip
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
# xml
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
# xml
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input(" : "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text(' ')
act.click()
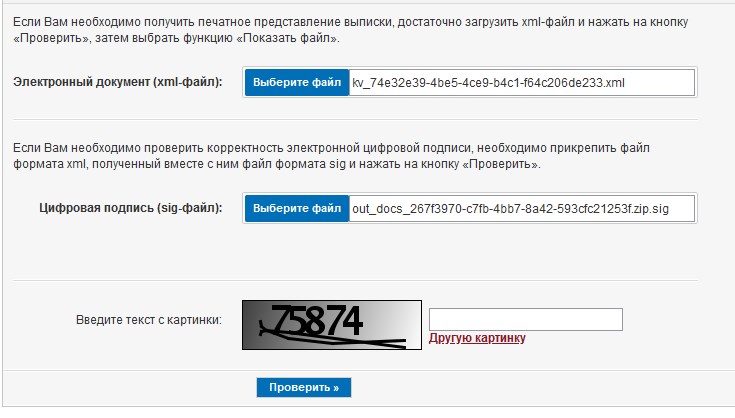
After the successful loading of the Rosreestr portal page rosreestr.gov.ru/wps/portal/cc_vizualisation , the program will find the zip archive in the directory, get the xml statement file from there and insert it into the required field on the site. The program will do the same with the sig file attached to the xml:
Next, the program will wait for the captcha to be entered:
After the user enters the captcha, it will send it to the site and click on the download link for the already "normal" extract from the USRN:
A window will open in which the finished extract, which can be saved in html or by pressing CTRL + P in Chrome - in pdf.
It remains to add auto-solving captcha and auto-download of human-readable extracts. But this is the simplest thing here, isn't it?
The program code is here .