Today we have a physical and technical conversation with Mikhail Burtsev , the head of the laboratory of neural networks at MIPT. His research interests include neural network learning models, neurocognitive and neurohybrid systems, evolution of adaptive systems and evolutionary algorithms, neurocontrollers and robotics. All this will be discussed.

- How did the history of the Laboratory of Neural Networks and Deep Learning at Phystech begin?
- In 2015, I took part in an initiative of the Agency for Strategic Initiatives (ASI) called "Foresight Fleet" - this is such a multi-day platform for discussion under the National Technical Initiative. The key topic concerned the technologies that need to be developed in order for companies to appear in Russia with the potential to take leading positions in global markets. The main message was that it is extremely difficult to enter the formed markets, but technologies open up new territories and new markets, and it is precisely on them that we need to enter.
And so we sailed on a motor ship along the Volga and discussed what technologies could help create such markets and break the current technological barriers. And in this discussion about the future, the topic with personal assistants has grown. It is clear that we have already started using them - Alexa, Alice, Siri ... and it was obvious that there are technical barriers in understanding between humans and computers. On the other hand, a lot of research developments have accumulated, for example in the field of reinforcement learning, in natural language processing. And it became clear: many difficult tasks are being better and better solved with the help of neural networks.
And I was just doing research on neural network algorithms. Based on the results of the foresight fleet discussions, we formulated the concept of a technology development project for the near future, which was later transformed into the iPavlov project. This was the beginning of my interaction with Phystech.
In more detail, we have formulated three tasks. Infrastructure - creating an open library for conducting dialogues with the user. The second is to conduct research in natural language processing. Plus the solution of specific business problems .
Sberbank acted as a partner, and the project itself was formed under the wing of the National Technical Initiative.
, 2015 -: deephack.me — , , - , . Open Data Science.
At the beginning of 2018, we published the first repository of our open library DeepPavlov, and over the past two years we have seen a steady increase in its users (it is focused on Russian and English): we have about 50% of installations from the USA, 20-30% from Russia. Overall, it turned out to be a rather successful open source project.
We are not only developing but also trying to contribute to the global research agenda on conversational AI. Realizing the need for academic competition in this area, we launched the Conversational AI Challenges series as part of NeuIPS, the leading machine learning conference.
Moreover, we not only organize competitions, but also participate. So, the team of our laboratory last year took part in a competition from Amazon called the Alexa Prize - creating a chat bot with which a person would be interested in talking for 20 minutes.
The next competition will start in November
This is a university competition, and the core of the participants was to consist of students and university staff. There were 350 teams in total, seven are selected for the top and three are invited based on the results of last year - we have made it to the top.
Our dialogue system conducted about 100 thousand dialogues with users in the United States and in the end had a rating of about 3.35-3.4 out of 5, which is quite good. This suggests that we have managed to form a world-class team at MIPT in a fairly short time.
Now the laboratory is carrying out projects with different companies, among the large ones these are Huawei and Sberbank. Projects in different directions: AutoML, neural network theory and, of course, our main direction - NLP.
- About the tasks that used to be difficult for machine learning: why did deep learning take off in solving these problems?
- Hard to tell. I will now describe my intuition in a slightly simplified way. The point is that if the model has a lot of parameters, then it surprisingly can generalize the results well to new data. In the sense that the number of parameters can be commensurate with the number of examples. For the same reason, classical ML has long resisted the pressure of neural networks - it seems that nothing good should come of it in this situation.
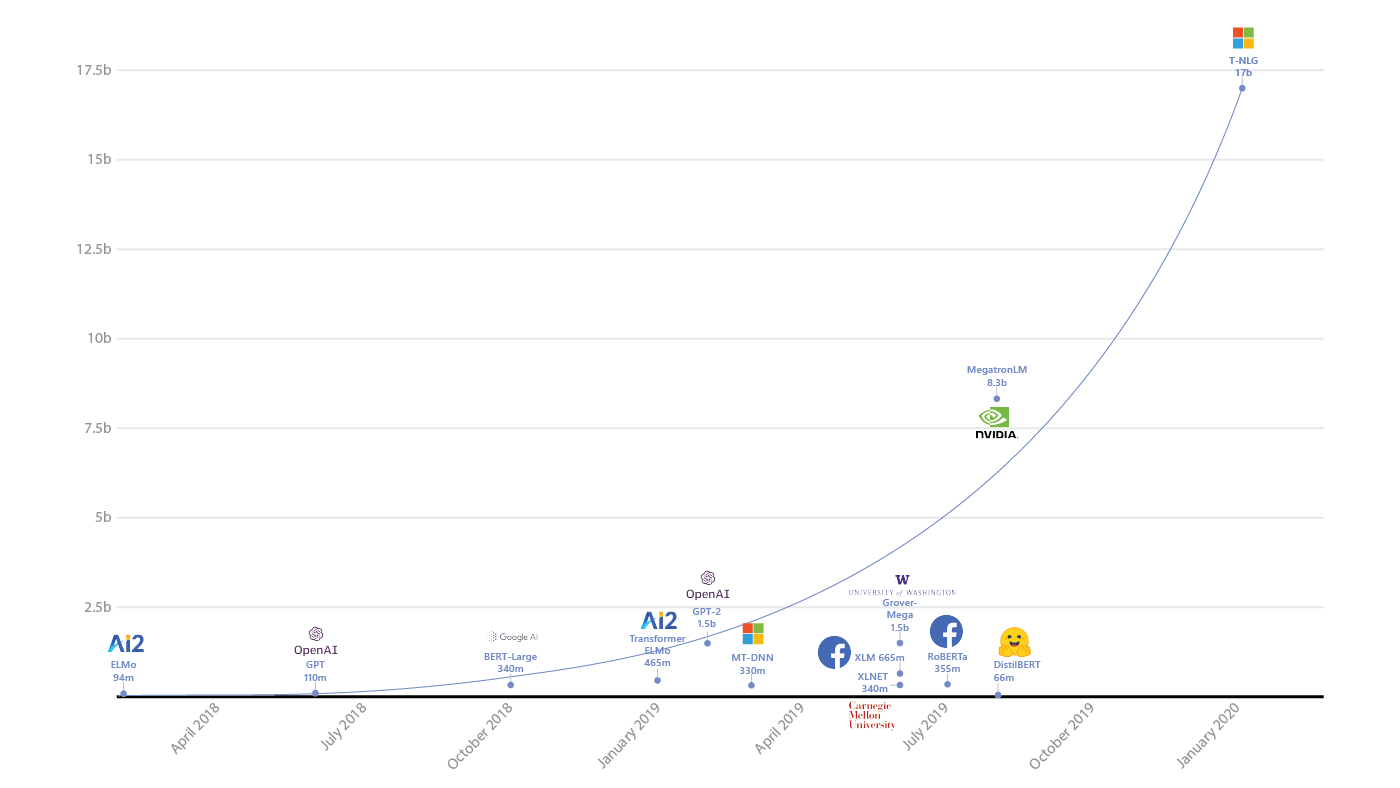
The rise of parameters in deep learning models ( source )
Surprisingly, they are not. Ivan Skorokhodov from our laboratory showed ( .pdf ) that almost any two-dimensional pattern can be found in the space of the neural network loss function.
You can choose a plane such that each point on this plane will correspond to one set of neural network parameters. And their loss will correspond to an arbitrary pattern, and, accordingly, you can pick up such neural networks that they will fall directly on this picture.
A very funny result. This suggests that even with such absurd restrictions, the neural network can learn the task assigned to it. That's about the kind of intuition here, yes.

Examples of patterns from the article by Ivan Skorokhodov
- In recent years, significant progress has been noticeable in the field of deep learning, but is the horizon already visible where we will bury ourselves in the limit of indicators?

The growth in the size of AI models and the resources they consume (source: openai.com/blog/ai-and-compute/ )
- In our NLP, the limit is not yet felt, although it seems that, for example, in reinforcement learning, something has already begun slip. That is, there have been no qualitative changes over the past couple of years. There was a big boom from Atari to AlphaGo with hybridization with Monte Carlo Tree Search, but now there is no immediate breakthrough.
But in NLP it is the other way around: recurrent networks, convolutional networks, and finally, the transformer architecture and GPT itself ( one of the newest and most interesting transformer models, often used to generate texts - author's note) Is already a purely extensive development. And here it seems that there is still a margin to achieve something new. Therefore, in NLP, the bar from above is not yet visible. Although, of course, it is almost impossible to predict anything here.
- If we imagine the development of languages and frameworks for machine learning, then we went from writing (conditionally) in pure numpy, scikit-learn to tensorflow, keras - the levels of abstraction grew. What's next for us?
— , : - . , , low level high level code: numpy . , , NLP : .
- Tensorflow / Pytorch — : .
- : NLP- — DeepPavlov.
- : — DeepPavlov Dream .
- A system for switching between skills / pipelines, including our DeepPavlov Agent.
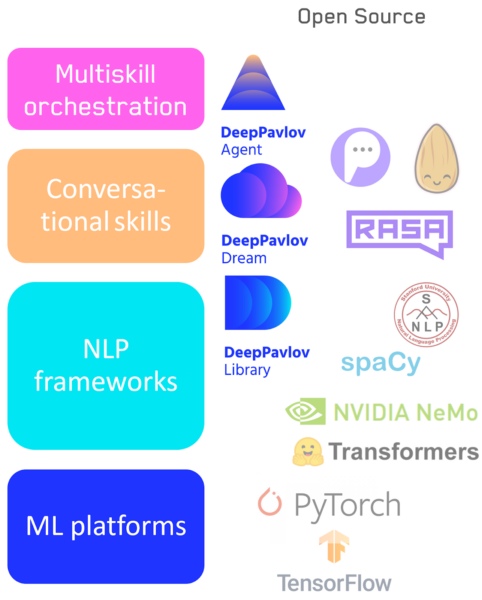
Conversational AI technology stack
Different applications and tasks require different flexibility of tools, and therefore I don't think that any elements of this hierarchy will go away. Both low-level and high-level systems will evolve as and when needed. For example, visual libraries that are not available to programmers, but also low-level libraries for developers will not go anywhere.
- Are social experiments now being carried out by analogy with the classical Turing test, where people must understand whether a neural network is in front of them or a person?
- Such experiments are carried out regularly. In the Alexa Challenge, a person had to assess the quality of a conversation, while he did not know who he was talking to - a bot or a person. So far, from the point of view of a live conversation, the difference between a machine and a person is significant, but it is decreasing every year. By the way, our article about this just came out in AI Magazine.
Outside the scientific community, this is done regularly. Recently, someone trained a GPT model, set up a Twitter account for her, and started posting responses. A lot of people signed up, the account gained popularity, and no one knew that it was a neural network.
Such a short format, like on Twitter, when the formulations are general and “profound”, just well suits the neural network inference system.
- What areas do you consider the most promising, where to expect a leap?
- ( Laughs ) I could say that it is in the unification of all my favorite directions that the leap will take place. I will try to describe in more detail within the framework of problematization. We have the current transformer based GPT models - they have no purpose in life, they just generate human-like text, completely aimless. And they cannot tie it to the situation and to goals in the context of the world itself.
And one of the ways is to create a binding of a logical view of the world to GPT, which has read a lot, a lot of text, and in it there are, indeed, a lot of logical connections. For example, through hybridization with "Wikidata" (this is a graph describing knowledge about the world, at the vertices of which are Wikipedia articles).
If we could connect the two so that GPT can use the knowledge base, that would be a leap forward.
The second approach to the problem of aimlessness of NLP models is based on the integration of understanding of human goals into them. If we have a model that can drive a generative language model tied to a knowledge graph, then we could train it to help a person achieve their goals. And such an assistant must understand the person through NLP, and the goals of the person, and the situation - then he needs to plan actions. And in planning, reinforcement learning works best.
How to combine and optimize all this is an open question.
And the last one is the search for neural network architectures. When, for example, using evolutionary approaches, we are looking in the space of architectures that are optimal for a given task. But all this will not be decided today - there is too much space to search.
From the good news: hardware is evolving very quickly and, perhaps, this will allow us in 5-10 years to combine neural network language models, knowledge graphs and reinforcement learning. And then we will have a quantum leap in the machine's understanding of man.
With the help of such an assistant, it will be possible to launch the solution of other tasks: image analysis, analysis of medical records or the economic situation, selection of goods.
Therefore, I would say that from a scientific point of view, in the next five years we will see rapid development in the field of hybridization - there are a lot of cool tasks.
Guys, the staff shortage will be huge, and there is a great chance to get new and interesting results, and also to influence the development of the industry. Get connected - you have to seize the moment!( The author actively supports this answer, since he deals with just such systems. )
- How to start diving into deep learning?
- The easiest way, it seems to me, is to take a course at deep learning school : initially it was intended for high school students, but it will be quite suitable for students. In general, this is a great undertaking, I helped with scheduling and give introductory lectures there.
I also recommend watching introductory courses from universities, doing tasks - there are just a lot of things on the Internet. The best of all the tools for "playing" is Colab from Google, there are millions of examples of tasks, you can figure it out and run the most modern solutions - without installing any software on your computer.
Another way is to compete on Kaggle. And also join Open Data Science - a Russian-speaking community for Data Science, where there are several deep learning channels. There are always people there who are ready to help with advice and code.
These are the main ways.
Leader-ID : friends, for the now launched selection for the accelerator for the promotion of AI projects, we have thought out a login option for indie developers. No, this does not change the basic conditions under which only teams participate in the intensive. But we have a lot of questions from individuals who do not have their own project now, but want to participate (and these are not only programmers, designers have a great interest in AI projects). And we found a solution: we will help to gather a team and like-minded people through a free online hackathon . It will start on October 10 at 12:00 and will end exactly one day later. On it, the bot will distribute you into teams, and then, under his guidance, you will go through the main stages of project development and submit it to the Archipelago 20.35. All the details are in your personal account, you just need to register in time.