Task
Given: a project based on OpenWRT (and it is based on BuildRoot) with one additional repository connected as feed. Task: merge an additional repository with the main one.
Background
We make routers and, one day, we wanted to give customers the ability to include their applications in the firmware. In order not to suffer with the allocation of the SDK, toolchain and the accompanying difficulties, we decided to put the entire project on github in a private repository. Repository structure:
/target //
/toolchain // gcc, musl
/feeds //
/package //
...
It was decided to transfer some of the applications of our own development from the main repository to the additional one, so that no one spied. We did it all, put it on github and it became good.
Much water has flown under the bridge since that time…
The client has been gone for a long time, the repository has been removed from github, and the very idea of giving clients access to the repository is rotten. However, two repositories remained in the project. And all scripts / applications, one way or another related to git, are compelled to get complicated to work with such a structure. Simply put, it is technical debt. For example, to ensure reproducibility of releases, you need to commit to the primary repository a file, secondary.version, with a hash from the second repository. Of course, the script does it, and it is not very difficult for it. But, there are a dozen of such scripts, and they are all more complicated than they could be. In general, I made a volitional decision to merge the secondary repository back into the primary. At the same time, the main condition was set - to preserve the reproducibility of releases.
Once such a condition is set, then trivial merging methods, such as committing everything from the secondary separately and then, from above, making a merge commit of two independent trees, will not work. You have to open the hood and get your hands dirty.
Git data structure
First, what is a git repository like? This is a database of objects. Objects are of three types: blobs, trees, and commits. All objects are addressed by the sha1 hash of their content. A blob is, stupidly, data without any additional attributes. A tree is a sorted list of links to trees and blobs of the form “<right> <type> <hash> <name>” (where <type> is either blob or tree). Thus, a tree is like a directory in the file system, and a blob is like a file. A commit contains the name of the author and committer, the date of creation and addition, a comment, a hash of the tree, and an arbitrary number (usually one or two) of links to parent commits. These links to parent commits turn the object base into an acyclic digraph (among foreigners, known as DAG).Read in detailhere :
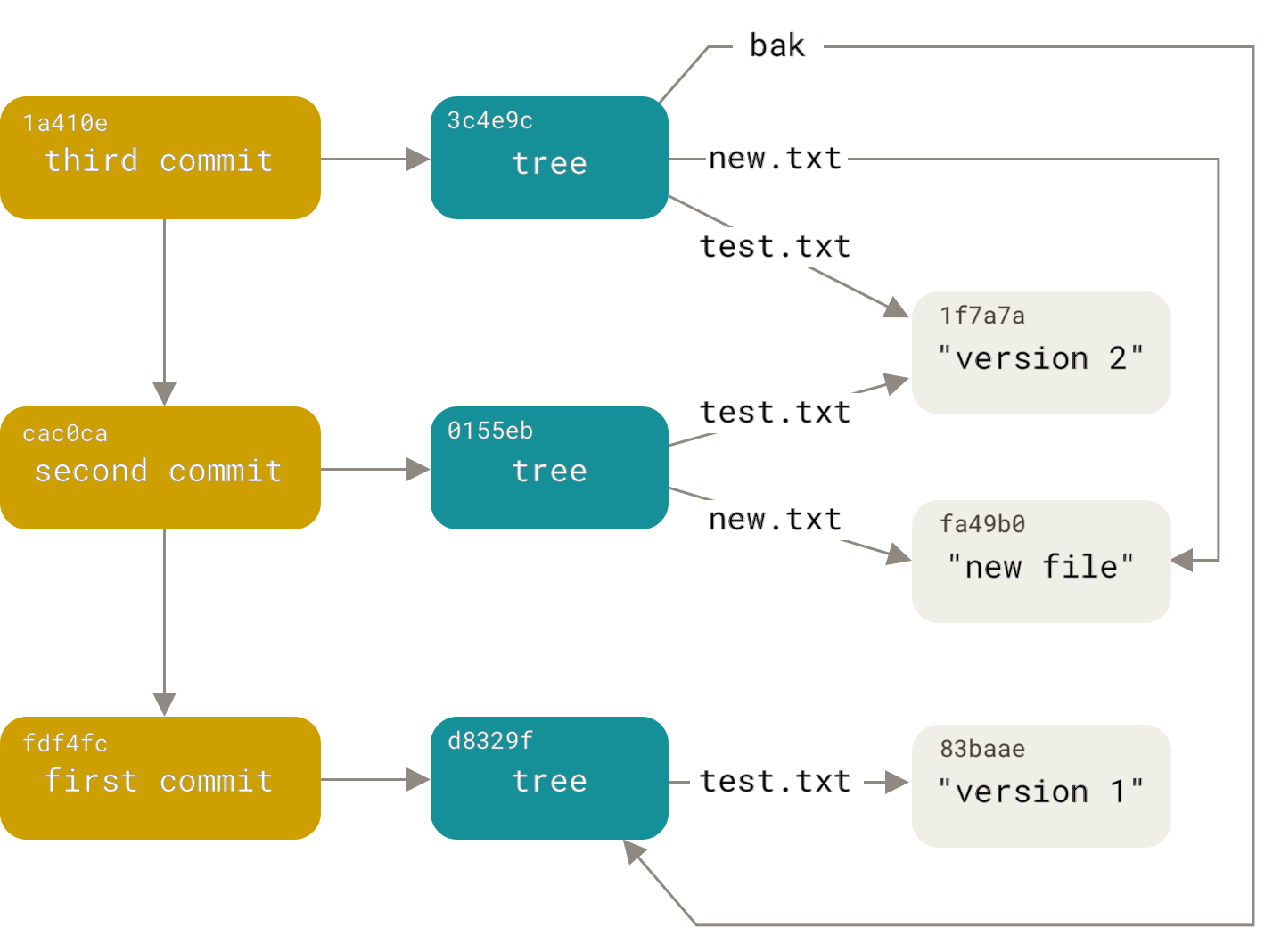
Thus, our task has been transformed into the task of constructing a new digraph, repeating the structure of the old one. But with the replacement of the commits of the secondary.version file with commits from the additional repository, the

development process is far from the classic gitflow. We commit everything to the master, trying not to break it at the same time. We make builds from there. If necessary, we make stabilizing branches, which we then merge back into the master. Accordingly, the repository graph looks like a bare trunk of a sequoia braided with vines.
Analysis
The task naturally breaks down into two stages: analysis and synthesis. Since for synthesis it is necessary, obviously, to run from the very moment of allocation of the secondary repository to all tags and branches, inserting commits from the second repository, then at the analysis stage it is necessary to find places where to insert secondary-commits and these commits themselves. So, you need to build a reduced graph, where the nodes will be the commits of the main graph that change the secondary.version file (key commits). Moreover, if the nodes of this git refer to parents, then in the new graph, references to descendants are needed. I create a named tuple:
node = namedtuple(‘Node’, [‘primary_commit’, ‘secondary_commit’, ‘children’])
necessary reservation
, . , .
I put it in the dictionary:
master_tip = repo.commit(‘master’)
commit_map = {master_tip : node(master_tip, get_sec_commit(master_tip), [])}I put all the commits that change the secondary.version there:
for c in repo.iter_commits(all=True, path=’secondary.verion’) :
commit_map[c] = node(c, get_sec_commit(c), [])And I build a simple recursive algorithm:
def build_dag(commit, commit_map, node):
for p in commit.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
build_dag(p, commit_map, commit_map[p])
else :
build_dag(p, commit_map, node)That is, as it were, I stretch the key knots into the past and hook them up to new parents.
I run it and ... RuntimeError max recursion depth exceeded
How did it happen? Are there too many commits? git log and wc know the answer. Total commits since the split are about 20,000, and those affecting secondary.version - almost 700. The recipe is known, a non-recursive version is needed.
def build_dag(master_tip, commit_map, master_node):
to_process = [(master_tip, master_node)]
while len(to_process) > 0:
c, node = to_process.pop()
for p in c.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
to_process.append(p, commit_map[p])
else :
to_process.append(p, node)(And you said that all these algorithms are needed only for the interview to pass!) I
launch it, and ... it works. A minute, five, twenty ... No, you can't take that long. I stop. Apparently, each commit and each path is processed many times. How many branches are there in the tree? It turned out that there are 40 branches in the tree and, accordingly,different paths only from the master. And there are many paths leading to a significant portion of key commits. Since I don't have thousands of years in store, I need to change the algorithm so that each commit is processed exactly once. To do this, I add a set, where I mark each processed commit. But there is a small problem: with this approach, some of the links will be lost, since different paths with different key commits can go through the same commits, and only the first one will go further. To get around this problem, I replace the set with a dictionary, where the keys are commits, and the values are lists of reachable key commits:
def build_dag(master_tip, commit_map, master_node):
processed_commits = {}
to_process = [(master_tip, master_node, [])]
while len(to_process) > 0:
c, node, path = to_process.pop()
p_node = commit_map.get(c)
if p_node :
commit_map[p].children.append(p_node)
for path_c in path :
if all(p_node.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(p_node)
path = []
node = p_node
processed_cmmts[c] = []
for p in c.parents :
if p != root_commit and and p not in processed_cmmts :
newpath = path.copy()
newpath.append(c)
to_process.append((p, node, newpath,))
else :
p_node = commit_map.get(p)
if p_node is None :
p_nodes = processed_cmmts.get(p, [])
else :
p_nodes = [p_node]
for pn in p_nodes :
node.children.append(pn)
if all(pn.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[c]) :
processed_cmmts[c].append(pn)
for path_c in path :
if all(pn.trunk_commit != nc.trunk_commit
for nc in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(pn)As a result of this artless exchange of memory for a time, the graph is built in 30 seconds.
Synthesis
Now I have a commit_map with key nodes linked to a graph via child links. For convenience, I will transform it into a sequence of pairs (ancestor, descendant) . The sequence must be guaranteed that all pairs where a node occurs as a child are located before any pair where a node occurs as an ancestor. Then you just need to go through this list and commit first commits from the main repository, and then from the additional one. Here you need to remember that the commit contains a link to the tree, which is the state of the file system. Since the additional repository contains additional subdirectories in the package / directory, then it will be necessary to create new trees for all commits. In the first version, I just wrote blobs to files and asked the git to build an index on the working directory. However, this method was not very productive. There are still 20,000 commits, and each one needs to be committed again. So performance matters a lot. A little research into the internals of GitPython led me to the gitdb.LooseObjectDB class , which allows direct access to git repository objects. With it, blobs and trees (and any other objects, too) from one repository can be written directly to another. A wonderful property of the git object database is that the address of any object is a hash of its data. Therefore, the same blob will have the same address, even in different repositories.
secondary_paths = set()
ldb = gitdb.LooseObjectDB(os.path.join(repo.git_dir, 'objects'))
while len(pc_pairs) > 0:
parent, child = pc_pairs.pop()
for c in all_but_last(repo.iter_commits('{}..{}'.format(
parent.trunk_commit, child.trunk_commit), reverse = True)) :
newparents = [new_commits.get(p, p) for p in c.parents]
new_commits[c] = commit_primary(repo, newparents, c, secondary_paths)
newparents = [new_commits.get(p, p) for p in child.trunk_commit.parents]
c = secrepo.commit(child.src_commit)
sc_message = 'secondary commits {}..{} <devonly>'.format(
parent.src_commit, child.src_commit)
scm_details = '\n'.join(
'{}: {}'.format(i.hexsha[:8], textwrap.shorten(i.message, width = 70))
for i in secrepo.iter_commits(
'{}..{}'.format(parent.src_commit, child.src_commit), reverse = True))
sc_message = '\n\n'.join((sc_message, scm_details))
new_commits[child.trunk_commit] = commit_secondary(
repo, newparents, c, secondary_paths, ldb, sc_message)The commit functions themselves:
def commit_primary(repo, parents, c, secondary_paths) :
head_tree = parents[0].tree
repo.index.reset(parents[0])
repo.git.read_tree(c.tree)
for p in secondary_paths :
# primary commits don't change secondary paths, so we'll just read secondary
# paths into index
tree = head_tree.join(p)
repo.git.read_tree('--prefix', p, tree)
return repo.index.commit(c.message, author=c.author, committer=c.committer
, parent_commits = parents
, author_date=git_author_date(c)
, commit_date=git_commit_date(c))
def commit_secondary(repo, parents, sec_commit, sec_paths, ldb, message):
repo.index.reset(parents[0])
if len(sec_paths) > 0 :
repo.index.remove(sec_paths, r=True, force = True, ignore_unmatch = True)
for o in sec_commit.tree.traverse() :
if not ldb.has_object(o.binsha) :
ldb.store(gitdb.IStream(o.type, o.size, o.data_stream))
if o.path.find(os.sep) < 0 and o.type == 'tree': # a package root
repo.git.read_tree('--prefix', path, tree)
sec_paths.add(p)
return repo.index.commit(message, author=sec_commit.author
, committer=sec_commit.committer
, parent_commits=parents
, author_date=git_author_date(sec_commit)
, commit_date=git_commit_date(sec_commit))
As you can see, the commits from the secondary repository are added in bulk. At first, I made sure that individual commits were added, but (suddenly!) It turned out that sometimes a newer key commit contains a previous version of the secondary repository (in other words, the version is rolled back). In such a situation, the iter_commit method passes and returns an empty list. As a result, the repository is incorrect. Therefore, I just had to commit the current version.
The history of the appearance of the all_but_last generator is interesting. I omitted the description, but it does exactly what you expect. At first there was just a challenge
repo.iter_commits('{}..{}^'.format(parent.trunk_commit, child.trunk_commit), reverse = True)In general, everything ended well. The entire script fit into 300 lines and ran in about 6 hours. Moral: GitPython is convenient to do all sorts of cool things with repositories, but it's better to treat the technical debt in a timely manner