- What exactly are we going to talk about? Not about primitive selects and joins - I think most of you already know about them.
We will talk about the real use of databases, what difficulties you can face and what you need to know as a backend developer. There will be a lot of information, here is the content. You do not need to directly thoroughly know the details of each of these points, but you need to know that this point exists.

And you need to know how what problems are solved so that when you have a task to build a structure, save data, you know which data model to choose and how to save it. Or suppose you have a problem, you see that the database is down, is slow, or there are data problems, inconsistency. Then you have to understand where to dig. That is, you need to know what concepts exist and from which side to approach the problems.

First, we'll talk about data. What is this anyway? There are many facts around us, a lot of information, but until they have been collected in any way, they are useless for us. We collect, structure and store them. And it is this stored structuring that is called data, and what stores it is called the database. But while this data is just collected somewhere, they are also basically useless for us. Therefore, there is a layer above the databases - the DBMS. This is what allows us to retrieve data, store it and analyze it. Thus, we turn the data that we receive into information that we can already display to the user. The user gains knowledge and applies it.

We will discuss how to structure information and facts, store them, in what form of data, in what model. And how to get them so that many users can simultaneously access the data and get the correct result, so that our final knowledge that we will apply is true and correct.

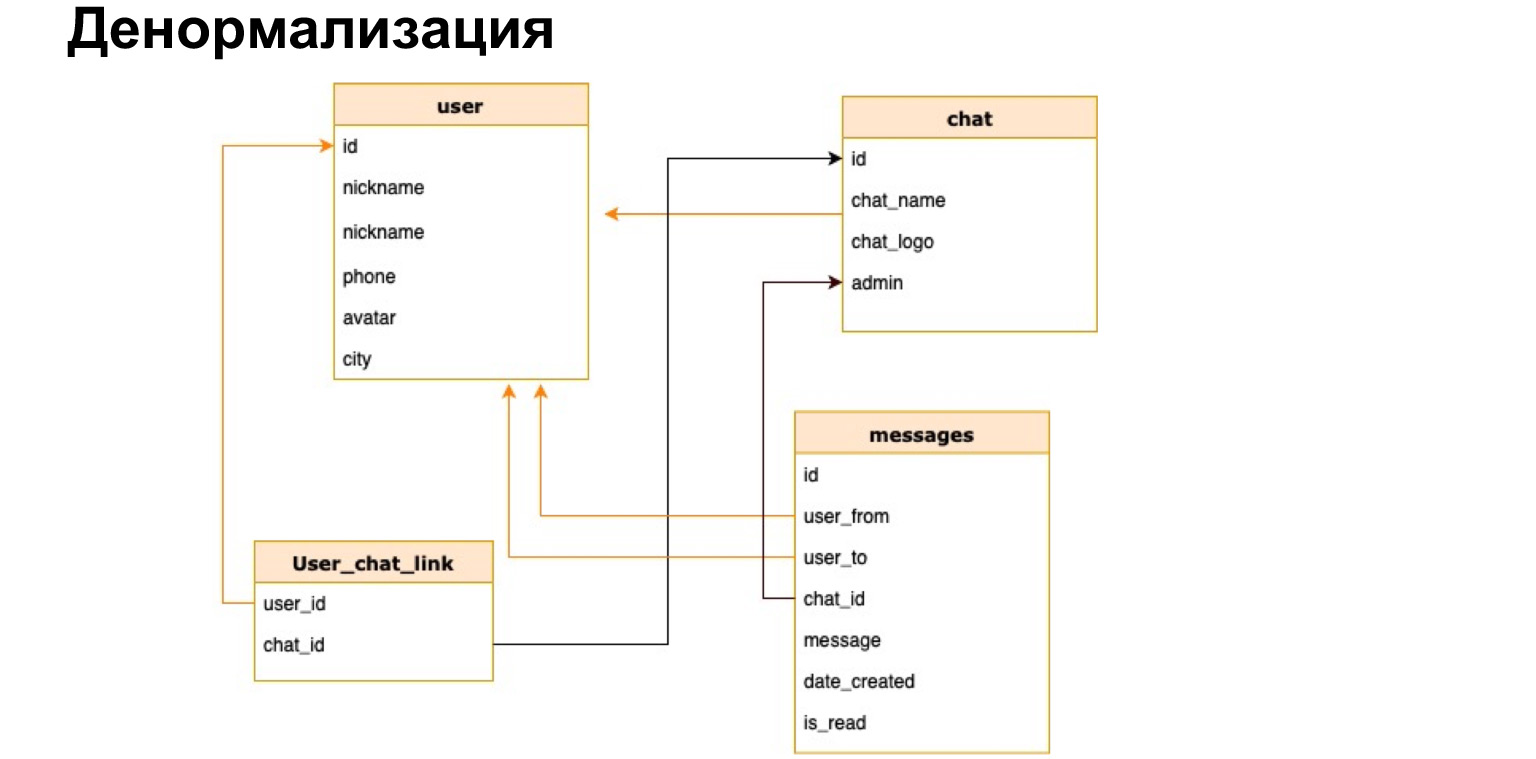
First, we will talk about relational databases. I think the relational model is familiar to many of you. It is a model of the type of tables and relationships between tables. Imagine that we have a messenger in which we write data and messages between users. We can write them all in one such large voluminous table, wide, where we will have a lot of repetitive data - from whom, who, to whom, in which chat. And we can write all this in various tables, that is, normalize our data, bring it into the third normal form.
There are notes and links on the slides. We will not go deep into every concept now. I will try not to talk about technical concepts that may be unfamiliar to you. But everything I say you will find in the slide notes. Including normalization, there will also be a reference, you can read it if you are not familiar with this concept.

In general terms, normalization is the breaking down of data into tables with the goal of making the data more structured. For example, there is now a table of user, messenger chat and messages. This structure ensures that messages from exactly the users we know and from the chats we know will be recorded here. That is, we ensure data integrity. We ensure the fact that we can always collect the whole picture. But at the same time, we store, for example, in the message table only IDs, only identifiers. Thus, we reduce the overall size of the database, making it smaller. Accordingly, we make it easier to write to this database. We don't need to constantly write to many tables. We just write in one table with the ID specialist.

If we talk about normalization, it generally greatly simplifies the vision of the system, because it is very graphical, and it immediately becomes clear to us what relationships we have between which tables.
We reduce the number of errors when writing data, because if we write a message in the messenger and we do not have such a user yet, then we will have to create one. But the final picture, the general data, will remain complete.
I have already said about reducing the size of the database. We do not have to write all the data about the user in the message table every time. To view the profile, we can simply go to the User table.
I also warned about an inconsistent dependency. These are just links to IDs of other tables, identifiers are unique values within one table. In another way, they are called primary keys, and when we have a link to these primary keys, then the link itself in another table is called a foreign key.
This structure also protects our data from accidental deletion. We cannot delete a user because, for example, he has a message. This is such a small, but safety net.
It would seem that we have made an excellent structure, everything is clear, everything is dependent, everything is integral. What else do you need to work with?

Let's imagine that we actually put it into operation, we have a lot of users and, accordingly, a lot of messages. They constantly communicate with each other. What's going on in our message table? It is constantly growing. And in order to search in non-data, we need to constantly sort through absolutely all messages, check whether they are from this user or not, in this chat or not, and only then display them.
Naturally, the more users, the more messages, the longer the search requests will take. We need a solution that allows us to quickly search for messages in the table.
For such a case, indexes are used to speed up the search. The simplest association with indexes is the content in a book. If you need to find information in a book, you can just flip through the book, or you can go to the table of contents. Indexes are sort of a table of contents.
There is also a good example with a phone book. You can click on a letter on your phone, and you will be immediately thrown by reference to surnames starting with this letter. Database indexes work in a very similar way. Let's see our table with messages and how we will get this data.

Please pay attention to how we will work with data. Not with what rows we have in the table, but in general. Indexes are built on the basis of what queries you make.
Let's imagine that we mainly make requests by chat, that is, we find out what messages are in this chat. Let's build the index exactly on the chat column. Database indexes are a separate structure. The table is independent of it. That is, you can delete and rebuild the index at any time, and the table will not suffer from this.
Here you can see that we have selected, put an index on the column, and we have a separate structure, which has already slightly reduced the number of entries, because there are already several messages in chat 11. The DBMS provides a quick search in this little chat table. How it's done? Naturally, the search is not a simple search. There are many fast search algorithms, we will take a look at one of the most popular algorithms that are used by default in most databases. It is a balanced tree.

How does it work? We have a chat number, this is an integer value, and the tree is built according to the following principle: what is less to the left of the node, more values to the right of the node. What does this structure give us? If you look at the summary sheets of this tree, then all the values at the bottom are ordered. This is a huge plus in productivity gains. Now I'll show you why.
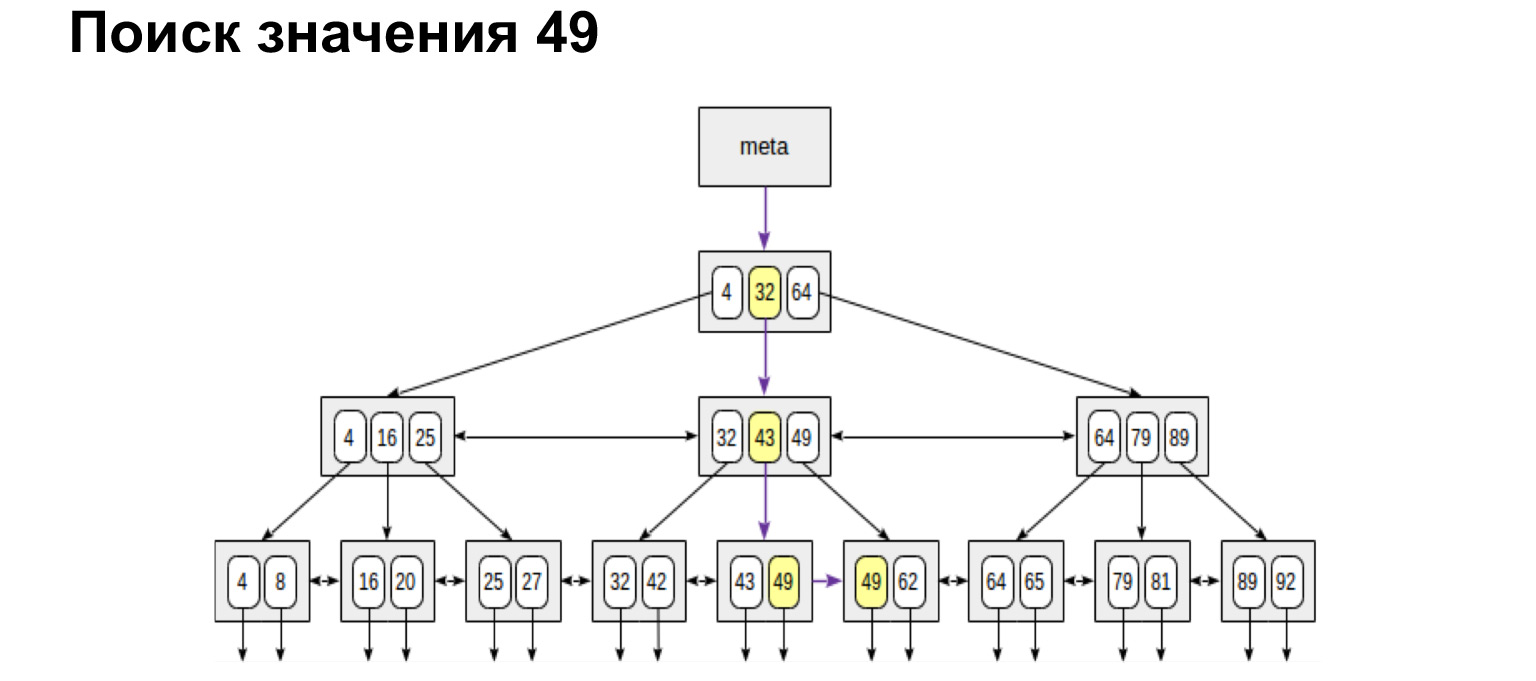
For example, we are looking for a value. It is very easy to search for one meaning. We go down the tree or to the left, to the right - depending on whether this value is greater or less.
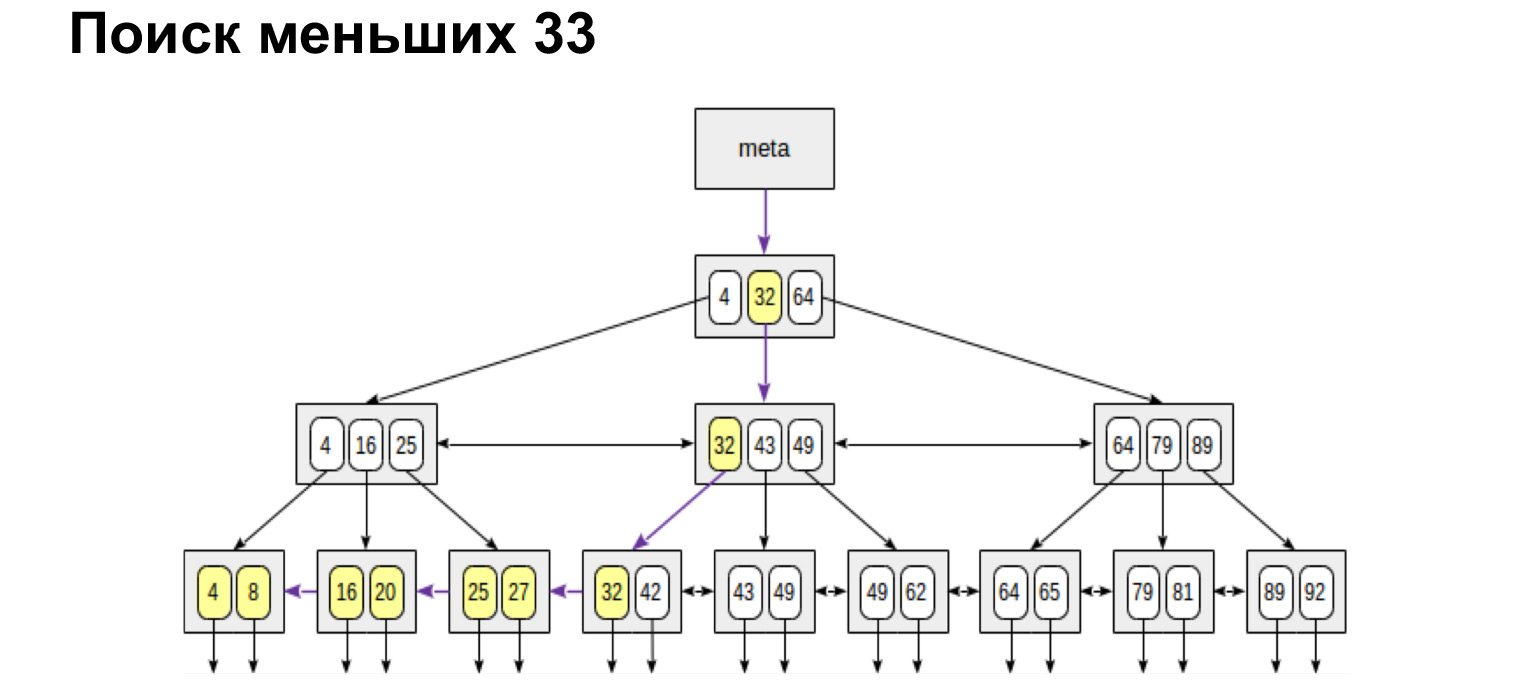
And if we want to find, for example, a range, then look how simple and fast it turns out. We reach the value and then follow the links in the leaves, already along the ordered values, just go to the end.
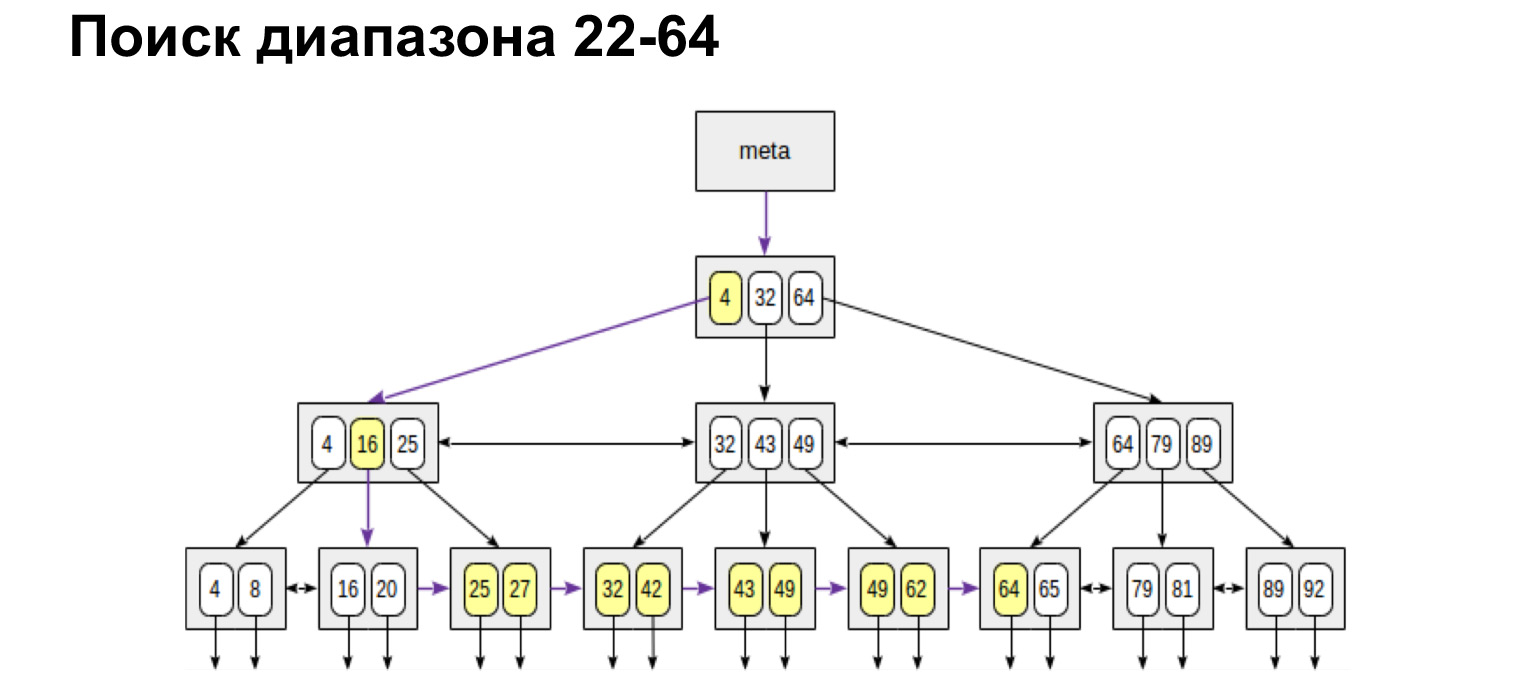
If we need a range defined from and to, we do exactly the same. Find the initial value and follow the leaf links to the maximum value. We walked the tree only once. It is very convenient, very fast.
In the same way, we will search for the maximum and minimum values. Walk completely left, completely right. We will also receive an ordered list. That is, if we just need to get all the chats in an ordered manner, we reach the first one and go through the leaves to the rightmost value, we get an ordered list. It is by this principle that the database very quickly searches in the index table for those rows that we need to select, and returns them.
What is important to know here? It would seem a cool structure - now we will build for each column according to such a tree and will search. Why do you think it won't work? Why won't we have a speed increase if we build a tree for each column? (...)
Our selections will really speed up. Every time when we need to go over some value, we go to the index, find there a link to the values themselves. Indexes usually contain exactly the references to the strings, not the strings themselves. And for select it works perfectly. But as soon as we want to set table data, update or delete data, then all these trees will have to be rebuilt.
In fact, deleting will not rebuild, but simply fragment this tree, and we will end up with many empty values. There will be a huge tree with empty values. But it is with update and with create that these trees will be rebuilt every time. As a result, we will get a huge overhead over all this structure. And instead of quickly fetching data and speeding up the database, we will slow down our queries.
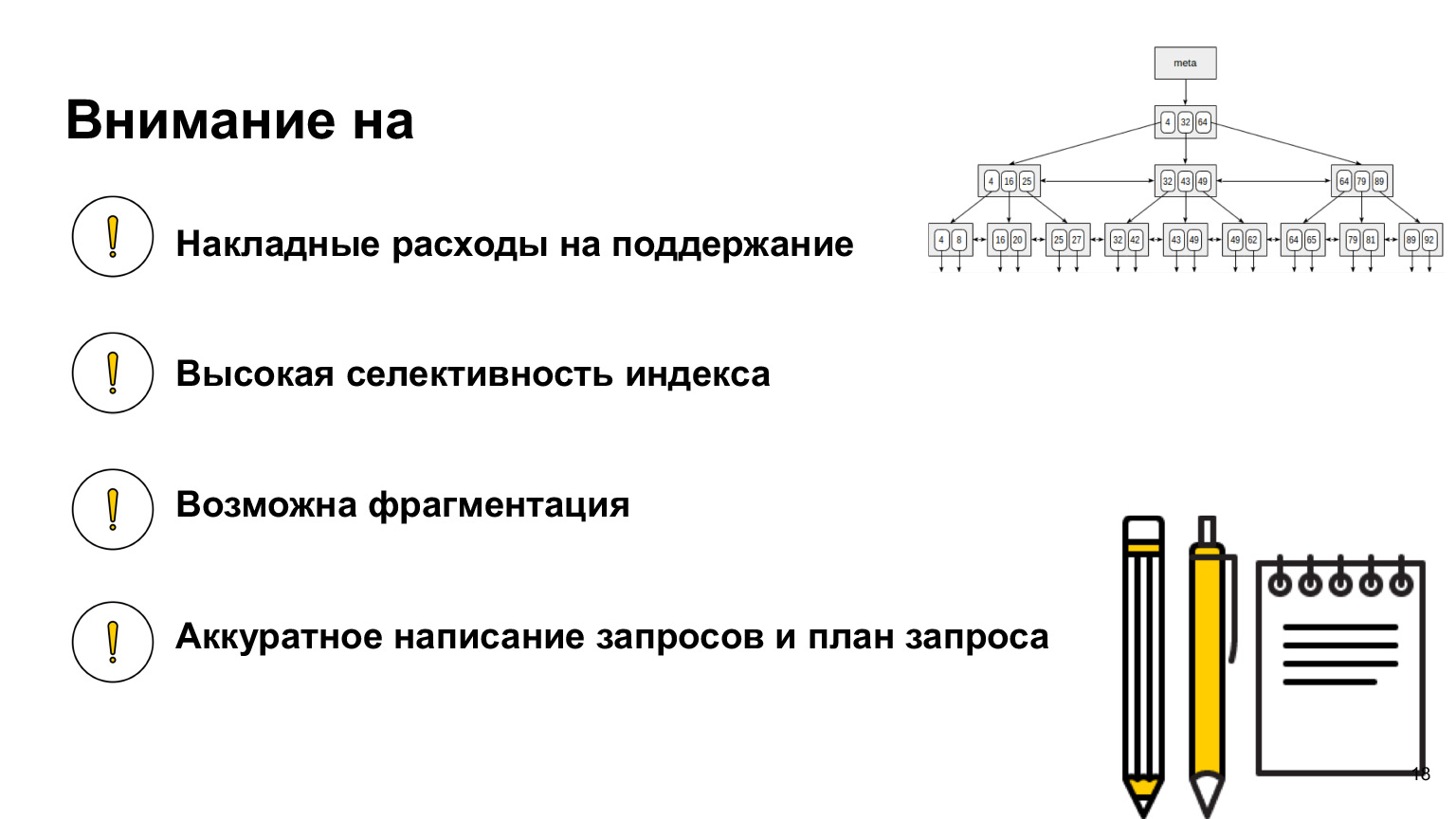
What else is important to know? When you work with a database, look, read, what indexes exist in it, because each database has its own implementations, its own different indexes. There are indexes to speed up, there are indexes to ensure integrity. One of the simplest is just the primary key. This is also a unique index. And regarding your database, see how it works, how to work with it, because this is the kind of knowledge that will help you write the most optimal queries.
We discussed what to keep in mind the overhead of maintaining indexes when inserting data. I forgot to say that when you build an index, it must be highly selective. What does it mean?
Let's look at this tree. We understand that if the index is set to true false, then we just get two huge pieces of wood on the left and right. And we go through 50% of the table at best, which is actually not very efficient. It is best to index exactly those columns with the most different values. This will speed up our selections.
I said about fragmentation; when deleting data, you need to keep it in mind. If we often have deletions on the data contained in the index, then it may need to be defragmented, and this also needs to be monitored. It is also important to understand that you are building an index not based on what columns you have, but on how you use that data. And queries that include indexes need to be written very carefully. What does neat mean? When you write a query, send it to the database, it is not sent directly to the database, but to a certain software layer called the query scheduler.
The scheduler has a certain correspondence table of how much the operation costs and how expensive it is. In the PostgreSQL example, there are special technical tables that collect information about your data, about your tables. The planner looks at what query you have, what data is stored in the pg_stat table. This is just a table that stores general information about how much data you have and what columns are in your table, what indexes are on it. Based on this, he looks at the plans for the execution of your query, calculates how much time according to which plan it will take for the query, and chooses the most optimal one.

If you want to see the predicted execution time for your query, you can use the Explain operation. If you want the actual execution, you can use Explain analyze. What's the difference? As I said, the scheduler initially calculates the execution time based on the estimated time for each operation. Therefore, the actual time may differ depending on the machine and the nature of your data. So if you want the actual execution, then of course it is better to use Explain analyze.
You can see an example on this slide. It shows that sometimes queries based on your column that have indexes may not use the scan index, but just full scan across the entire table. This happens if we have low index selectivity and if the planner thinks that a full scan query on the table will be more profitable.
Let's imagine that we have our messenger and we want in the chat list, for example, to show the chat name or the number of unread messages. If every time we open a chat, we recalculate all data for all chats, it will be very unprofitable.
There is such a thing - denormalization. This is a copying of the hottest data used or a pre-calculation of the required data and saving it to a table.
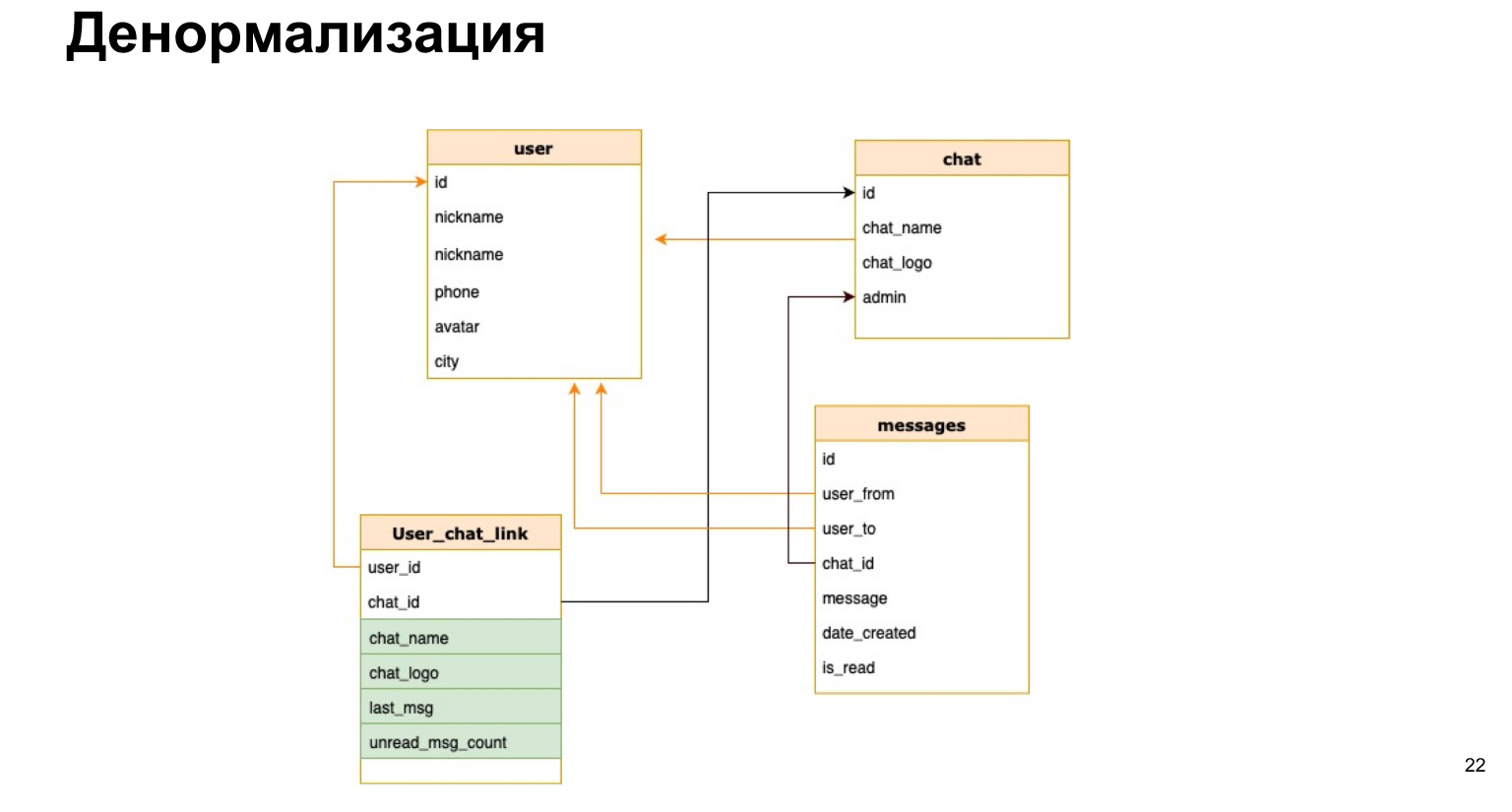
This is how the relationship between user and chat might look like. That is, in addition to the user ID and chat ID, we will briefly save the chat name, chat log and the number of unread messages there. Thus, every time we will not need to load all our tables, make selections and recalculate all this.

What is the plus of denormalization? We speed up the data sampling process. That is, our selections go through as quickly as possible, we give users an answer as quickly as possible.
The difficulty is that every time we add new data, we need to recalculate all these columns and the probability of error is very high. That is, if our selects become much simpler and we do not need to join all the time, then our update and create become very cumbersome, because we need to hang triggers there, recalculate and not forget anything.
Therefore, you should only use denormalization when you really need it. And as we now followed this whole logic, first you need to normalize the data, see how you will use it, adjust the indexes. If you have queries that you think are not performing well, take a look at Explain before denormalizing. Find out how they are actually performed, how the scheduler does them. And only then, when you have already come to the conclusion that denormalization is still needed, then you can do it. But there is such a practice, and data denormalization is often used in real projects.
Let's go further. Even if you structured the data well, chose a data model, collected it, denormalized everything, came up with indexes, still a lot in the IT world can go wrong.
Software may fail, power may go out, hardware or network may fail. There is also a second class of problems: a lot of users use our databases simultaneously. They can update the same data at the same time. We must be able to solve all these problems.
Let's take a look at specific examples of what this is about.

Let's imagine that there are two users who want to book a meeting room. User 1 sees that the meeting room is free at this time and begins to book it. His window opens, and he thinks which of my colleagues I will call. While he is thinking, user 2 also sees that the meeting room is free and opens an editing window for himself.
As a result, when user 1 saved this data, he left and thinks that everything is fine, the meeting room is booked. But at this time, user 2 overwrites his data, and it turns out that the chat room is assigned to user 2. This is called a data conflict. And we must be able to show these conflicts to people and somehow resolve them. It is in this place that we will have a rerecording.

How to do it? We can simply block the meeting room for a while while user 1 is thinking. If he saved the data, then we will not allow user 2 to do this. If he released the data and did not save, then user 2 will be able to book a conference room. You could see a similar picture when you buy cinema tickets. You are given 15 minutes to pay for the tickets, otherwise they are again provided to other people who can also take and pay for them.
Here's another example that will show us how important it is to ensure that our operations are carried out completely. Let's say I want to transfer money from bank account 1 to account 2. At this moment I have three operations. I check that I have enough funds, deduct funds from my first account and deposit them into the second account. It is clear that if at any of these moments I have a failure, then something will go wrong.
For example, if at this stage another transaction occurs that reads data, then the funds in my account will no longer be enough, I will not be able to perform other operations. If a problem occurs at the second moment, then we, for example, withdrew money from one account, but did not put money on the second. It turns out that as a result, my bank account, all my accounts, will be reduced by some amount. This money cannot be returned in any way.
To solve such problems, there is the concept of a transaction - an atomic, integral execution of all three operations simultaneously.
How does the database do it? It writes all these changes to a specific log and applies them only when our transaction is committed. Thus, we guarantee that all these operations will be performed as a whole or will not be performed at all.
If at any moment of this time we have a failure, then money will not be deducted from the first account and, accordingly, we will not lose it.
Transactions have four properties, four requirements for them. These are Atomicity, Consistency, Isolation and Durability - data atomicity, consistency, isolation and persistence. What are these properties?
- Atomicity or atomicity is a guarantee that the operation you are performing will be completed in full, that it will not be partially performed. Thus, we ensure that the overall consistency of the data in our database will be both before and after the operation.
- Consistency — -, . (Integrity). - , , Integrity Error, : , . . — , .
, , , , . . .
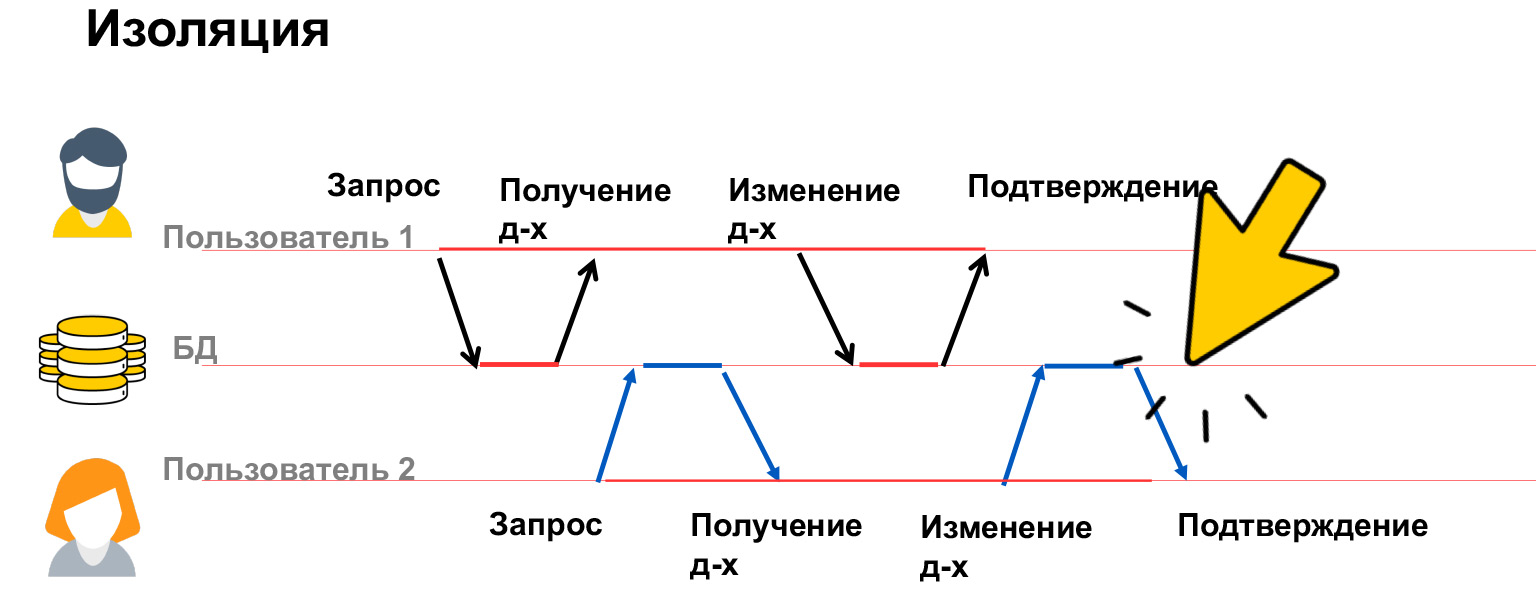
- Isolation — , . . , .
- Durability — , , , , .
Let's talk a little more about insulation. Isolation of transactions is a very expensive property, a lot of resources are spent on it, which is why we have several isolation levels in our databases. Let's see what problems can be, and based on this, we will already discuss how to solve them.
There are four main classes of problems - lost update, dirty read, nonrepeatable read, and ghost read. Let's take a closer look.
A lost update is like in the example with chat rooms, when user 1 has overwritten data and he does not know about it. That is, we did not block the data that this user changes, and, accordingly, received their overwriting.
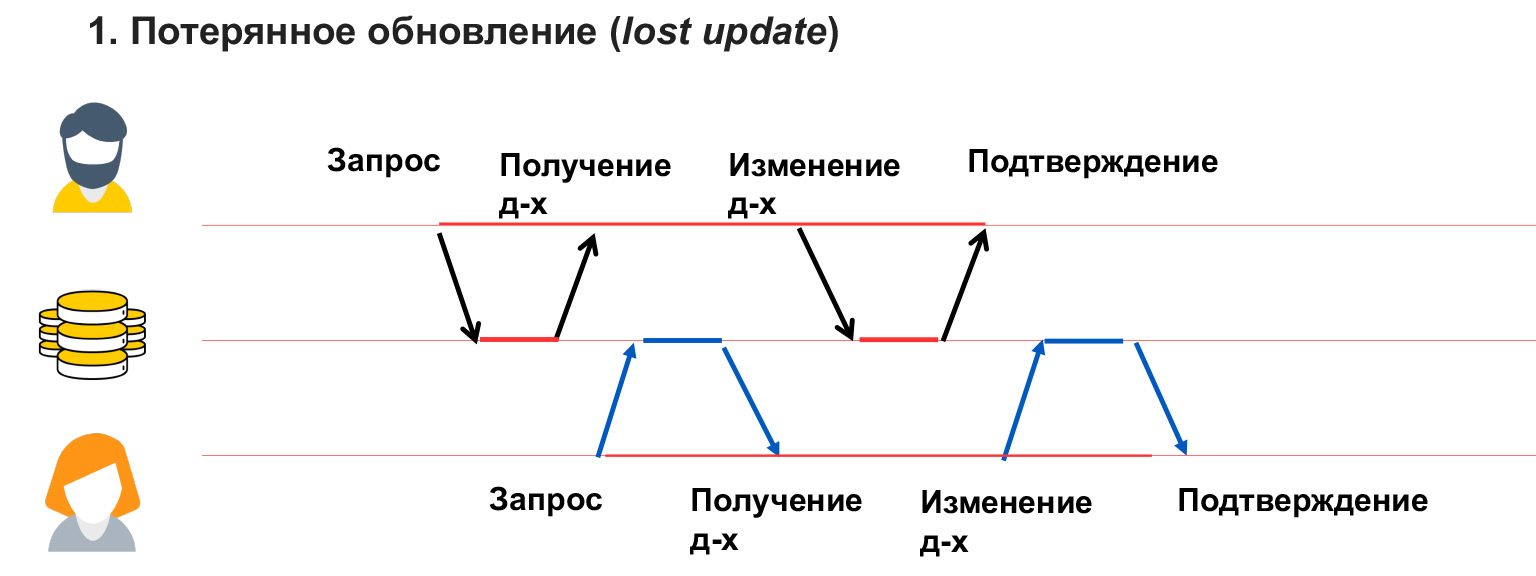
A dirty read problem occurs when a user sees temporary changes by another user, which can then be rolled back or simply made temporarily.

In this case, user 1 wrote something to the database. User 2 at this time was calculating something from there and building analytics on this data. And user 1 encountered an error, an inconsistency, and is rolling back this data. Thus, the analytics that user 2 wrote down will be fake, incorrect, because the data from which he calculated it is no longer there. You also need to be able to solve this problem.
A non-repeatable read is when we have a user with 1 long transaction. He fetches data from the database, and at this time user 2 changes part of the same data.
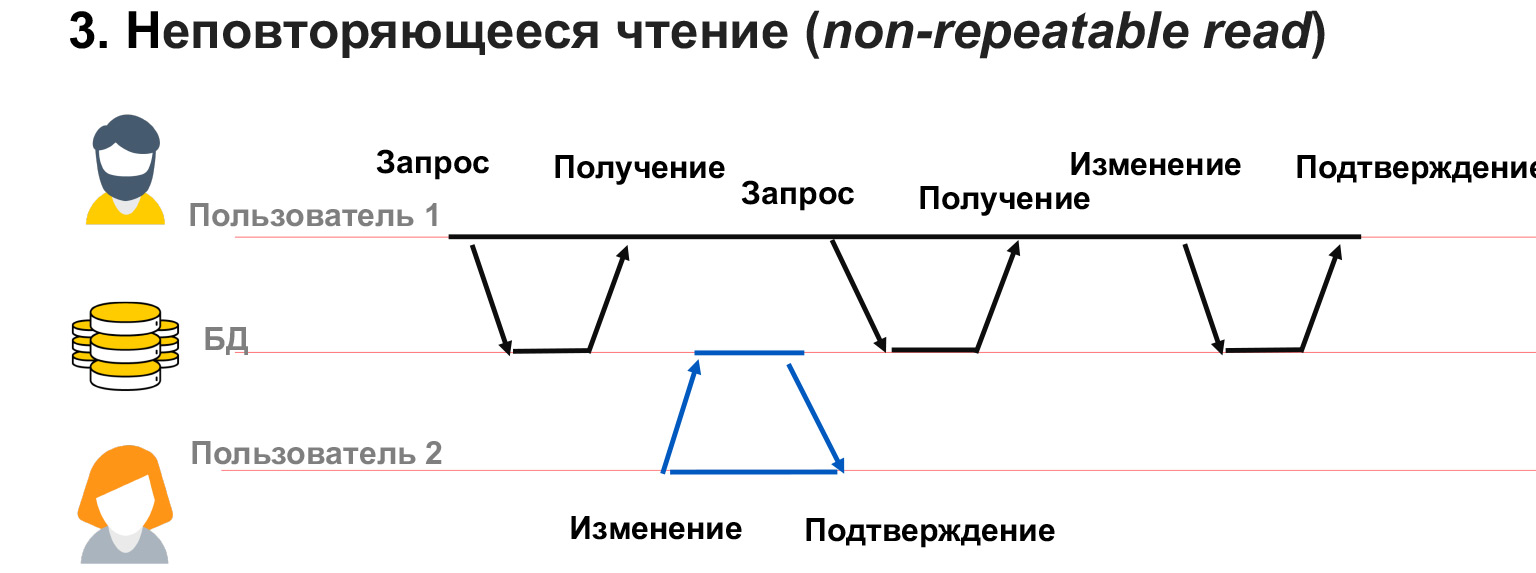
In this case, it turns out that user 1 has not blocked changes to the data that he has. And despite the fact that he himself got a snapshot of the data, when he is asked for the same select again, he can get different values in these lines. Thus, it will have a conflict, a mismatch in the data that it writes.

A similar problem can occur if user 2 has added or deleted data. That is, user 1 made a request, and then, after a second request for the same data, he had or disappeared rows. In this case, within the framework of a transaction, it is very difficult to understand what to do with them, how to process them at all.

To solve these problems, there are four isolation levels. The first and lowest level is Read uncommitted. This is what PostgreSQL describes as No lock. When we read or write data, we do not block other users from reading or writing that data. It turns out that we are not blocking any changes. All four of these problems can still occur. But what does this isolation level protect against? It ensures that all transactions that come to the database will be executed. If two users simultaneously started executing queries with the same data, then both of these transactions will be executed sequentially.
What is this useful for? This isolation level is very rarely used in practice, but it can be useful, for example, when there is a large analytical query and you want to read in the second query and see what stage your analyst is at, which data has already been recorded and which is not. And then the second request - which is for debugging, debugging, checking - you run just in this isolation level. And he sees all the changes in your first analytical request, which can eventually be rolled back. Or not rolled back, but at the current moment you can see the state of the system.

Read committed, read committed data. This isolation level is used by default in most relational databases, including PostgreSQL and Oracle. It ensures that you never read dirty data. That is, another transaction never sees the intermediate stages of the first transaction. The advantage is that it works very well for small, short queries. We guarantee that we will never have a situation where we see some parts of the data, incomplete data. For example, we increase the salary of an entire department and we do not see when only part of the people received an increase, and the second part is sitting with a non-indexed salary. Because if we have such a situation, it is logical that our analyst will immediately "go".
What does this isolation level not protect against? It does not protect against the fact that the data that you have selected can be changed. For small queries, this isolation level is sufficient, but for large, long queries, complex analytics, of course, you can use more complex levels that lock your tables.
The Repeatable read isolation level protects against the first three problems that we discussed with you. This and a lost update when we re-recorded our chat room; Dirty read - reading uncommitted data; and this nonrepeatable read - read data updated by other transactions.

How is it provided? By locking the table, that is, locking our select. When we take the select into our transaction, it looks like a snapshot of the data. And at this moment we do not see the changes of other users, all the time we work with this snapshot of data. The downside is that we block data and, accordingly, we have fewer parallel requests that can work with data. This is a very important aspect. And in general, why are there so many of these isolation levels?
The higher the level, the more blocks and fewer users who can work with the database in parallel. Each transaction sees a specific snapshot of the data that cannot be changed. But new data may appear. So this isolation level does not save us from the emergence of new data that are suitable for select.
There is one more isolation level - serialization. This is often referred to as ordering. This is a complete data lock on the table. It saves from phantom reading, that is, from reading just the data that we have added or deleted, because we lock the table, we do not allow writing to it. And we fulfill our requests holistically.

This is very useful for complex, large analytical queries where accuracy and data integrity are critical. It will not turn out that at some point we read the user's data, and then new statistics appeared in another table and it turned out to be out of sync.
This is the highest isolation level. It has the largest number of locks and the smallest possible parallelization of queries.
What you need to know about transactions? That they simplify our life, because they are implemented at the DBMS level and we only need to correctly make our queries, form them correctly, so that the data is eventually consistent. And to block exactly the data with which our users work. It should be borne in mind that it is bad to block everything, everywhere. Depending on what system you have and who reads / writes how much, you will have a different level of isolation. If you want the fastest possible system that makes some mistakes, you can choose the minimum isolation level. If you have a banking system that must ensure that the data is consistent, everything is done and nothing is lost - then, of course, you need to choose the maximum isolation level.
We've already made some pretty good progress in understanding how to structure the database and what can happen. Let's go further.
How secure is it to store one database. Certainly not safe. If something happens to her, we lose all data. If there is a backup, we can roll it, but then there will be system downtime. If our network breaks down or the node becomes unavailable, the system will also be idle for some time, in downtime.
How can this be resolved? There is such a concept - replication. This is duplication of the database to other nodes and servers.

This is exactly a complete duplication, a copy of the database. How can we use this mechanism?
First, if something happened to the database, we can redirect requests to another copy of the database, which is logical in principle. This is the main application. How else can we use this?
Let's imagine that the user is far from the server. We can distribute servers in such a way as to cover the maximum number of users and give them requests as quickly as possible. Each of these servers will have the same copy as the others, but requests will return to users faster.

Another very popular use is load balancing. Since we have identical copies of the data, we can read not from our head, not from one database, but from different ones. Thus, we offload our server.

We also have the concept of OLTP queries and OLAP queries. What it is? OLTP - short transactional queries. OLAP is long-term analytics. This is when we take a huge join, a huge select, we merge everything and it is very important for us that at this moment all data is locked, so that there are no changes and the database is complete.
For such situations, you can do analytics on a separate copy of the database. So we will not affect our users, they can also make entries in the database, just then these entries will come to our copy.
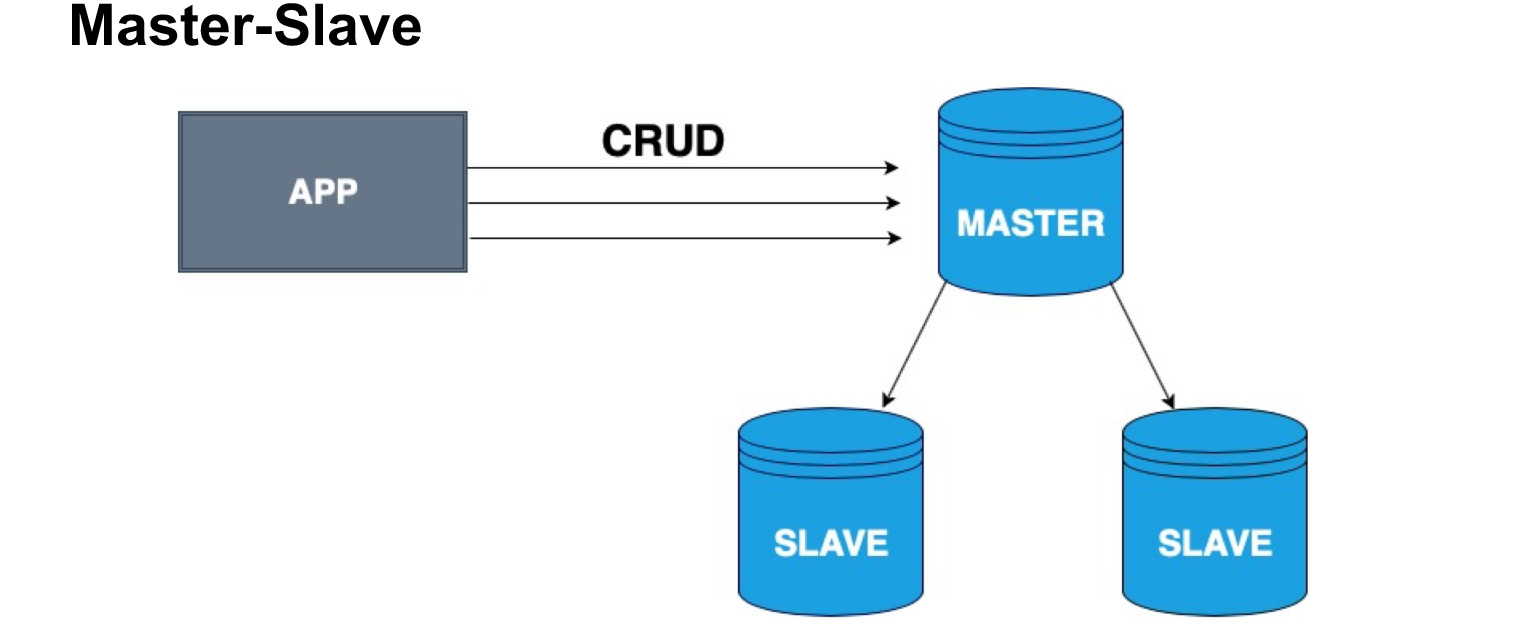
In order to correctly distribute copies of databases, the concept of a master node and a slave node, Master and Slave, is introduced. Slave is very often called a replica or follower. Master - the node to which our user, our application writes. The Master applies all changes, keeps a log of changes, and sends this log to the Slave. Slave does not accept changes from users, but only applies changes to the log from Master. Please note that Master does not send a copy every time, but sends changes. The slave rolls over these changes and receives the same copy of the data as in the Master.
A very important parameter of the replicated system is that requests are executed synchronously or asynchronously. What is a Synchronous Request? This is when the Master sends a request to a synchronous replica, to a synchronous Slave, and waits for the Slave to say: "Yes, I accepted" - and the Master returns confirmation. Only then will the Master return the answer to the user. If the replica is asynchronous, then the Master sends a request to the replica, but immediately tells the user that "That's it, I wrote it down." Let's see how it works.
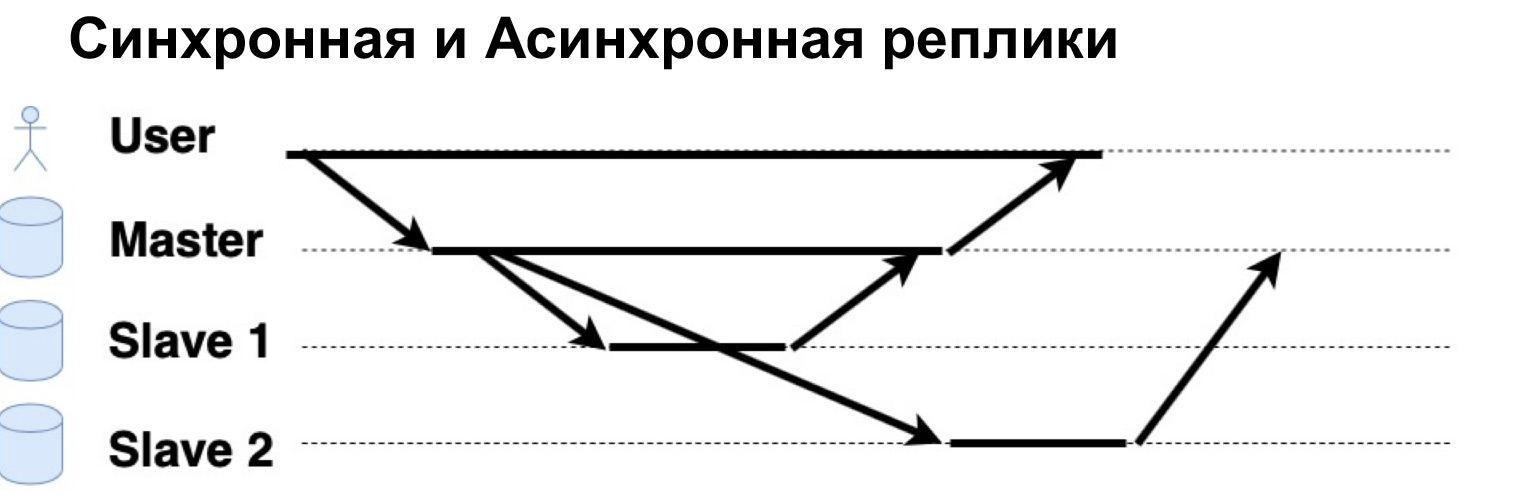
There is a user who has written data to Master. Master sent them to two replicas, waited for a response from a synchronous replica and immediately gave an answer to the user. An asynchronous replica recorded and said to the Master: "Yes, it's okay, the data is written."
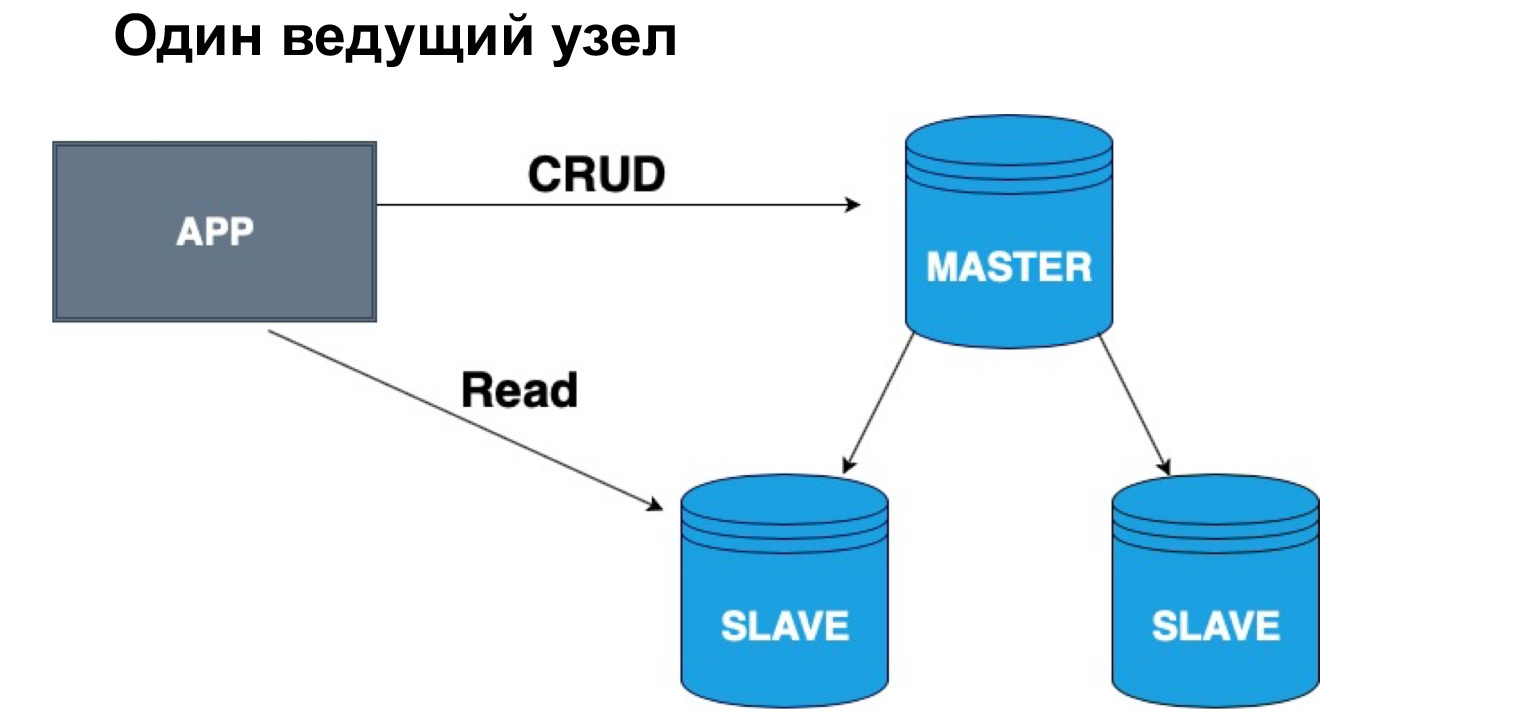
In terms of such a hierarchy, Master and Slave, we can have one head or several. If we have one master node, it is very convenient to write to it, but you can read from a synchronous replica. Why exactly from synchronous? Because a synchronous replica ensures that the data is up to date with maximum accuracy.
When a query is applied to data, an operation from the log, it also takes time. Therefore, if one hundred percent accuracy of the data that you want to receive is important to you, you should go for reading, for a select in the Master. If you are not critical that the data may arrive with a slight delay, you can read from the synchronous Slave. If you are absolutely not critical of the relevance of the data, you can read, including from the asynchronous replica, thereby unloading the Master and the synchronous replica from requests.
Replication can also have multiple masters. Different applications can write to different heads, and these Master then resolve conflicts with each other.
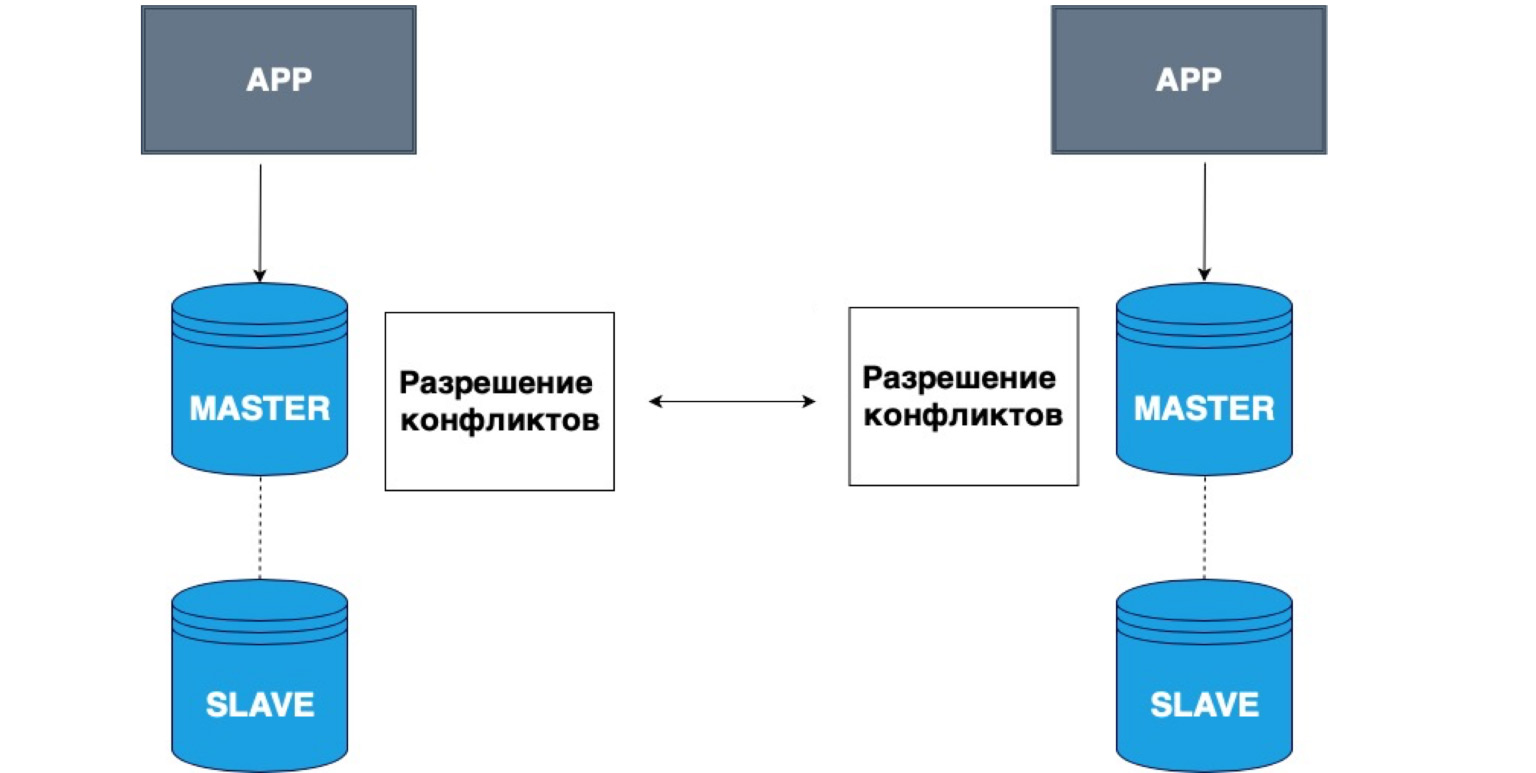
A very simple example of using such data is all sorts of offline applications. For example, you have a calendar on your phone. You have disconnected from the network and recorded an event in the calendar. In this case, your local storage, your phone, is Master. It has stored the data in itself, and when the Master network appears, your local copy and the copy on the server will resolve conflicts and combine this data.
This is a very simple example of such replication. It is often used for collaborative editing of online documents, or when there is a very high probability of losing the network.
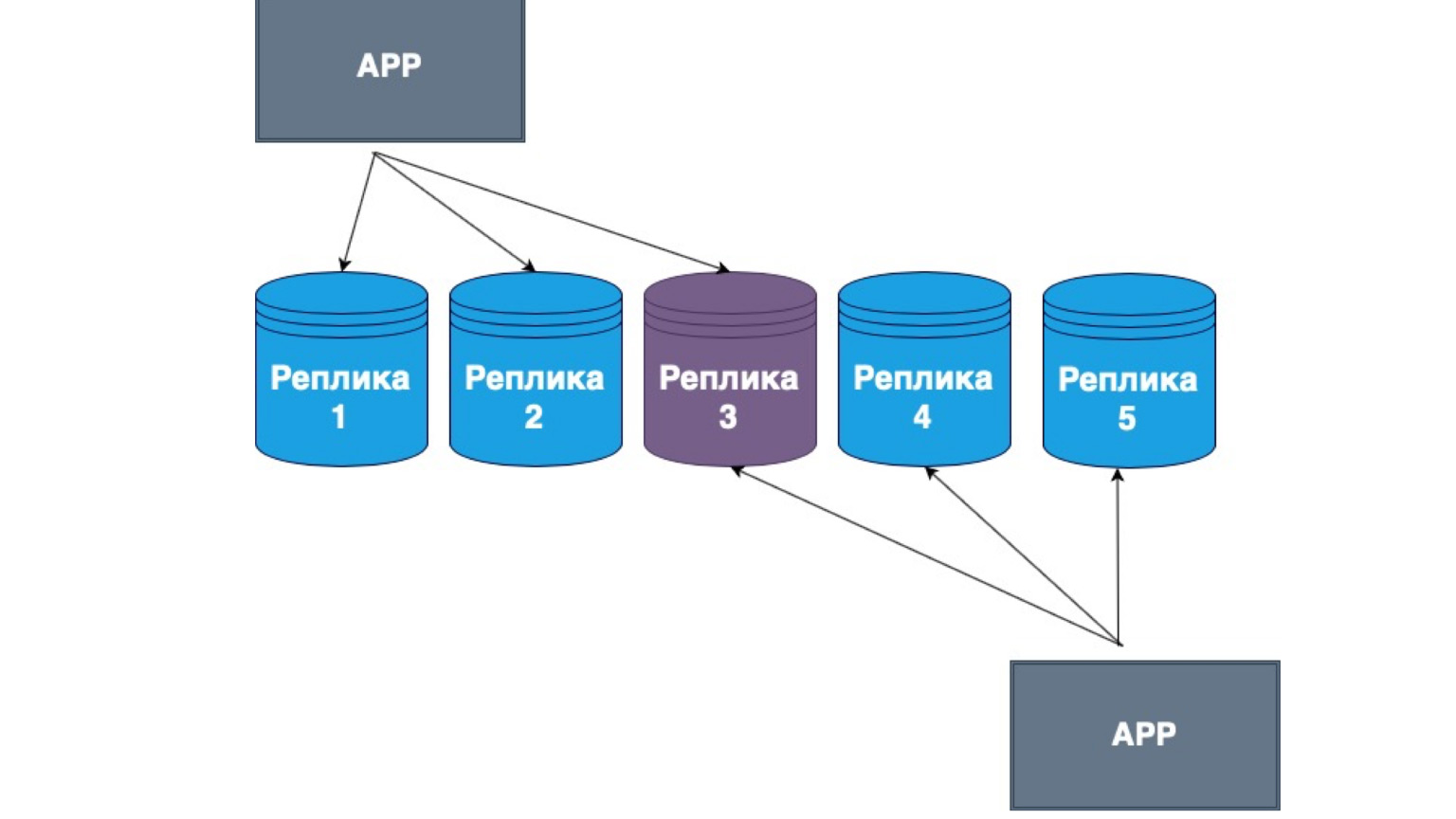
Masterless replications also exist. What it is? This is replication, in which the client himself sends data to most of the replicas and reads it from most of the replicas too. Here you can see that our middle replica is the intersection of our Read and update.
That is, we guarantee that every time we read the data, we will get into at least one of the replicas, in which the data is most relevant. And among themselves, the replicas build a mechanism for exchanging information with the main log of changes and conflicts between replicas. In this case, it is very often the fat client that is implemented. If he received data from a replica that contains more recent changes than another, then he simply sends the data to another replica or resolves the conflict.

What is important to know about replication? The main point of replication is system fault tolerance, high availability of your server. Whatever happens to the database, the system will be available, your users will be able to write data, and when the connection with the Master or with another replica is restored, all data will also be restored.
Replication is very helpful in offloading servers and redistributing read requests from Master to replicas. We can scale this read, create more read replicas and make our system even faster. You can also replicate complex, long-term analytical queries that require a large number of locks and can affect system availability.
Using offline applications as an example, we looked at how you can store such data and resolve conflicts. In the case of a synchronous replica, there may be a Replication lag, that is, a time lag. In the case of an asynchronous replica, it is almost always there. That is, when you read data from an asynchronous replica, you must understand that it may not be relevant.
According to the hierarchy, I forgot to say that when there is one Master that is waiting for a response from a synchronous replica, it is logical to assume that if all replicas are synchronous, and one suddenly becomes unavailable, then our system will not be able to save the request. Then the Master will write us to the first synchronous Slave, receive a response, ask for the second Slave, receive no response, and eventually have to roll back the entire transaction.
Therefore, in such systems, as a rule, one replica is made synchronous, and the rest asynchronous. Synchronous replica ensures that your data is saved somewhere else. That is, in addition to the Master, with which something can happen, we guarantee that there is at least one more node that contains a complete copy of exactly the same transaction log, the same data.
Asynchronous replica, on the other hand, does not guarantee data integrity. If we have only asynchronous replicas and the Master has disconnected, then they may lag behind, the data may not have arrived there yet. In such cases, as a rule, they build such a hierarchy that either we have a Master, one synchronous replica and the rest are asynchronous, or we have a Master and all replicas are asynchronous, if data persistence is not important to us.
There is one "but": all replicas must have the same configuration. If we talk about PostgreSQL as an example, they must have the same version of PostgreSQL itself, because different versions of the database can have different log formats. And if the replica comes up from a different version, it simply may not read the operations that the other base wrote.
What is a replica? This is a complete copy of all data. Let's say there is so much data that the server cannot handle it. What's the first solution?
The first decision is to buy a more expensive machine with more memory, with a larger CPU, with a larger disk. This decision will be correct for the most part, as long as you do not face the problem of the high cost of iron. One day it will be too expensive to buy a new car, or there will simply be nowhere to grow. There is a huge amount of data that is simply physically impossible to fit on one machine.
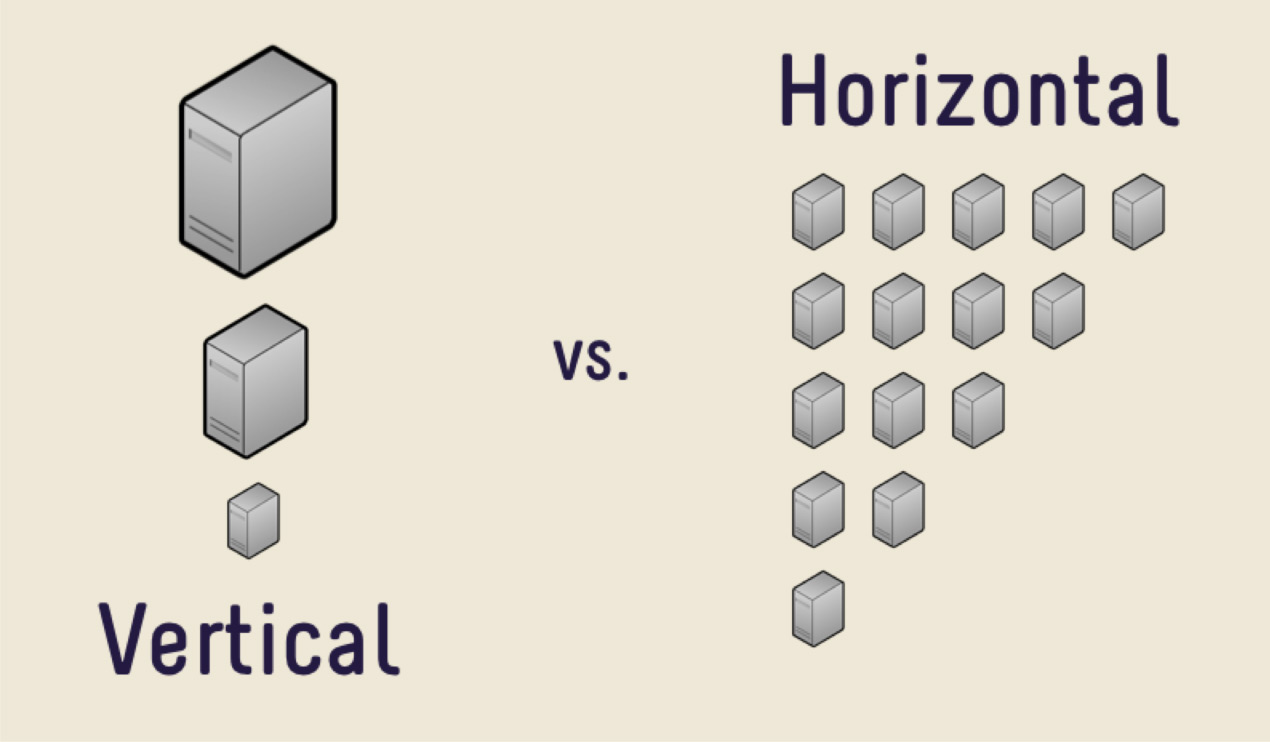
In such cases, you can use horizontal scaling. What we saw earlier, the increase in performance per machine, is vertical scaling. The increase in the number of machines is horizontal scaling.
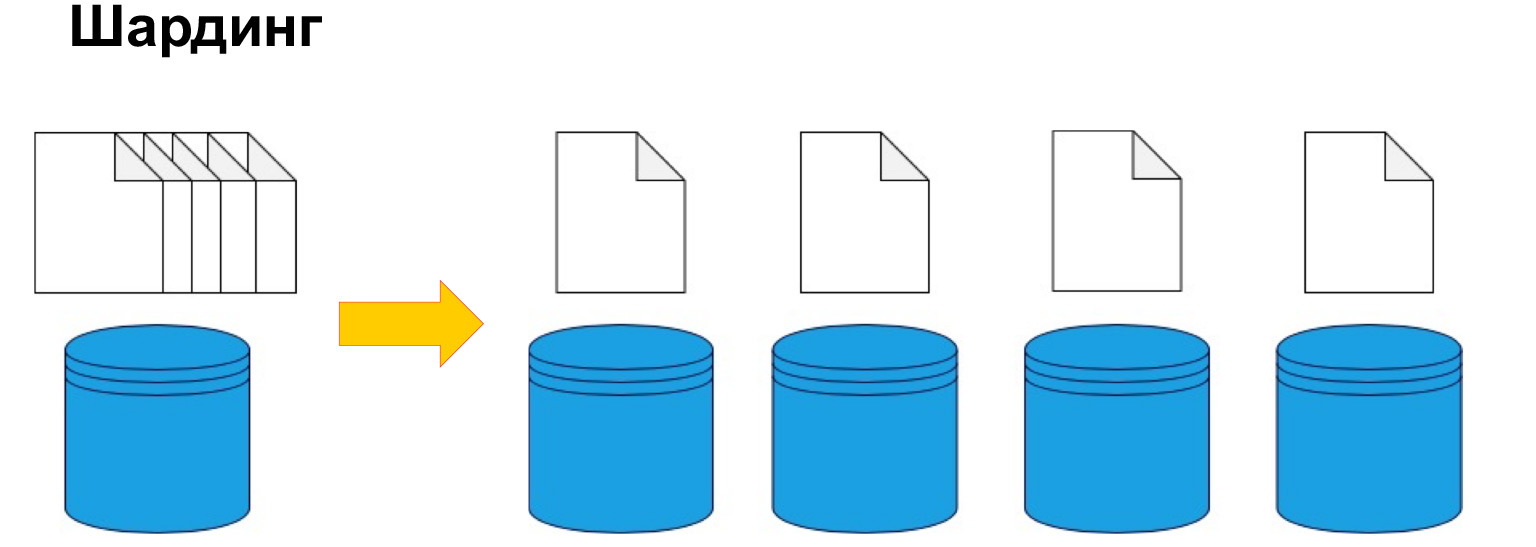
To split data by machine, sharding or, in other words, partitioning is used. That is, splitting data into sections and blocks by key, by ID, by date. We will talk about this further, this is one of the key parameters, but the point is precisely to divide the data according to a certain criterion and send it to different machines. Thus, our machines may become less efficient, but the system can still function and receive data from different machines.
In order to generally understand where what data is, you need a certain correspondence table of the shard, our copy and data.
There are times when a special data store is not used and the client simply walks in turn to each shard and checks if there is data that matches his request.
There is a special software layer that stores certain knowledge about which shard is in which data range. And, accordingly, it goes exactly there, to the very node where the necessary data is located.

There is a fat client. This is when we do not sew the client himself into a separate layer, but we sew into him the data on how our data is sharded.
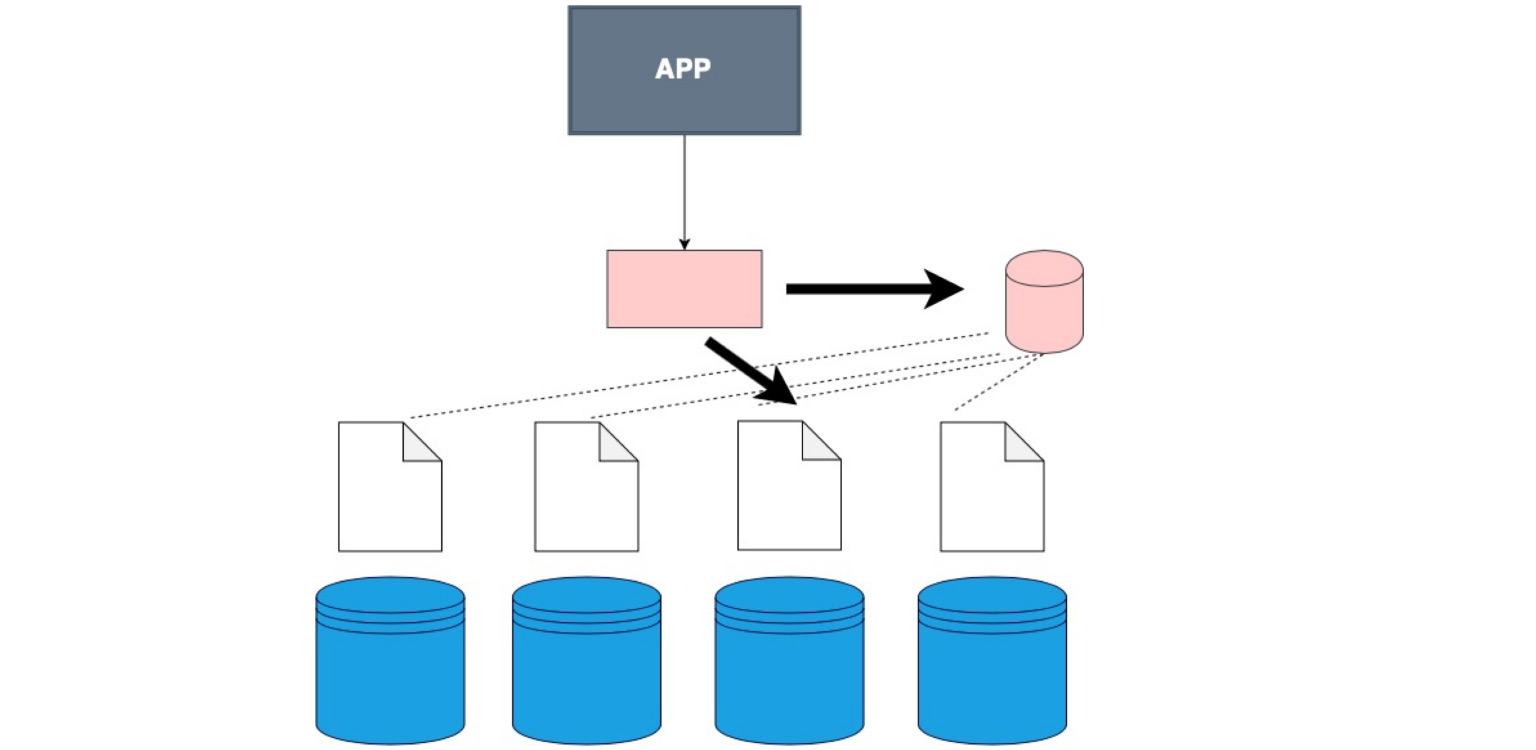
This is the case. By the way, it is the most used one. The good thing is that our application, our client, even the code that you write, does not know that the table is sharded, although we indicate this in the config, in the database itself. We just tell her - select, and already in the database itself, there is a division into shards and an understanding of where to select from. Here, in the code itself, you define where to read the data from.
There are special services that help to structure and generally update information. It is difficult to keep it consistent and relevant. We have selected something, recorded new data. Or something has changed and we need to route our requests very correctly. There are special services for coordinating requests. One of them is Zookeper. You can see how they work in general. A very interesting structure. They saved a lot of nerves and time for developers.
What's important, what aspects to keep in mind when you partition? It is important to understand what key we will use for sharding. Re-collecting all this data is quite expensive, so it is very important not to be mistaken about how the data will potentially be used in the future. If we did sharding well and correctly, then with the most frequently used queries we will always know which replica to go to.
For example, if we, according to the user's IDs, store all their data on certain replicas, then we understand that we can come to this one replica and do all the joins on it. But keeping it by ID is not the coolest idea. Now I'll tell you why.
If we incorrectly identified the key in partitioning, if we have a very complex query, then we really have to go to different shards, combine all the data and only then give it to the application. Fortunately, most DBMSs do this for us. But what kind of overhead would come under poorly written queries? Or under sharding, which is broken on the wrong node?
About IDs. If the system works only with new users and we have an increase in IDs, then all requests will go to the last node.
What happens? The other three running machines will stand idle. And this car will simply burn - the so-called hot spot. This is the bottleneck of your potential system, the place that may even refuse connections.
Therefore, when we define the sharding key, it is very important to understand how balanced these nodes will be. Hashes are used very often, this is a more or less neutral, balanced arrangement of data. But if you have a hash function on a key, then you will not be able to select, for example, by ranges. It is logical, because the ranges cannot be spread out into different shards.
By date - the same. If, for example, we scatter analytics and make shards by date, then, of course, any one shard ten years ago will not be used at all. It is not profitable for us. And it is always very expensive to rebuild the data and overharden.
I will answer the question that came before. Is it better to define indices or make shards? Indices, of course.
Look, shards are separate machines with a whole raised infrastructure. And this middle component contains something akin to indexes. There is a quick search by parameters - where, where to go. Here is the ratio. But if there is sharding, the final picture will be like this:

There are applications, some kind of head that knows where to go. And there are shards, on each of which a replica is configured. This is a really big overhead if there is not much data. That is, you only need to resort to sharding when you really have reached the vertical scaling limit, when buying a more expensive machine is not relevant to your data or income. Then you can buy several different, cheaper cars and build such an architecture on them.
What replicas are for, I think, is clear: because shards are broken, they are pieces of databases, but they are kind of unique. They are found only in these places. We also break them down into copies, which make our nodes fault-tolerant and insure against problems.

The most important thing: sharding is used exactly where you do not just want to break the data into classification, but exactly where there is really a lot of data.
Now let's get more into data models and see how data can be stored.
The relational databases that we looked at before have a huge number of advantages, because, first of all, they are very common and understandable to everyone. They visually show the relationship between objects and provide integrity.
But there is a downside: they require a clear structure. There is a table in which we must push all the data. If you look at all the information and facts that we collect in general, they are very different. That is, we can work with product data, with user data, messages, and so on. This data really requires a clear structure and integrity. A relational database is ideal for them.
But suppose we have, for example, a log of operations or a description of objects, where each object has different characteristics. We, of course, can write this down to a jason in a relational database and be glad that we have it growing endlessly.
And we can look at other schemes, at other storage systems. NoSQL is a very flashy abbreviation, even directly provocative - "no SQL". How did it come about?
When people were faced with the fact that relational databases were not successful everywhere, they put together a conference that needed a hashtag, and so they came up with #NoSQL. It took root. Later they began to say not “no SQL”, but “not only SQL”. It's just anything that isn't relational: a huge family of different databases that are not as rigidly structured, schematic, and tabular as relational databases.
The family of non-relational data models is divided into four types: key-value, document-oriented, columnar and graph databases. Let's consider each of these points, find out which data is better to store in which of them and what they are used for.

Key-value. This is the simplest. Here is the dictionary, here is the ratio. This is a database in which data is stored by keys, and it does not matter what is under a particular key. We have both the key itself and the data can be both simple and much more complex structures. The good thing about such a database is that, like an index, it searches for data very quickly. This is why key-value is very often used for cache. The advantage is that our value can be different in different keys.
We can use the key, for example, to store user sessions. The user clicked, we wrote this in value. It is a schemaless, a data model without a specific schema, value structure. Because it is a very simple structure, it is fast and easy to scale. We already have the keys, and we can very easily shard them, make their hashes. It is one of the most highly scalable databases.
Examples are Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. You can see the implementation features of key-value storages.

Document databases are very similar to key-value in some of their uses. But their unit is a document. This is such a complex structure by which we can select certain data, do bulk operations: Bulk insert, Bulk update.
Each document can store in itself, as a rule, XML, JSON or BSON - binary-stored JSON. But now it is almost always JSON or BSON. This is also like a key-value pair, you can imagine it as a table in which each row has certain characteristics, and we can get something from it using these keys.
The advantage of document-oriented databases is that they have very high data availability and flexibility. In any document, in any JSON, you can write absolutely any set of data. And they are very often used - for example, when you need to create a catalog and when each product in the catalog can have different characteristics.
Or, for example, user profiles. Someone indicated their favorite movie, someone - their favorite food. In order not to stick everything in one field, which will store it is not clear what, we can write everything in JSON of a document base.
Another convenient model for storing data is columnar databases. They are also called columnar, column database.

This is a very interesting structure that is used, as it seems to me, in almost all large and complex projects. Such a database implies that we store data on disk not in lines, but in columns. Used for very fast searches over a huge amount of data. As a rule - for analytics, when you need to select values only from certain columns.
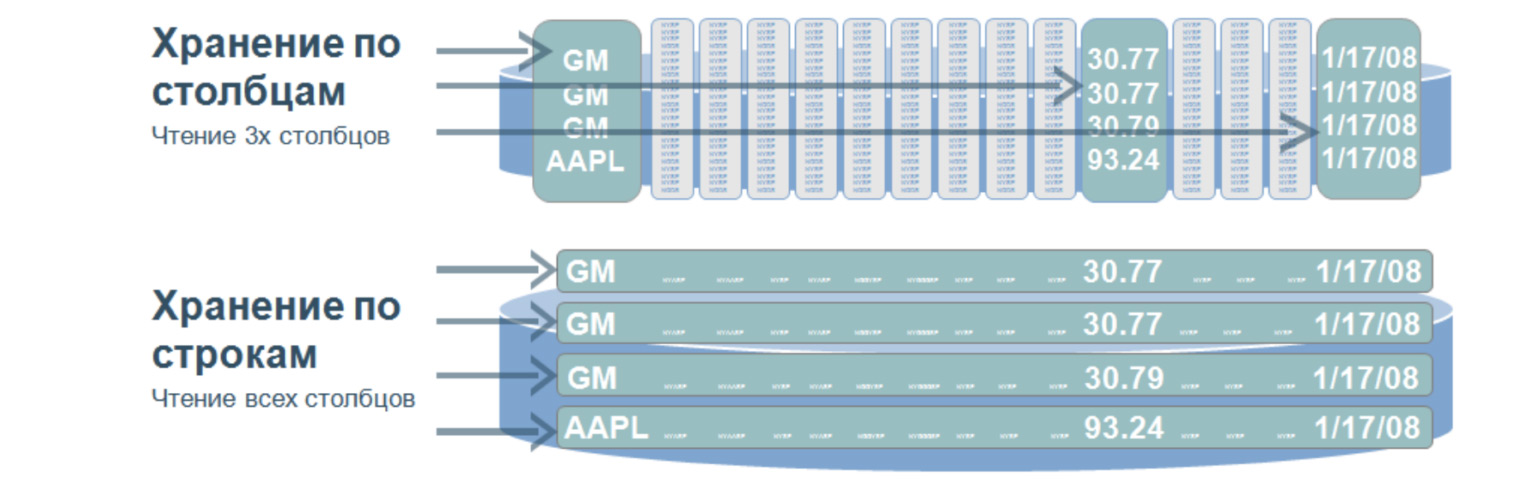
Let's imagine we have a huge table. And if we stored data in lines, then it would be what is below: a huge number of lines. To select even three parameters of this table, we need to go through the entire table. And when we store values by columns, then when selecting by three values, we need to go through only three such, roughly speaking, lines, because our columns are written like this. Passing through these three lines, we immediately get the ordinal number of the value we need and get it from the other columns.
What is the advantage of such databases? Due to the fact that they search for a small amount of data, they have a very high query processing speed and great data flexibility, because we can add any number of columns without changing the structure. Here, not like in relational databases, we do not need to force our data into certain frames.
The most popular columnar ones are probably Cassandra, HBase, and ClickHouse. Test them. It's very interesting to invert the ratio of rows and columns in your head. And this is really efficient and fast access to large amounts of data.

There is also a family of graph databases. They also contain nodes and edges. Edges are used to show relationships, just like in relational databases. But graph bases can grow infinitely in different directions. Therefore, it is more flexible. It has a very high search speed, because there is no need to select and join across all tables. Our node immediately has edges that show the relationship to all different objects.
What are these databases used for? Most often - just to show the relationship. For example, in social networks, you can answer the question of who is following whom. We immediately have links to all the followers of the right person. Still very often, these databases are used to identify fraud schemes, because this is also associated with demonstrating the relationship of transactions with each other. For example, you can track when the same bank card was used in another city or when from the same IP address they entered the account of some other user.
It is these complex relationships that help resolve unusual situations that are often used to analyze such interactions and relationships.
Non-relational databases do not replace relational databases. They are just different. Different data format and different logic of their work, no worse and no better. It's just a different approach to other data. And yes, non-relational databases are used a lot. You don't need to be afraid of them; on the contrary, you need to try them.
If you make a cache, then, of course, take some kind of Redis, a simple and fast key-value. If you have a huge number of logs for analysis, you can drop it into ClickHouse or into some columnar base, which will then be very convenient to search. Or write it to the document base, because there may be different meanings of documents. This can also be useful for selection.
Choose a data model based on what data you will be using. Either relational or non-relational. Describe the data. This way you can find the most suitable storage that you can scale in the future.

Today you have learned a lot about various problems and ways of storing data. I will repeat once again what I said at the very beginning: you don’t need to know everything in detail, you don’t need to delve into one thing. If you're interested, of course you can. But it is important to know that it exists in general, what approaches are there and how you can think in general. If you need fault tolerance, it makes sense to make a replica. Suppose I wrote down the data, but did not see it. Then, probably, my remark gave a lag. There is no need to reinvent the wheel - there are already many ready-made solutions for different tasks. Broaden your horizons, and if a bug or some other problem appears, you will understand exactly where the failure occurred by the characteristics of the bug, and you can find a solution through the search engine. Thank you for attention.