According to popular belief, extracting text from PDFs should not be so difficult. After all, here it is, the text, right before our eyes, and people constantly and with great success perceive the content of PDF. Where does the difficulty in automatic text extraction come from?
It turns out that just as working with people's names is difficult for algorithms due to many edge cases and incorrect assumptions, working with PDF is difficult due to the extreme flexibility of the PDF format.
The main problem is that PDF was not intended as a format for data input - it was developed as an output channel, allowing for fine-tuning the appearance of the final document.
Basically, the PDF format consists of a stream of instructions describing how an image is created on a page. In particular, text data is not stored as paragraphs - or even words - but as characters drawn at specific locations on the page. As a result, when converting text or Word document to PDF, most of the semantics of the content is lost. The entire internal structure of the text turns into an amorphous soup of characters floating on the page.
By filling FilingDB, we have extracted text data from tens of thousands of PDF documents. In the process, we observed how absolutely all our assumptions about the structure of PDF files turned out to be wrong. Our mission was especially difficult because we had to process PDF documents coming from different sources with completely different styles, fonts and looks.
The following describes what features of PDF files make it difficult or even impossible to extract text from them.
PDF read protection
You may have come across PDF files that prohibit copying text content from them. For example, this is what the SumatraPDF program produces when trying to copy text from a copy-protected document:

It is interesting that the text is visible, but the viewer refuses to transfer the selected text to the clipboard.
This is accomplished with several "access permissions" flags, one of which controls the copy permission. It is important to understand that the PDF file itself does not force this - its content does not change from this, and the task of its implementation lies entirely with the viewer.
Naturally, this does not really protect against extracting text from PDF, since any sufficiently advanced library for working with PDF will allow the user to either change these flags or ignore them.
Characters outside of pages
Oftentimes, a PDF contains more textual data than is shown on the page. Take this page from Nestle's 2010 Annual Report.
There is more text attached to this page than is visible. In particular, the following can be found in the content associated with it:
KitKat celebrated its 75th birthday in 2010, but remains young and trendy with over 2.5 million Facebook fans. Its products are sold in over 70 countries, and sales are growing well in developed countries and emerging markets such as the Middle East, India and Russia. Japan is the company's second largest market.
This text is off-page, so most PDF viewers won't show it. However, the data is there and can be retrieved programmatically.
This is sometimes due to last-minute decisions to replace or remove text during the approval process.
Small or invisible characters
Sometimes, very small or even invisible characters can be found on the PDF page. For example, here is a page from the 2012 Nestle report.

The page has small white text on a white background that says:
Wyeth Nutrition logo Identity Guidance to markets
Vevey Octobre 2012 RCC / CI & D
This is sometimes done to improve accessibility, for the same purpose as the alt tag in HTML.
Too many spaces
Sometimes additional spaces are inserted between letters of words in PDF. This is probably done for kerning purposes (changing the spacing between characters).
For example, the 2013 Hikma Pharma report contains the following text:

If you copy it, we get:
ch a i r m a n ' s s tat em en tIn general, it is difficult to solve the problem of reconstruction of the original text. Our most successful approach is using optical character recognition, OCR.
Not enough spaces
Sometimes the PDF is missing spaces or has been replaced with a different character.
Example 1: The following extract is taken from the SEB Annual Report 2017.

Extracted text:
TenyearsafterthefinancialcrisisstartedExample 2: Eurobank 2013 report contains the following:

Extracted text:
On_April_7,_2013,_the_competent_authoritiesAgain, OCR is the best choice for these pages.
Built-in fonts
PDF works with fonts in a complex way, to put it mildly. To understand how text data is stored in PDF, we first need to understand glyphs, glyph names, and fonts.
- A glyph is a set of instructions describing how to draw a character or letter.
- – , . , « » ™ «» «».
- – . , , , «», .
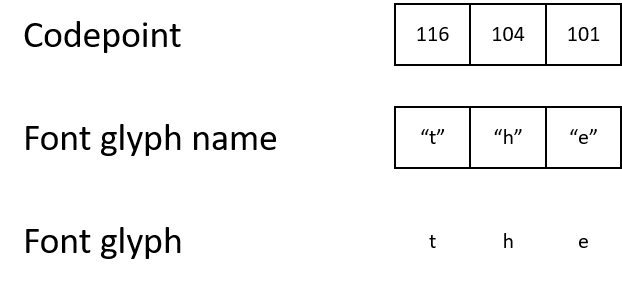
In PDF, characters are stored as numbers, character codes [codepoints]. To understand what needs to be displayed on the screen, the renderer must follow the chain from the character code to the name of the glyph, and then to the glyph itself.
For example, a PDF might contain a character code 116, which it maps to the name of the glyph "t", which in turn maps to a glyph that describes how to display the character "t".
Most PDFs use the standard character encoding. A character encoding is a set of rules that give meaning to the character codes themselves. For instance:
- ASCII and Unicode use the character code 116 to represent the letter "t".
- Unicode maps character code 9786 to the glyph "white smiley", which is displayed as ☺, but ASCII does not define such a code.
However, the PDF document sometimes uses its own character encoding and special fonts. It may sound strange, but the document may denote the letter "t" with character code 1. It will map character code 1 to the glyph name "c1", which will be mapped to a glyph that describes how to display the letter "t".
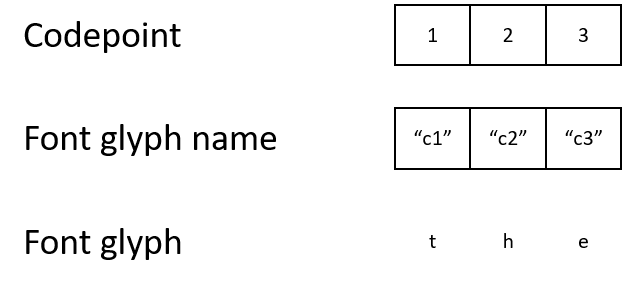
While the end result is no different for a human, the machine will get confused by these character codes. If the character codes do not match the standard encoding, it is almost impossible to programmatically understand what codes 1, 2, or 3 mean.
Why would a PDF include non-standard fonts and encoding?
- One reason is to make it harder to extract text.
- – . , PDF . PDF , .
One way to get around this is to extract font glyphs from the document, run them through OCR, and map the font to Unicode. This will allow you to translate the font-related encoding into Unicode, for example: character code 1 corresponds to the name "c1", which, according to the glyph, should mean "t", which corresponds to Unicode code 116.
The encoding map you just done - the one that matches the numbers 1 and 116 - is called the ToUnicode card in the PDF standard. PDF documents can contain their own ToUnicode cards, but this is not required.
Recognition of words and paragraphs
Reconstructing paragraphs and even words from the amorphous symbolic soup of PDFs is a daunting task.
A PDF document contains a list of characters on a page, and it is up to the consumer to recognize words and paragraphs. Humans are naturally effective at this because reading is a common skill.
The most commonly used grouping algorithm is to compare the size, position, and alignment of characters to determine what is a word or paragraph.
The simplest implementations of such algorithms can easily reach O (n²) complexity, which can take a long time to process densely packed pages.
Order of text and paragraphs
Recognizing text and paragraph order is challenging for two reasons.
First, sometimes there is simply no right answer. While documents with regular typographic set with one column have a natural reading sequence, documents with bolder arrangement of elements are more difficult to determine. For example, it is not entirely clear whether the next insert should come before, after or in the middle of the article next to which it is located:

Second, even when the answer is clear to a person, computers can be very difficult to determine the exact order of paragraphs - even using AI. You may find this statement a bit daring, but in some cases the correct sequence of paragraphs can only be determined by understanding the content of the text.
Consider this arrangement of components in two columns, which describes the preparation of a vegetable salad.

In the Western world, it is reasonable to assume that reading is from left to right and top to bottom. Therefore, without studying the content of the text, we can reduce all the options to two: ABCD and ACB D.
After examining the content, understanding what it says, and knowing that vegetables are washed before slicing, we can understand that the correct order would be ACB D. It is extremely difficult to determine this algorithmically.
At the same time, "in most cases" an approach that relies on the order in which the text is stored within the PDF document works. It usually follows the order in which the text is inserted at creation time. When large chunks of text contain many paragraphs, they usually follow the order the author intended.
Embedded images
Often, part of the content of the document (or the entire document) turns out to be a scanned image. In such cases, there is no textual data in it, and you have to resort to OCR.
For example, the 2011 Yell Annual Report is only available as a scan:

Why not just recognize everything?
While OCR can help with some of the issues described, it also has its drawbacks.
- Long processing time. Running OCR on a scan from PDF usually takes an order of magnitude longer (or even longer) than extracting text directly from PDF.
- Difficulties with non-standard characters and glyphs. It is difficult for OCR algorithms to work with new characters - emoticons, asterisks, circles, squares (in lists), superscripts, complex mathematical symbols, etc.
- . , PDF-, , . .
So far, we have not yet mentioned how difficult it is to confirm that the text was extracted correctly or as expected. We have found that it is best to run an extensive set of tests that study both basic metrics (text length, page length, ratio of words to spaces) and more complex (percentage of English words, percentage of unrecognized words, percentage of numbers), as well as monitor warnings such as suspicious or unexpected characters.
What advice can we have for extracting text from PDF? First of all, make sure that the text doesn't have a more convenient source.
If the data you are interested in comes only in PDF format, then it is important to understand that this problem seems simple only at first glance, and it may not be possible to solve it with 100% accuracy.